




 本文深入解析了K-means聚类算法的工作原理及其在数据科学中的应用。阐述了如何通过迭代过程寻找最佳聚类中心,以实现数据点的高效聚类。介绍了算法的步骤,包括初始化质心、分配数据点、更新质心,直至算法收敛。
本文深入解析了K-means聚类算法的工作原理及其在数据科学中的应用。阐述了如何通过迭代过程寻找最佳聚类中心,以实现数据点的高效聚类。介绍了算法的步骤,包括初始化质心、分配数据点、更新质心,直至算法收敛。
K-means算法
K-means算法是很典型的基于距离的聚类算法,算法采用误差平方和准则函数作为聚类准则函数,也是典型的基于原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。K-means算法以欧式距离作为相似度测度,它是求对应某一初始聚类中心向量V最优分类,使得评价指标J最小。采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
k个初始类聚类中心点的选取对聚类结果具有较大的
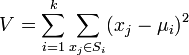 公式影响,因为在该算法第一步中是随机的选取任意k个对象作为初始聚类的中心,初始地代表一个簇。该算法在每次迭代中对数据集中剩余的每个对象,根据其与各个簇中心的距离将每个对象重新赋给最近的簇。当考察完所有数据对象后,一次迭代运算完成,新的聚类中心被计算出来。如果在一次迭代前后,J的值没有发生变化,说明算法已经收敛。
公式影响,因为在该算法第一步中是随机的选取任意k个对象作为初始聚类的中心,初始地代表一个簇。该算法在每次迭代中对数据集中剩余的每个对象,根据其与各个簇中心的距离将每个对象重新赋给最近的簇。当考察完所有数据对象后,一次迭代运算完成,新的聚类中心被计算出来。如果在一次迭代前后,J的值没有发生变化,说明算法已经收敛。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5514
5514




 到【灌水乐园】发言
到【灌水乐园】发言







