




 本文介绍了编码器-解码器模型在处理不定长序列问题中的关键组件,如编码器的输入转换、解码器的条件概率生成,以及注意力机制在提高翻译质量和语言模型性能中的作用。还讨论了贪婪搜索和束搜索策略,以及机器翻译中的特殊符号和评价方法,如BLEU和困惑度。
本文介绍了编码器-解码器模型在处理不定长序列问题中的关键组件,如编码器的输入转换、解码器的条件概率生成,以及注意力机制在提高翻译质量和语言模型性能中的作用。还讨论了贪婪搜索和束搜索策略,以及机器翻译中的特殊符号和评价方法,如BLEU和困惑度。
1. 背景
encoder-decoder和seq-seq模型可以解决输入与输出都是不定长序列的问题。它们都用到了两个循环NN,分别叫做编码器(用来分析输入序列)与解码器(用来生成输出序列)。
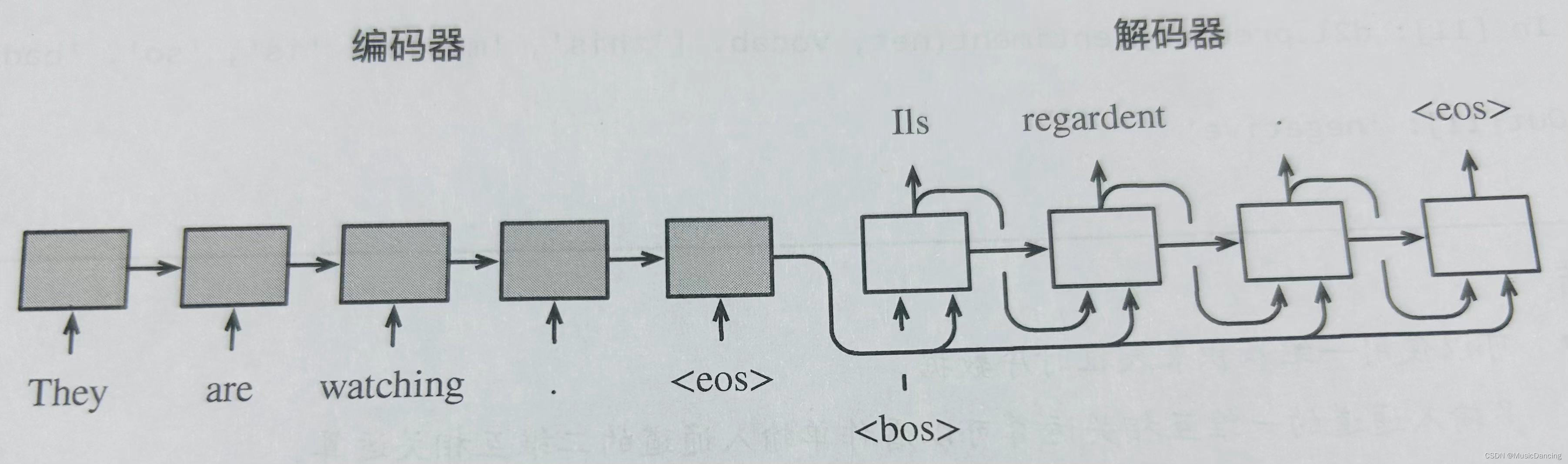
在encoder-decoder的训练中,可以采用强制教学(teacher forcing),使用将标签序列在上一个时间步的标签作为decoder在当前时间步的输入。
2. 编码器
把一个不定长的输入序列变换成一个定长的背景变量c,并在其中编码输入序列信息。encoder通过自定义函数q将各个时间步的隐藏状态变换为背景变量
3. 解码器
decoder输出基于之前的输出序列和背景变量c的条件概率。
4. 贪婪搜索(greedy search)
贪婪搜索的主要问题是不能保证得到最优输出序列(条件概率最大的输出序列)。束搜索是对贪婪搜索的改进,它通过灵活的束宽来权衡计算开销和搜索质量。
5. 注意力机制
decoder的每一时间步对输入序列中不同时间步的表征或编码信息分配不同的注意力。
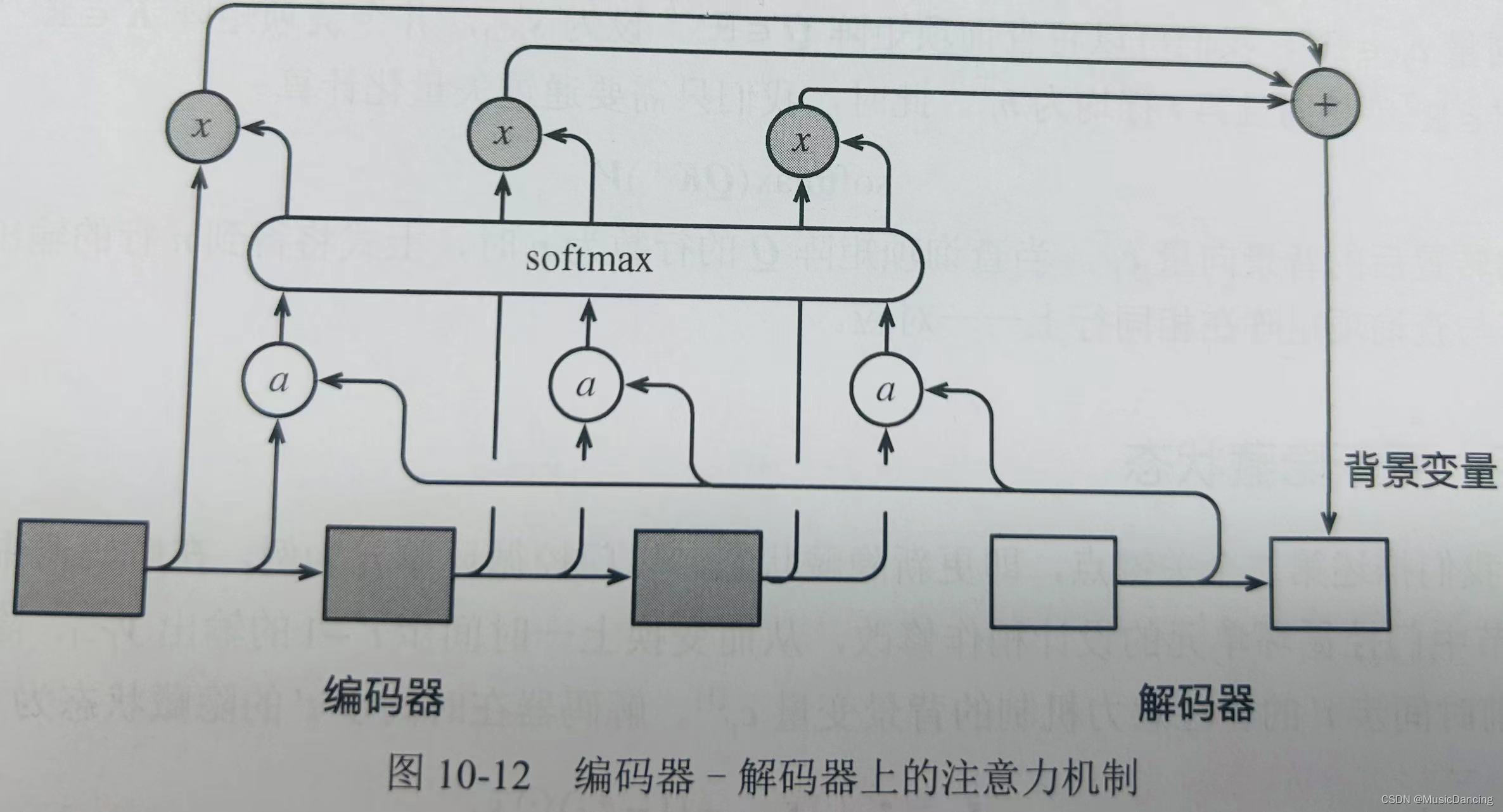
attention机制通过对encoder所有时间步的隐藏状态做加权平均来得到背景变量。decoder在每一时间步调整这些权重(注意力权重),从而能够在不同时间步分别关注输入序列中的不同部分并编码进相应时间步的背景变量。
可以在decoder的每个时间步使用不同的背景变量,并对输入序列中不同的时间步编码的信息分配不同的注意力。
广义上,attention机制的输入包括查询项以及一一对应的键项和值项;
attention机制可以采用更高效的矢量化计算。
6. 机器翻译
机器翻译指将一段文本从一种语言自动翻译成另一种语言。
特殊符号:
<pad>(padding) 添加在句子后,用来补齐短序列;
<eos>(end of sequence) 添加在句子末尾,表示序列结束;
<bos>"(beginning of sequence) 添加在句子开头,表示序列开始。
评价翻译结果:
通常使用BLEU(Bilingual Evaluation Understudy),对于模型预测序列中的任意子序列,BLEU考察这个子序列是否出现在标签序列中。
7. 语言模型
语言模型评价指标:通常使用困惑度(perplexity)来评价语言模型的好坏,它是对交叉熵损失函数做指数运算后得到的值。
1. 最佳情况下,模型总是把标签类别的概率预测为1,此时困惑度为1;
2. 最坏情况下,模型总是把标签类别的概率预测为0,此时困惑度为正无穷;
3. 基线情况下,模型总是预测所有类别的概率都相同,此时困惑度为类别个数;
显然任何一个有效模型的困惑度必须小于类别个数。


















 3208
3208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









