




 本文探讨了Simhash算法在大规模文本相似度计算中的应用,通过TF-IDF特征提取和Simhash原理,实现文本去重,并介绍了如何利用海明距离和关键词选择来提高效率。Simhash尤其适合处理海量文本,尽管存在精度局限,但其在速度上的优势显著。
本文探讨了Simhash算法在大规模文本相似度计算中的应用,通过TF-IDF特征提取和Simhash原理,实现文本去重,并介绍了如何利用海明距离和关键词选择来提高效率。Simhash尤其适合处理海量文本,尽管存在精度局限,但其在速度上的优势显著。
1. 为什么需要Simhash?
传统相似度算法:文本相似度的计算,一般使用向量空间模型(VSM),先对文本分词,提取特征,根据特征建立文本向量,把文本之间相似度的计算转化为特征向量距离的计算,如欧式距离、余弦夹角等。
缺点:大数据情况下复杂度会很高。
Simhash应用场景:计算大规模文本相似度,实现海量文本信息去重。
Simhash算法原理:通过hash值比较相似度,通过两个字符串计算出的hash值,进行异或操作,然后得到相差的个数,数字越大则差异越大。
2. 文章关键词特征提取算法TD-IDF
词频(TF):一个词语在整篇文章中出现的次数与词语总个数之比;
逆向词频(IDF):一个词语,在所有文章中出现的频率都非常高,这个词语不具有代表性,就可以降低其作用,也就是赋予其较小的权值。
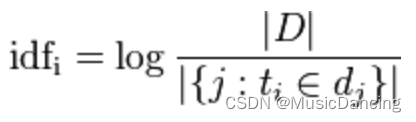
分子代表文章总数,分母表示该词语在这些文章出现的篇数。一般会采取分母加一的方法,防止分母为0的情况出现,在这个比值之后取对数,就是IDF了。
最终用tf*idf得到一个词语的权重,进而计算一篇文章的关键词。然后根据每篇文章对比其关键词的方法来对文章进行去重。simhash算法对效率和性能进行平衡,既可以很少的对比(关键词不能取太多),又能有好的代表性(关键词不能过少)。
3. Simhash原理
&n
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1477
1477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









