




 本文探讨了使用消息队列的必要性,如解耦系统组件、提升异步处理和削峰限流。同时,指出了高可用性、数据丢失风险、消费者获取数据方式以及额外考虑的问题,揭示了消息队列技术的复杂性与挑战。
本文探讨了使用消息队列的必要性,如解耦系统组件、提升异步处理和削峰限流。同时,指出了高可用性、数据丢失风险、消费者获取数据方式以及额外考虑的问题,揭示了消息队列技术的复杂性与挑战。
1. 为什么要用消息队列?
消息队列MQ是一个中间件:负责把要传输的数据放在队列中。 JDK实现的队列种类虽然有很多种,但都是简单的内存队列,所以MQ还是必要的。
1.1 解耦
一个例子:系统A负责产生一个userId,系统B、C、D拿这个userId去做相关的操作。 系统A将userId写到消息队列中,系统C和D从消息队列中拿数据,这样系统A与系统B、C、D都解耦了(当系统B、C、D发生变化时,系统A都不用经常改动)。
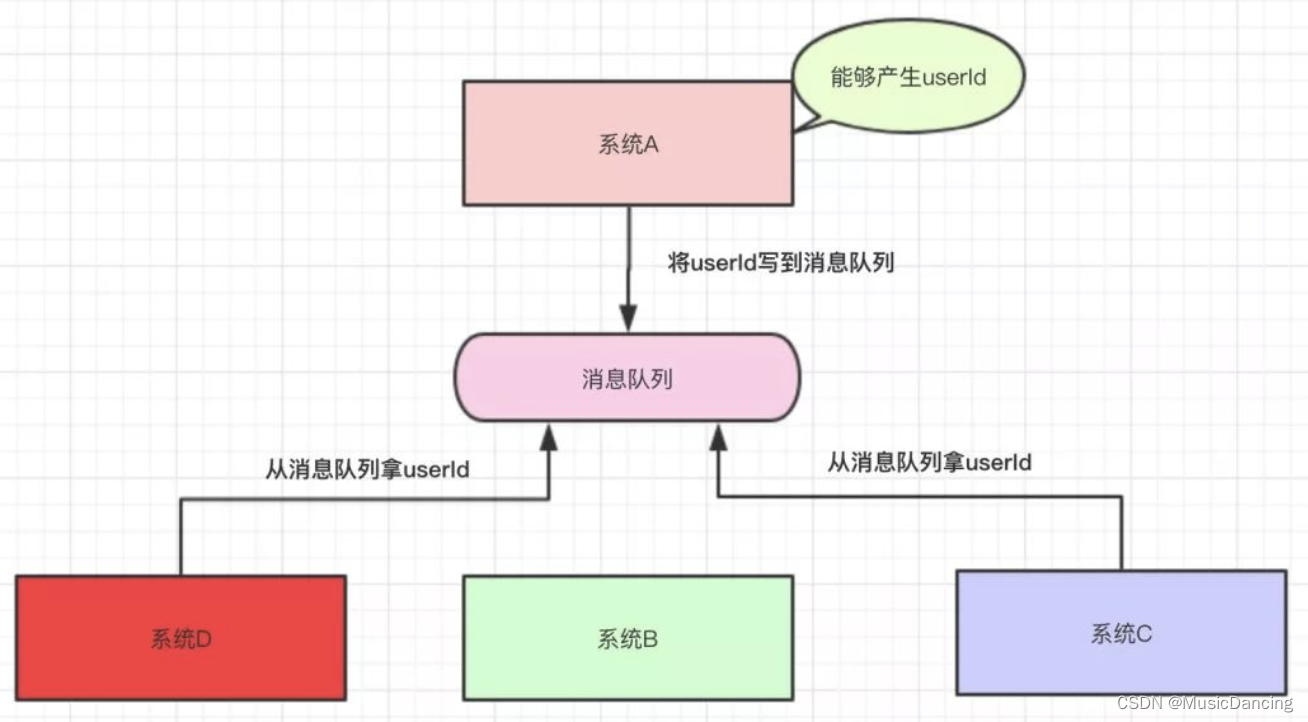
其好处如下:
系统A只负责把数据写到队列中,谁想要或不想要这个数据(消息),A一点都不关心。
即便现在系统D不想要userId这个数据了,系统B又突然想要userId这个数据了,都跟系统A无关,A一点代码都不用改。
系统D拿userId不再经过系统A,而是从消息队列里边拿。系统D即便挂了或者请求超时,都跟系统A无关,只跟消息队列有关。
1.2 异步
为了提高用户体验和吞吐量,可以异步地调用系统B、C、D的接口。
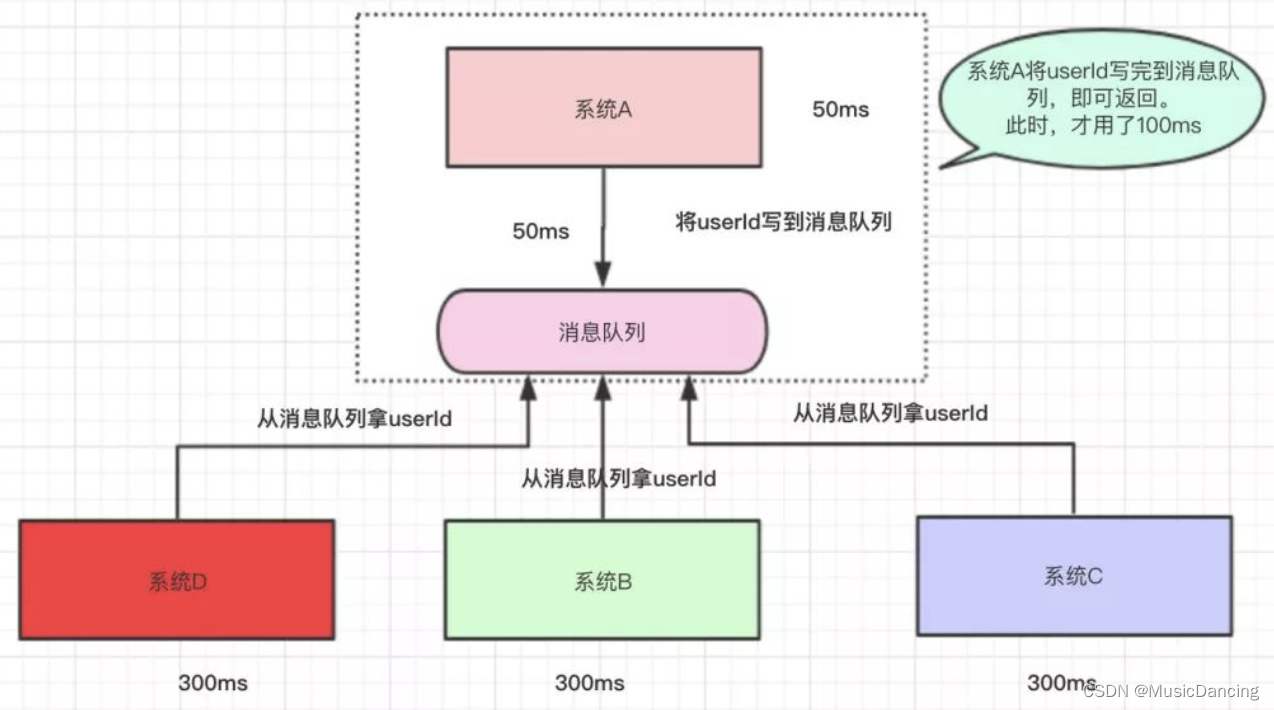
1.3 削峰/限流
一个削峰场景:每月一次大促,期间并发可能会很高(每秒3000个请求)。假设现有两台机器处理请求,且每台机器每次只能处理1000个请求。
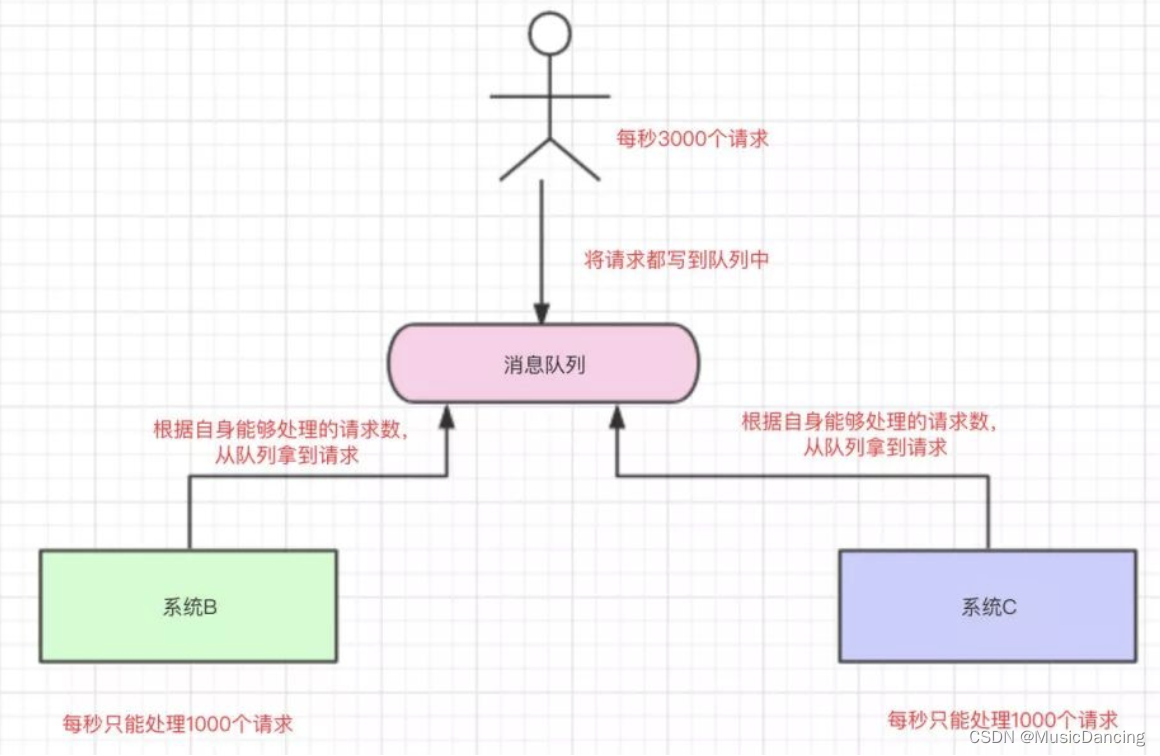
系统B、C根据自己能够处理的请求数去消息队列中拿数据,这样即便有每秒有8000个请求,那只是把请求放在消息队列中,从MQ拿多少消息由系统自己控制,就不会把整个系统给搞崩。
2. 使用消息队列有什么问题?
2.1 高可用
无论使用消息队列来做解耦、异步还是削峰,MQ肯定不能是单机的,必须是集群/分布式的。
2.2 数据丢失问题
将数据写到消息队列上,系统B和C还没来得及取消息队列的数据,就挂掉了。如果没有做任何的措施,数据就丢了。
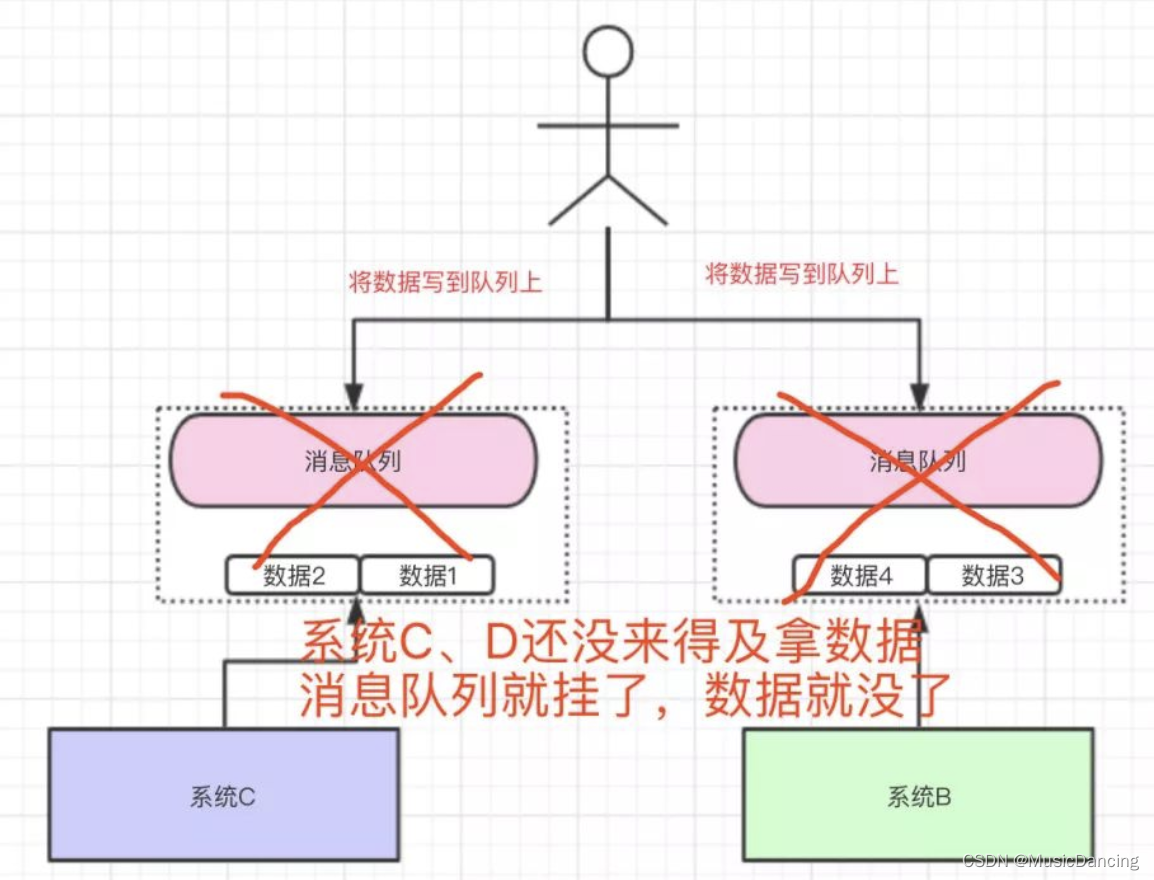
数据丢失问题:消息队列中的数据需要存储起来,尽可能减少数据的丢失。
存储在哪:磁盘?数据库?Redis?分布式文件系统?
同步存储还是异步存储?
2.3 消费者怎么得到消息队列的数据?
-
生产者将数据放到消息队列中,消息队列有数据了,主动叫消费者去拿(俗称push);
-
消费者不断去轮询消息队列,看看有没有新的数据,如果有就消费(俗称pull)。
2.4 其他要考虑的问题
-
消息重复消费?
-
保证消息是绝对有顺序?
虽然MQ带来了那么多好处,但同时也会提高系统的复杂性。

















 1591
1591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









