




 本文调研了业界的Embedding方法,包括YouTube的全连接模型,新浪的FM模型,百度的双塔DSSM模型,以及阿里的graph embedding(如DeepWalk和Node2vec)。对比了graph embedding与item embedding的优势,如拓宽推荐内容和平衡item训练。提出了在用户行为数据有限的情况下,使用graph embedding和LDA来训练用户和广告向量的方案。
本文调研了业界的Embedding方法,包括YouTube的全连接模型,新浪的FM模型,百度的双塔DSSM模型,以及阿里的graph embedding(如DeepWalk和Node2vec)。对比了graph embedding与item embedding的优势,如拓宽推荐内容和平衡item训练。提出了在用户行为数据有限的情况下,使用graph embedding和LDA来训练用户和广告向量的方案。
1. 业界Embedding方法调研
1.1 YouTube
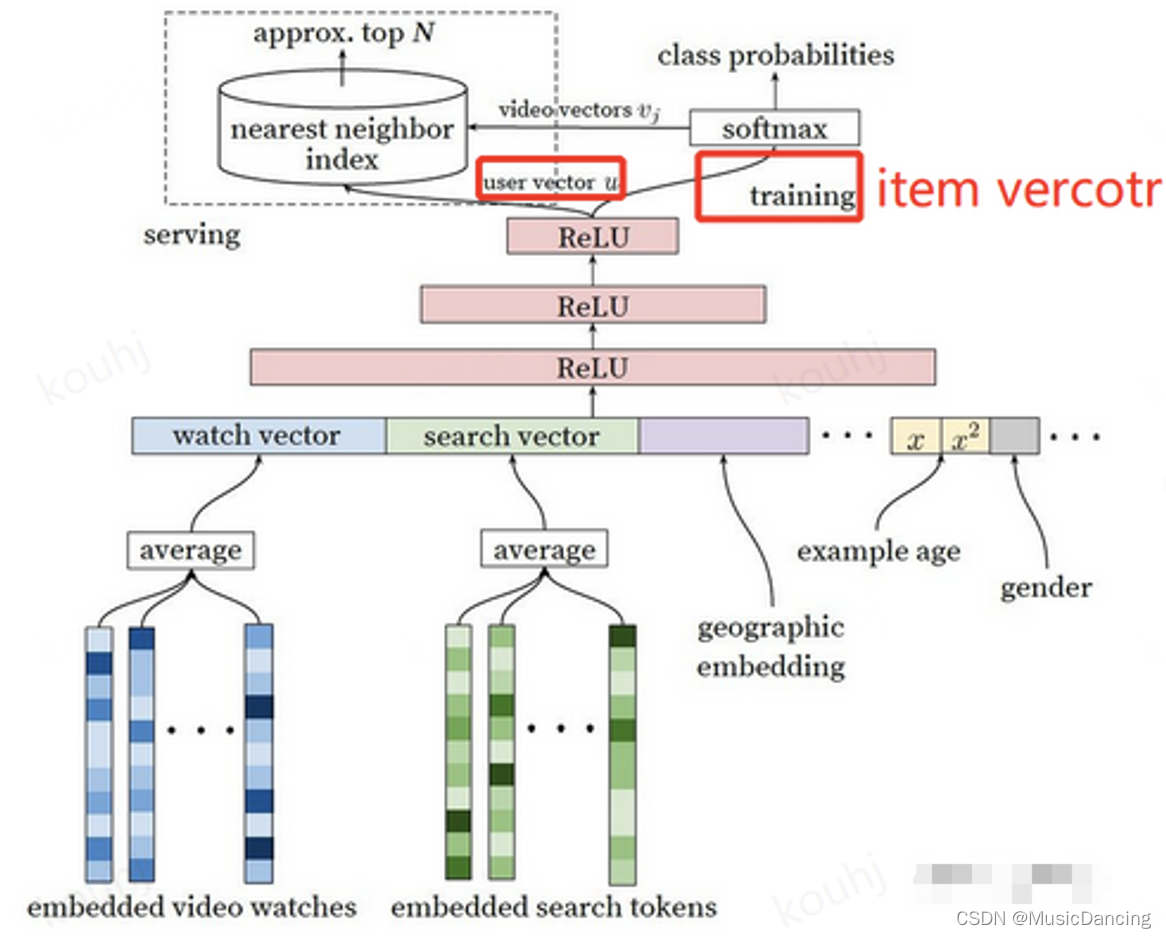
全连接模型,最上层的Relu输出为k维用户向量,然后经过 k*M 矩阵,映射为M维向量(与之对应,item共有M个),再经过softmax与用户点击过的视频拟合。
其中 k*M 为item向量,每个item向量为k维。
1.2 新浪
FM模型,特征分为3类:
1. 用户特征;
2. item特征;
3. 上下文特征;
模型训练完后,将所有用户特征的向量累加,作为用户特征;所有item特征的向量累加,作为item特征。
1.3 百度
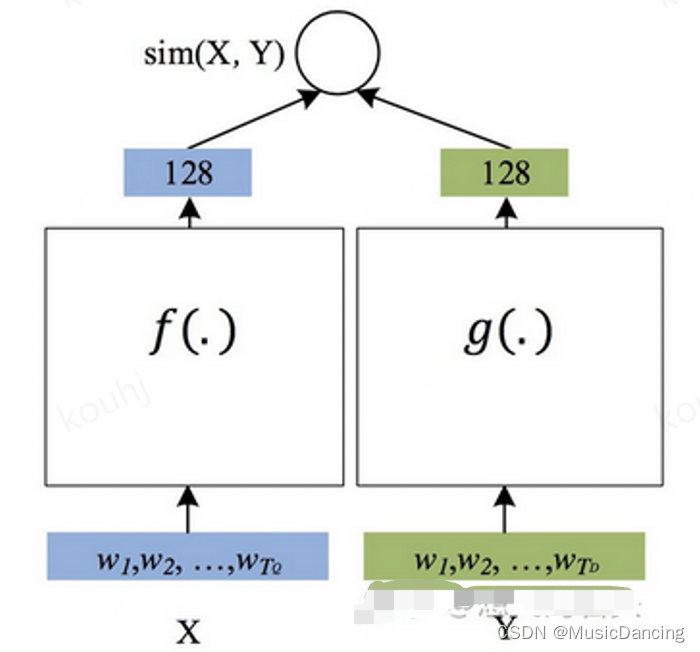
DSSM模型,双塔,分别输入用户特征、item特征,各自在顶层输出N维向量,并进行相似度计算后,拟合label。
1.3.1 双塔模型
1. 原理
模型训练过程中,在用户侧特征和广告侧特征分别做embedding。将排序问题转化为用户embedding向量和广告embedding向量匹配的问题,只需分别将用户和广告的embedding向量做内积。同时由于两个塔互相独立,因此通过提前对embedding向量进行缓存,可以加快计算速度。粗排模型使用双塔DNN是为了精排前对广告解析截断,减少输入,加快计算。
一般双塔结果设计如下:
2. 网络实现:
1. 分别在用户和广告侧对category特征做embedding;
2. 然后与dense特征进行concat,之后再经过几个简单的FC层,分别得到用户和广告的embedding向量;
3. 对用户和广告的embedding向量进行concat,再接FC层,得到output。
3. online server:
线上预测时,可分为实时计算user embedding 和离线获取user embedding两种场景。
方案1: 将用户embedding和广告embedding存入内存数据库。
离线训练生成user和广告两个部分的embedding,并将其存放在redis中,online时请求Redis获取。这种情况下不方便利用实时特征和context特征,但计算速度会很快,粗排模型可以考虑。 处理速度快,n * ad embedding dim 和 user embedding 做一次内积;线上开发工程量少,不需要DNN预估模块,便于快速开发上线。
1. 请求redis获取用户和广告级别的embedding;
2. 如果获取到对应的embedding,计算二者的积,ctr = sigmoid(use_embeding * item_embeding);
3. 如果没有获取到,则用模型计算ctr。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 17
17

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









