




1. LightGBM简介
Light Gradient Boosting Machine 是一个实现GBDT算法的框架,支持高效率的并行训练,并且具有以下优点:
1. 更快的训练速度;
2. 更低的内存消耗;
3. 更好的准确率;
4. 分布式支持,可以快速处理海量数据。
1.1 GBDT的不足
GBDT在每一次迭代的时候,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。尤其面对工业级海量的数据,普通的GBDT算法是不能满足其需求的。
LightGBM提出的主要原因就是为了解决GBDT在海量数据遇到的问题,让GBDT可以更好更快地用于工业实践。
1.2 相比于XGBoost的优化
1. 基于Histogram的决策树算法;
2. 带深度限制的Leaf-wise的叶子生长策略;
3. 直方图做差加速直接;
4. 支持类别特征(Categorical Feature);
5. Cache命中率优化;
6. 基于直方图的稀疏特征优化多线程优化。
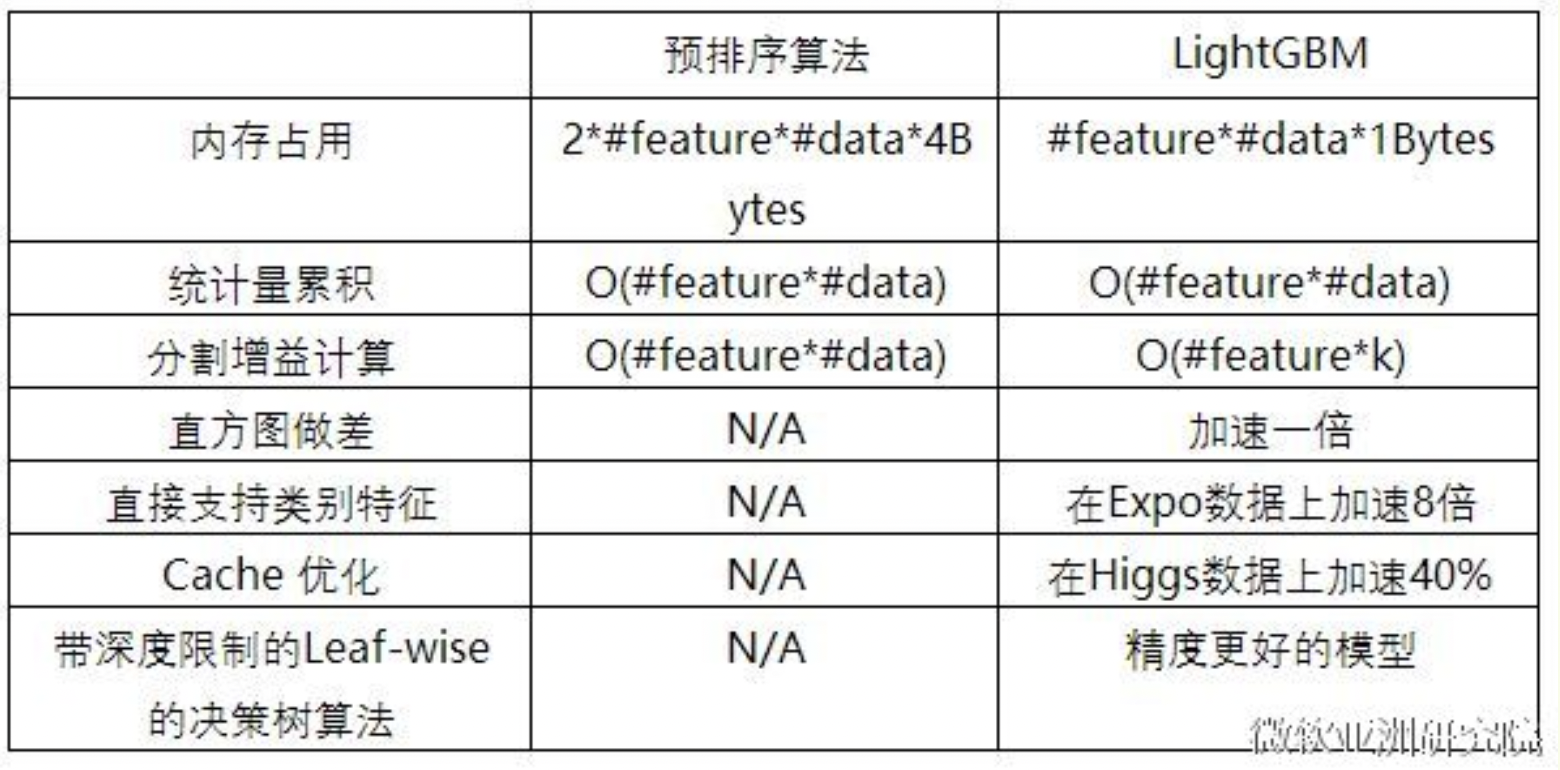
2. LightGBM的优化点
2.1 使用直方图的方式
基本思想:先把连续的浮点特征值离散化成k个整数(其实就是分桶的思想,而这些桶称为bin,比如[0,0.1)→0, [0.1,0.3)→1),同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。

优点:
1. 内存消耗的降低:直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。
2. 计算代价也大幅降低:预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7377
7377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









