




 本文详细介绍了性别和年龄冷启动预测的策略,包括数据来源、模型选择(如LR和XGBoost)、离线验证结果以及上线逻辑。性别冷启动采用LR模型,基于applist和mobile特征,新模型正确率显著提高。年龄四段冷启动通过线性回归和XGBoost算法,结合applist和联系人年龄分布特征进行预测,验证效果良好,覆盖广泛。
本文详细介绍了性别和年龄冷启动预测的策略,包括数据来源、模型选择(如LR和XGBoost)、离线验证结果以及上线逻辑。性别冷启动采用LR模型,基于applist和mobile特征,新模型正确率显著提高。年龄四段冷启动通过线性回归和XGBoost算法,结合applist和联系人年龄分布特征进行预测,验证效果良好,覆盖广泛。
1. 性别冷启动
性别冷启动包括v1,v2两个版本:
v1版本提供给lx和wx(全量更新计算方式),分别以特征文件的方式提供给业务方,统计截取后的全量的applist和mobile;
v2版本提供给zx(日活增量更新数据),统计top-N的applist和mobile(建议全量特征参与训练,然后取权重绝对值最大的top-N特征),两版本均采用lr模型。
1.1 数据
特征来自于画像宽表,label来自于用户事实表。
使用特征:applist, 手机品牌+手机型号
applist 为空或者为'com.snda.wifilocating' (只获取到wifi的一个app)设为默认值:未知。
mobile=brand+model:从设备信息表中获取。
训练数据: 615w,验证数据:100w
20200520统计结果如下:
| 匹配量 | 总量 | 正确率 | |
| 探测性别 | 12.13w | 22.19w | 54.65% |
| 用户选择 | 0.65w | 1.16w | 56.49w |
特征说明:
1)安装app列表
- 安装app类型包括用户app和系统app,数据包括offline数据和push数据,offline数据一周全量更新一次,push数据每天增量更新一次;
- 过滤安装数小于阈值的app,生成对应的词典;
2)手机品牌,手机型号
- 与安装app列表同理,过滤小于阈值的手机品牌、型号,生成对应的词典;
3)昵称,姓名
- 切分为单词,统计单词出现次数,过滤低于阈值的单词,生成对应的词典;
4)相关称谓
- 从通讯录姓名中过滤出称谓数据,根据称谓关系,推断用户间年龄的相对大小;例如A称呼B为爸爸,则A的年龄比B小;
- 通讯录中存在着称呼与被称呼的情况,例如:B被A称呼为爸爸,同时B称呼C为哥哥,则B的年龄比A大,比C小;
- 根据上述的情况,定义name字段的格式为:“[~]称谓,0/1”。假设B被A称呼为爸爸,且B称呼C为哥哥,则用户B的name字段值表示为“~哥哥,0&爸爸,1”,其中,“~”符号表示B对他人的称呼,“0”表示B的年龄相对较小,“1”表示B的年龄相对较大。
1.2 模型(配置文件)
选用使用lr模型, 通过L1正则选择重要非0特征(运行train.py),生成applist_weight.txt、mobile_weight.txt和lr.pkl模型文件,文件格式如下:
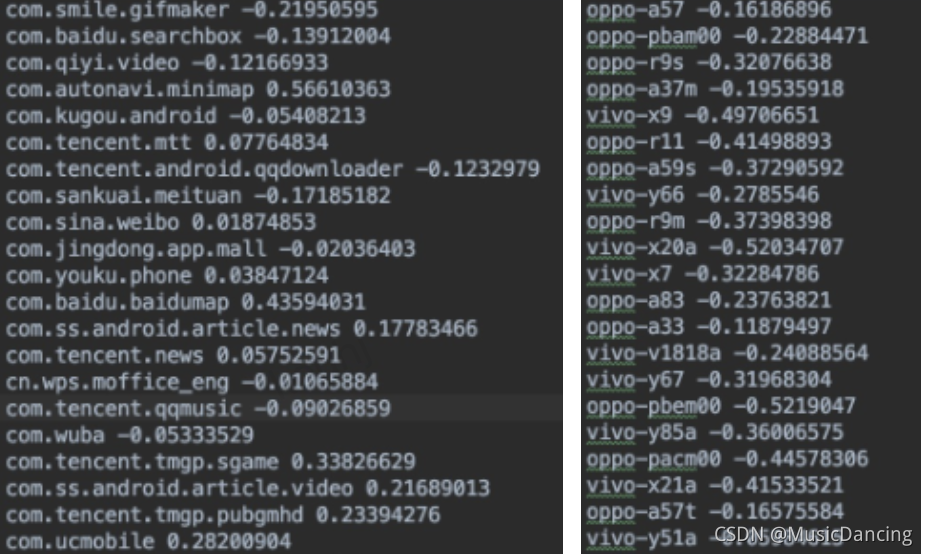
训练数据和特征字典需要更新, 注意:
1. ys性别可以使用spark集群方式全量更新数据类似于年龄冷启动;
2. 定期更新模型;
3. 提供线上冷启动服务版本。
1.3 离线验证结果
验证线上数据量:100w
旧模型:
特征数:app=13617, 手机=2836
男性:>= 1.2083, 女性: < -0.364
1. applist 为空, 正确率:1.6%, 覆盖率:2%
2. 去掉未知, applist 不为空,正确率:89%, 覆盖率:68%
3. 去掉未知, applist 为空, 正确率:83%, 覆盖率:2%
新模型:
特征数:app=13600, 手机=860
男性:sigmoid_score>=0.5,女性:sigmoid_score<0.5
1. applist 不为空, 正确率:85%, 覆盖率:100%
2. applist 为空, 正确率:76%, 覆盖率:100%
3. 去掉未知, applist 不为空,正确率:89.7%, 覆盖率:82.7%
4. 去掉未知, applist 为空, 正确率:85.6%, 覆盖率:2%
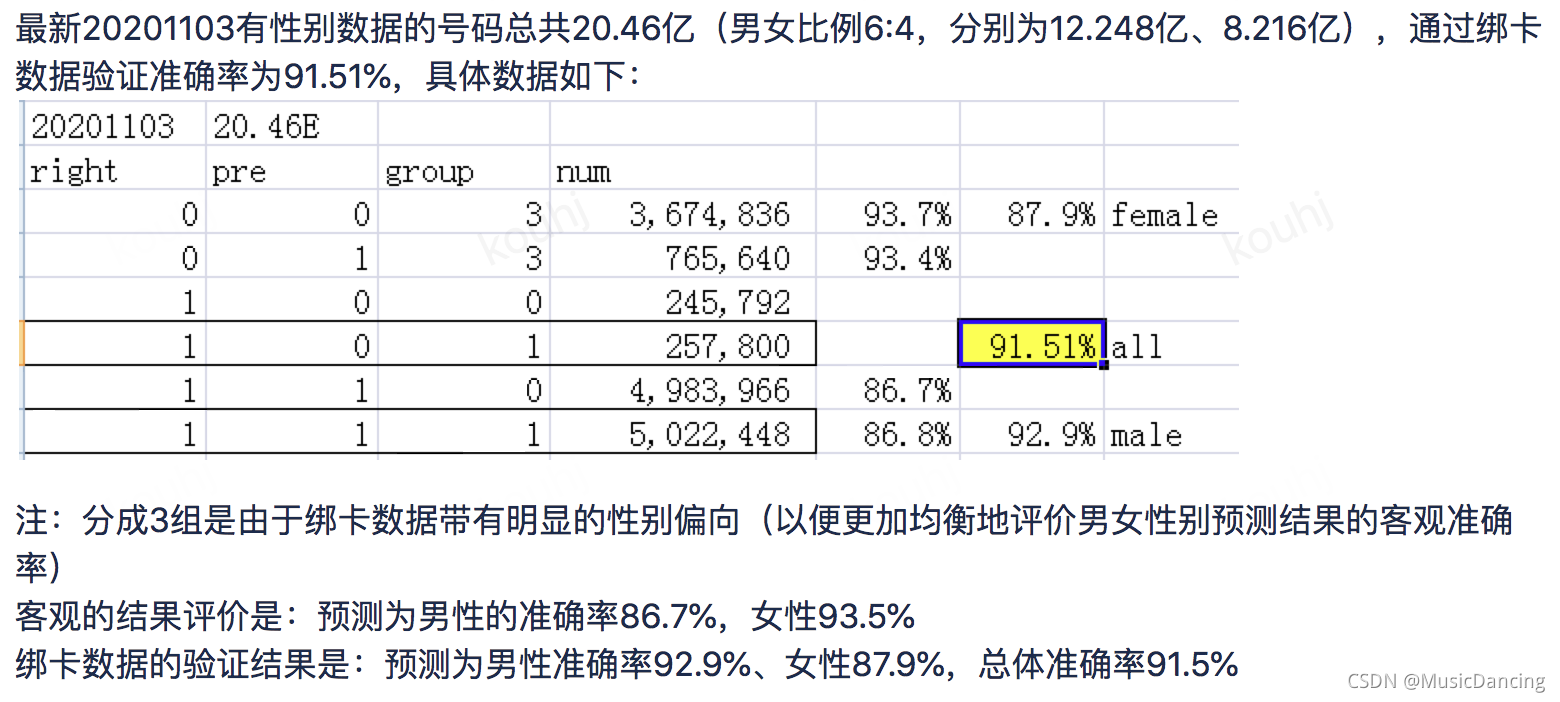
1.4 上线逻辑及效果
用户得分score = 基础分(bias=1.09805389) + 用户分(applist权重和型号权重累加)
然后通过sigmoid函数进行映射到[0,1],sigmoid_score=1.0/(1.0+exp(-score))。
分类映射:
男性:sigmoid_score>=0.75;
女性:sigmoid_score<0.5;
未知:0.5<=sigmoid_score<0.75。
旧模型验证结果:正确率:89.47%, 覆盖率:67.7% ;
新模型验证结果: 正确率:89%, 覆盖率:83%
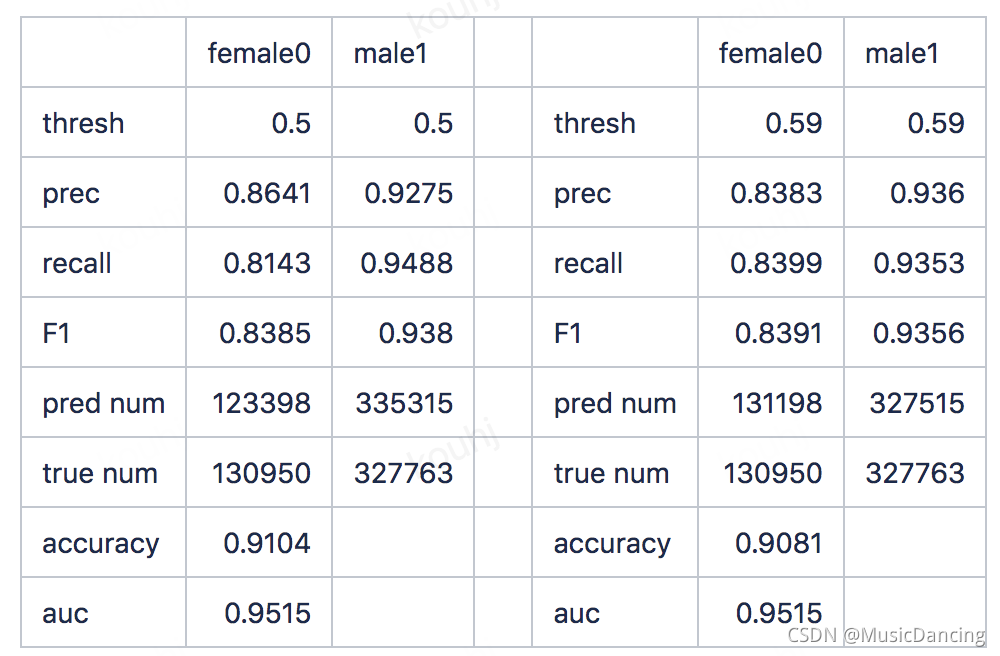
1.5 通讯录预测原理
0. 名字、称谓(百度百科、手动整理)、职业(手动整理、jieba热词提取)抽取;
1. 标注(带有明显性别偏向:爸妈爷奶、叔叔、婶婶、哥哥、姐姐、妹妹、弟弟等);
2. 名字、称谓、职业性别偏向概率统计;
3. 基于名字、称谓、职业的贝叶斯方法加权预测。
标签选取:
职业:分行业及常识人工整理,包括:党政军机关、税务、贸易、金融、教育、培训、医疗、健康、房地产、建筑、媒体、艺术、市场、旅游、科研、行政、批发、零售、生活各类服务,以及公司、职业称谓等382个标签
称谓:根据百度百科(家庭称谓)和常识人工整理出504个标签
TF-IDF提取:抽取一千万条用户姓名标注信息,利用jieba分词的extract_tags包抽取top一千个关键词,然后人工整理获得408个标签(去掉名字类,如小王、老李、建军等)
合计:1107个标签(合并去重),可有针对性补充、添加、扩展等
名字提取:
1. 获取关键词--标注信息直接jieba分词
2. 规则匹配--去掉非字母、数字、汉字的特殊符号
3. 限定长度--含有字母、数字的限制名字长度在[2, 5]之间,否则限制在[1, 4]之间
4. 过滤--去掉包含在姓氏或标签中的词
5. 统计词频<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









