




 本文详细介绍Linux下grep、sed和awk三个强大的文本处理工具,包括命令格式、常见参数、正则表达式应用及实际操作案例,适用于文本搜索、替换、格式化输出等场景。
本文详细介绍Linux下grep、sed和awk三个强大的文本处理工具,包括命令格式、常见参数、正则表达式应用及实际操作案例,适用于文本搜索、替换、格式化输出等场景。
1. grep 关键字匹配
参考egrep https://mp.youkuaiyun.com/editor/html/112490742 更多好用功能
global regular expression print是linux中最强大的文本搜索命令之一,常用于搜索文本文件中是否含有某些特定模式的字符串。该命令以行为单位读取文本并使用正则表达式进行匹配,匹配成功后打印出该行文本。
1.1 命令格式及参数说明
grep [option] "string_to_find" filename [filename2 filename3 ...]
string_to_find为需要匹配的模式,可以填写字符串或者正则表达式
filename为需要查找的文件的名称(可追加多个文件名,实现在多个文件中查找)
常见选项:
-i: 忽略搜索字符串的大小写
-v: 取反,即输出不匹配的那些文本行
-n: 输出行号
-l: 输出能够匹配模式的文件名,相反的选项为-L
-q: 静默输出
-c: 计算匹配成功的行数
注意:-c选项在遇到一行中多次匹配正则表达式的情况时只是认为这一行匹配成功,而不会计算匹配成功的次数
-o: 只输出匹配到的文本部分(统计文件中匹配的数量).
-r: filename为目录时可以加上本选项表示递归搜索
-e: 该选项加上正则表达式就是一个需要匹配的模式
-E: 支持扩展正则表达式1.2 常见用法
1.2.1 匹配字母与数字
# 匹配非小写字母
grep '[^a-z]' data.txt
grep '[^[:lower:]]' data.txt
# 匹配文件中出现的数字
grep '[0-9]' data.txt
grep '[[:digit:]]' data.txt1.2.2 匹配开头与结尾
# 匹配aa开头的行
grep '^aa' data.txt
# 匹配小写字母开头的行
grep '^[a-z]' data.txt
# 找出空白行(^:行首;$:行尾)
grep '^$' data.txt
# 找出aa开头与aa结尾的字符串
grep 'aa.*aa' data.txt --会显示一整行
备注: .*代表0或多个任意字符
# 匹配非英文字母开头的行
grep -n '^[^a-zA-Z]' data.txt
备注: ^在[]之内表示反向选择,在[]之外表示行首1.2.3 多关键字匹配
# 匹配hello或者world的行
grep -e "hello" -e "world" data.txt
egrep 'hello|hello' data.txt1.2.4 反向选择
# 去掉文件中的空白行和#开头的注释行
grep -v '^$' data.txt | grep -v '^#'
egrep -v '^$|^#' data.txt # egrep 扩展正则表达式1.3 格式化输出
# 10s 宽度为10的字符串
# 5i 宽度为10的整数
# 10d 宽度为10的数字
# 8.2f 宽度为8的小数,整数部分长度为5,小数部分长度为2
# grep -v name 去掉第一列标题列(含有name字段)
printf '%10s %5i %8.2f \n' $(cat data.txt | grep -v name)2. sed 处理一整行
sed [-nefri] [动作]
# 参数说明:
-i 直接在原文件上进行修改
-r 动作支持扩展型正则表达式
-n 经过sed特殊处理的行才会被显示到屏幕上
-e 直接在命令行模式上进行sed的动作编辑
# 动作说明:
a 新增一行(当前行的后一行)
i 新增一行(当前行的前一行)
d 删除一行
s 替换
p 打印
c 行替换(change)2.1 常见用法
2.1.1 字符串替换
# 文件字符串替换
sed -i 's/原字符串/替换字符串/g' filename
# 文件连续多行字符串替换
sed '2,5s/s1/s2/g' filename
# vim 文件字符串替换
:%/s1/s2/g ????? :%s/s1/s2/g
2.2 行的查改增删
2.2.1 查看行
# 查看指定行
sed -n '2,5p' aa.txt 2.2.2 增加行
# 在文档指第n行后增加一行,(hello world)
sed 'na hello world' aa.txt
# 在文档指第n行前增加一行 ($ 最后一行)
sed 'ni hello world' aa.txt
# 在以kk 开头的行后,追加一行
sed -i '/kk /hello world' aa.txt
抽象出来就是: sed -i '/* /a*' <file>2.2.3 删除行
# 删除文件中的第n行 ($d 删除最后一行)
sed -i 'nd' aa.txt
# 删除文件中的第2-5行
sed -i '2,5d' aa.txt
# 删除文件中以某个关键字(kk)开头的所有行
sed -i '/^kk/d' aa.txt
# 删除文件中包含某个关键字(kk)的所有行
sed -i '/kk/d' aa.txt
cat aa.txt | sed /kk/d
# 删除#注释行
sed -i 's/#.*$//g' aa.txt
# 删除空白行
sed -i '/^$/d' aa.txt
2.2.4 行替换
# 将 2-5行替换成"hello world"
sed '2,5c hello world' filename2.2.5 行处理
# "inet addr:192.168.1.100 Bcast:192.168.1.255",删除左右两边只保留中间ip
cat filename | sed 's/^.*addr://g' | sed 's/Bcast.*$//g'
sed -e 's/^.*addr://g' -e 's/Bcast.*$//g' filename
备注: 使用-e 连接两个以上的动作
# 删除行首空白
sed 's/^[ \t]*//g' filename
备注:中括号表示“或”,空格或tab中的任意一种;*表示一个或多个。
# 删除行尾空白
sed 's/[ \t]*$//g' filename
# 删除所有空白
sed 's/[[:space:]]//g' filename 一个实例:去除字符串中的空格

3. awk 处理字段
awk '条件类型1 {动作1} 条件类型2 {动作2}...' filename
awk 主要处理每一行字段内的数据,默认字段分隔符尾空格或tab键。
awk 中变量可以直接使用,不要加上$
| $0 | 代表一整行数据 |
| $[i] i=1,2,3,... | 第i 个字段 |
| NF | 每一行字段总数 |
| NR | 目前所处理的是第几行 |
| FS | 目前的分隔符,默认空格 |
| $NF | 取最后一列:awk -F',' '{print $NF}' |
3.1 根据过滤条件输出指定列
指定分隔符为":",且第三个字段<10,格式化输出第1、3字段。
awk 'BEGIN {FS=":"} $3<10 {printf $1 "\t" $3 "\n"}' data.txt 3.2 指定字段求和作为新的列
对p1、p2、p3字段求和,结果存入Total。
awk 'NR==1{printf "%10s %10s %10s %10s %10s\n", $1,$2,$3,$4,"Total"};
NR>=2{total=$2+$3+$4; printf "%10s %10d %10d %10d %10.2f\n", $1,$2,$3,$4,total}' pay.txt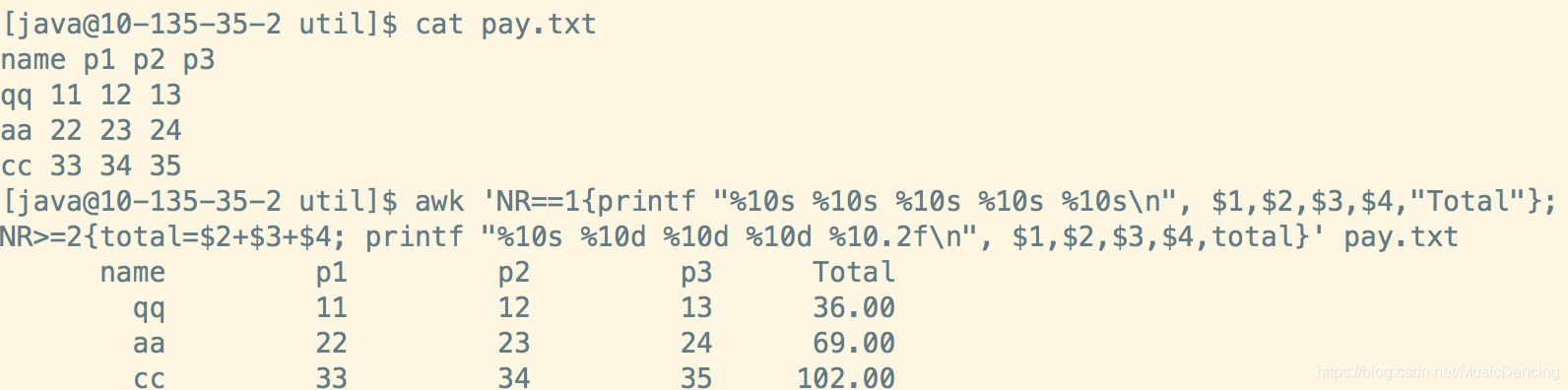
3.3 统计字段次数并排序
统计phone_list.txt中电话号码出现的次数,并按次数从高到低排序(实现类似group by 的功能)
awk '{arr[$1]+=1}END{for(i in arr) print i,arr[i]}' phone_list.txt | sort -k 2 -r
# awk 中的数组类似字典(可以是任意字符或字符串)
# 使用sort 实现
cat phone_list.txt | sort | uniq -c | sort -k 1 -r

3.4 统计指定条件的文件数量
统计 aa目录下>100k文件的数量和总文件大小
cd aa
ls -l | awk '{if($5>100){count++;sum+=$5}}END{print "count: "count,"\nsum: "sum}'
# awk 会轮询统计,显示整个过程,加入END后只显示最后结果4. 通配符 wildcard
通配符与正则表达式完全不一样,不要搞混!!!!
| * | 代表0到多个任意字符 |
| ? | 代表一定有一个任意字符 |
| [] | 代表一定有一个在[]内的字符,[abc]可能是a,b,c中任一个 |
| [-] | [0-9] 代表0-9之间的所有数字 |
| [^] | 反向选择 ; [^abc] 非a,b,c的其他字符 |
5. Regular Expression
5.1 正则表达式RE
| * | 重复前一个0到无穷多次 |
| . | 一定有一个任意字符 |
| ^word | 待查找的字符串(word)在行首 |
| word$ | 待查找的字符串(word)在行尾 |
| \ | 转义符 |
| [list] | [qaz] 一定是q,a,z中的任一个 |
| [n1-n2] | n1,n2之间所有连续的字符 |
| [^list] | 反向选择 |
| \{n,m\} | 前一个字符重复n到m次;\{n\}重复n次;\{n,\}至少重复n次 |
5.2 扩展正则表达式 egrep
| + | 重复前一个RE字符1到无穷多次 |
| ? | 前一个RE字符出现0或1次 |
| | | 或 |
| () | 找出‘组’字符串 |
| ()+ | 多个重复组的判别 |
# 匹配dog,cat和apple
egrep 'dog|cat|apple' data.txt
# 匹配glad和good
egrep 'g(la|oo)d' data.txt
# 匹配以A开头以C结尾,中间有一个以上的“xyz”的字符串
egrep 'A(xyz)+C' data.txt
















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









