 涂鸦萌宠语聊模板:借助AI音频技术远程安抚宠物
涂鸦萌宠语聊模板:借助AI音频技术远程安抚宠物




在快节奏的现代生活中,宠物们常常因为主人频繁外出、互动不足而感到孤独、抑郁,甚至变得焦虑、暴躁。为了给宠物们带来更多安全感,涂鸦隆重推出基于On-App AI的萌宠语聊模板。这一模板运用先进的语音技术和智能设备,实现远程陪伴宠物,加深主人与宠物之间的情感纽带,有效缓解宠物的焦虑情绪。而且,这一模板不仅适用于宠物场景,还能拓展至智能家电、婴儿看护等领域,以音频能力为辅助,构建更加人性化的远程监管系统。
一、涂鸦萌宠语聊模板功能概览
1、宠物行为识别与情绪安抚
涂鸦的语音识别与宠物行为分析技术相结合,能够精准识别宠物的异常行为,如频繁嚎叫、低鸣等,从而判断宠物的情绪状态,并迅速采取安抚措施。例如,当检测到宠物焦躁不安时,模板会自动播放安抚语音包(主人可提前录制,也可使用系统指定语音包),或触发互动模块联动其他智能设备(如逗宠器)进行安抚。

2、远程语音陪伴与双向交互
主人可通过涂鸦的远程语音对讲功能,与宠物进行直接交流,让爱跨越距离,时刻陪伴在宠物身边,有效缓解宠物的孤独感。

二、涂鸦核心技术亮点解析
涂鸦基于On-App AI技术架构,融合本地音频采集、实时对讲与文件录制功能,引入AI降噪与AI语音活动检测能力,对复杂环境下的人声、噪声进行深度建模与智能分离,为宠物设备与用户带来更智能、更拟人化的语音交互体验。

1、兼容多格式语音编码
涂鸦支持用户上传和导出Opus、PCM、WAV、MP3、G.711A、mSBC等主流音频编码格式,确保在不同设备与传输协议间实现高保真、低延迟的语音数据传输与协同,提升系统集成灵活性。
2、实时智能优化对讲音频质量
涂鸦萌宠语聊模板集成了自适应主动降噪(ANC)、回声消除(AEC)、自动增益控制(AGC)和语音活动检测(VAD)等多项先进音频处理技术,全面提升多设备端实时语音通信质量,提供更清晰、更稳定、更高效的语音交互体验。
-
自适应语音降噪(ANC):涂鸦结合深度学习与传统信号处理算法,智能识别并区分人声与环境噪声,即使在地铁、街头等嘈杂环境下也能实现清晰拾音。
-
回声消除(AEC):精准识别并清除回声路径中的扬声器反馈声,防止声音回环扰乱语音传达,优化双向语音通话体验。
-
自动增益控制(AGC):动态调整音量,保证远近声源响度一致,避免因录制距离或音量变化导致的声音忽大忽小现象。
-
智能语音活动检测(VAD):精准识别语音段、噪声段和静音段,实时智能过滤无关噪声和静音段,降低系统功耗,提高响应速度和处理效率。
三、不同场景下的音频技术处理方案
1、处理本地音频技术
涂鸦支持主人上传自己录制的音频文件,并自动对录音进行优化处理,确保声音清晰流畅、无延迟,真正起到安抚宠物情绪的效果。
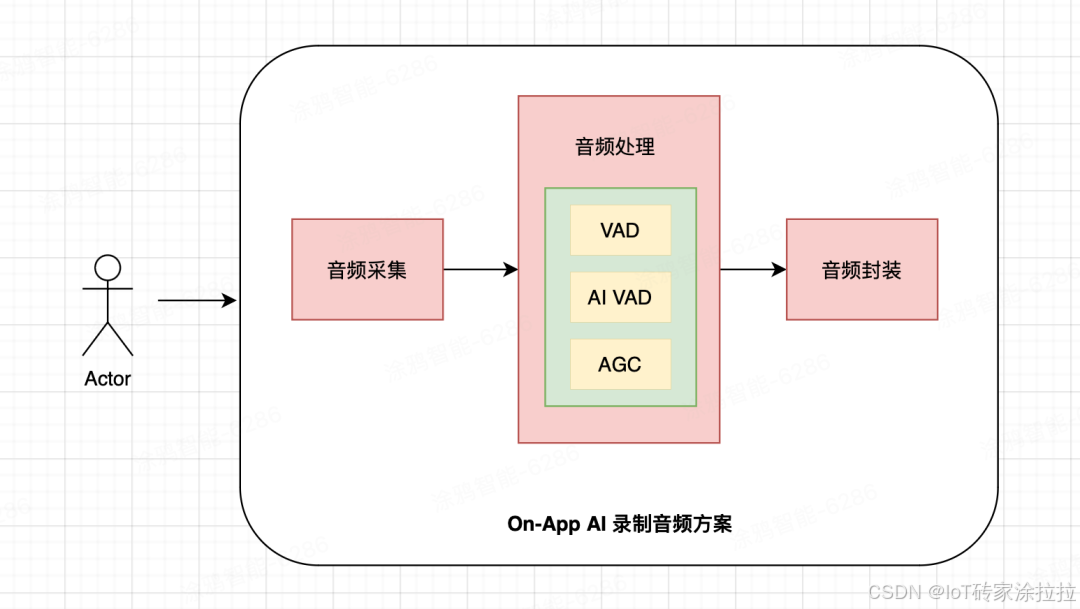
-
录音清晰稳定:通过内置自动增益控制(AGC)技术,根据输入信号的强弱自动调整录音增益,动态适配说话人的远近与音量差异,使输出音量保持相对稳定。
-
智能语音检测:通过语音活动检测(VAD)模块,在本地实时识别人声与静音/噪声段,有效减少无效音频数据的采集与处理。涂鸦支持调节灵敏度,便于根据实际场景灵活优化检测效果,并可结合AI大模型,进一步提升复杂环境下的语音检测准确率与适应性。
-
多格式支持:涂鸦兼容支持MP3、G.711A、G.711U、Opus、AAC、mSBC等多种主流音频编码格式,满足多样化平台及应用场景的存储与回放需求。
2、实时语音对讲处理技术
在实时语音对讲场景中,涂鸦支持萌宠语聊模板自动对通话音频进行智能化处理,确保双方声音清晰无噪音,沟通流畅无延迟。
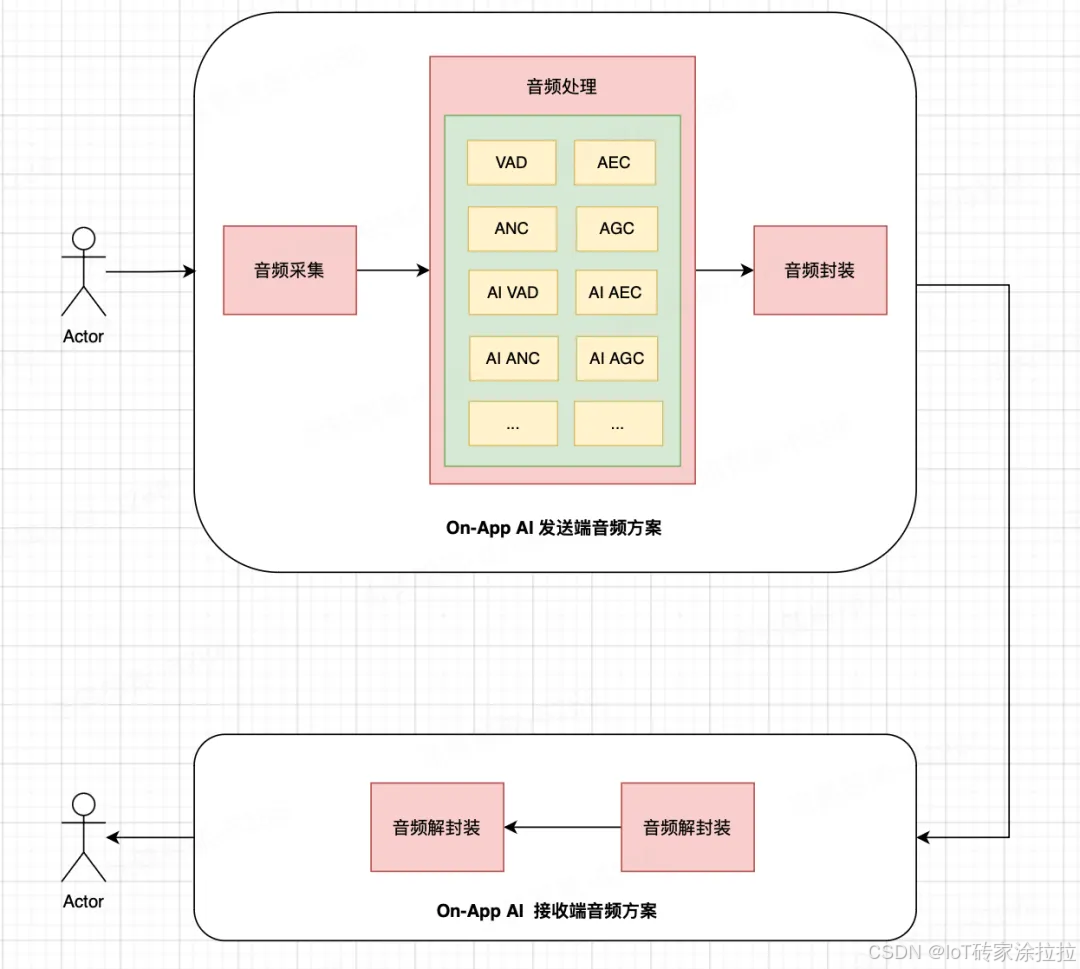
-
智能语音检测:通过语音活动检测(VAD)模块,在本地实时识别人声与静音/噪声段,有效减少无效音频数据的采集与处理。
-
AI降噪:涂鸦AI降噪技术基于深度神经网络建模语音与噪声,相较传统算法,在复杂环境下可显著提升信噪比和PESQ评分,延迟控制在100ms内,广泛适用于对语音清晰度要求高的场景。结合回声消除(AEC)与降噪技术,可支持最大200ms回声延迟路径补偿。
-
毫秒级低延迟传输:采用Opus编码等高效音频压缩技术,在保证语音质量的同时,实现毫秒级低延迟传输,让双向对讲如同面对面交流。适合对时效性要求高的场景,如通话对讲、智能门铃、安防监管等。
四、开发教程与问题咨询
1、开发教程
复制下方链接,了解具体开发流程👇:
2、开发者问题咨询
开发过程中如遇任何问题,欢迎登录涂鸦开发者平台提交技术工单,技术小哥将及时为你解答👇:


















 1696
1696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











