




文章目录
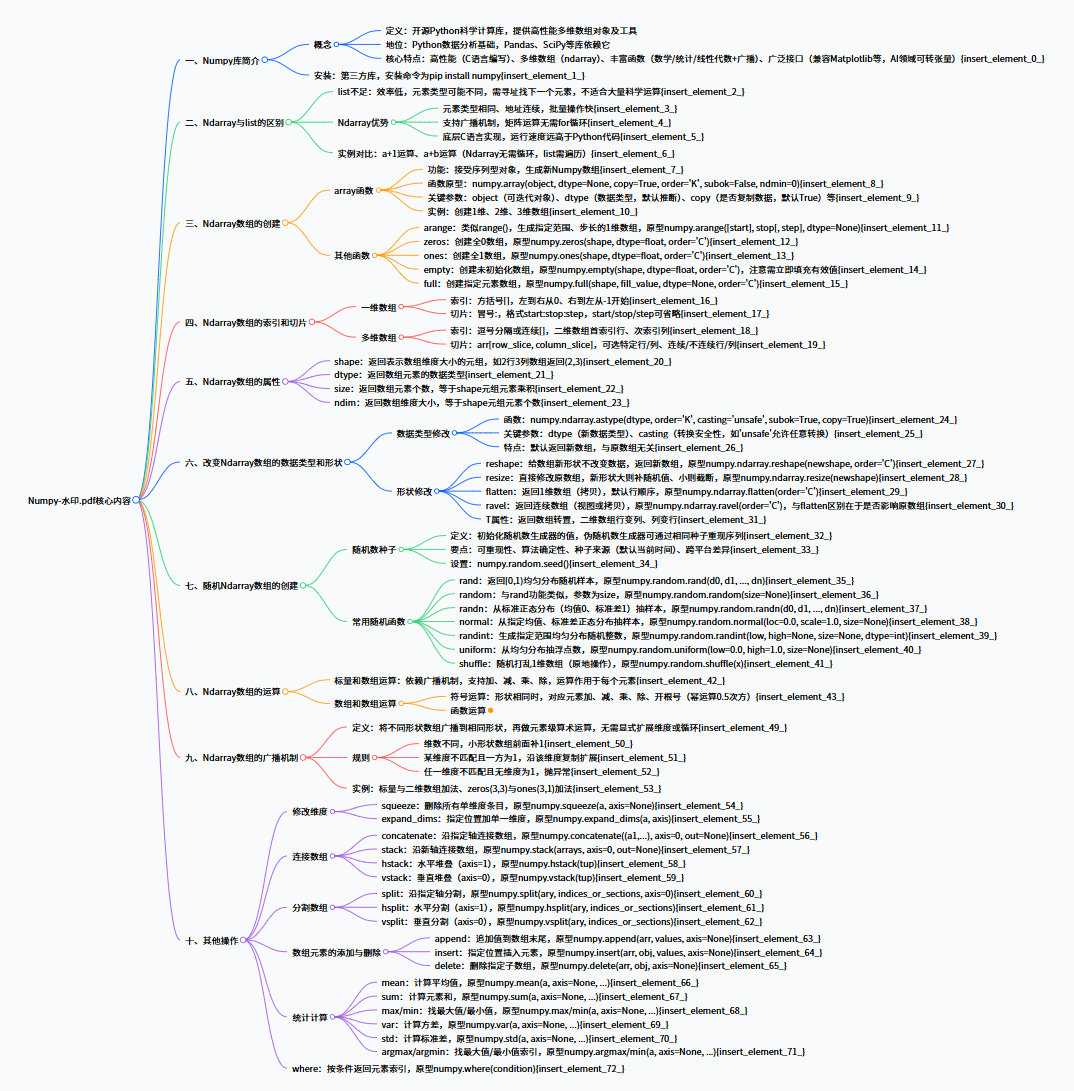
思维导图
前言
在Python科学计算领域,NumPy(Numerical Python)是当之无愧的基石库。无论是数据分析、机器学习,还是工程计算,NumPy的高性能多维数组和丰富工具都不可或缺。本文将从基础概念到实战操作,带你系统掌握NumPy,让你轻松应对各类数值计算场景。
一、NumPy库简介
1.1 核心概念与优势
NumPy的核心是ndarray(多维数组对象),它解决了Python原生列表在大规模数值计算中的效率问题。相比传统Python工具,NumPy的优势主要体现在4个方面:
- 高性能:底层基于C语言实现,运算速度比纯Python代码快10-100倍,同时保留Python的易用性。
- 多维数组:支持1维到N维数组,可高效存储和处理结构化数据,是后续学习Pandas、SciPy的基础。
- 丰富函数:内置数学、统计、线性代数函数(如矩阵运算、傅里叶变换),还支持“广播机制”,可直接对不同形状数组做算术运算。
- 广泛兼容:与Matplotlib(绘图)、SciPy(科学计算)、TensorFlow(深度学习)等库无缝衔接,且能快速与张量(Tensor)转换。
1.2 安装教程
NumPy是第三方库,需提前安装,命令简单直接:
# 使用pip安装(适用于Windows/macOS/Linux)
pip install numpy
# 验证安装是否成功
import numpy as np
print(np.__version__) # 输出版本号即安装成功,如1.26.4
二、Ndarray与Python列表
Python原生列表(list)虽灵活,但在科学计算中存在明显短板,而Ndarray恰好弥补了这些不足。两者的核心差异如下表:
| 对比维度 | Ndarray | Python列表(list) |
|---|---|---|
| 数据类型 | 所有元素类型必须一致 | 元素类型可任意混合 |
| 内存存储 | 数据地址连续,占用内存少 | 需存储元素指针,内存碎片化 |
| 运算效率 | 支持批量运算,无需循环 | 需遍历元素才能运算,效率低 |
| 功能支持 | 内置广播、矩阵运算 | 无原生数值计算优化 |
实战对比:Ndarray vs List
案例1:给所有元素加1
# Python列表:需循环遍历
a = [1, 2, 3, 4, 5]
for i in range(len(a)):
a[i] += 1
print(a) # 输出:[2, 3, 4, 5, 6]
# Ndarray:直接批量运算
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
arr = arr + 1 # 广播机制自动作用于所有元素
print(arr) # 输出:[2 3 4 5 6]
案例2:两个数组对应元素相加
# Python列表:需循环拼接
a = [1, 2, 3]
b = [4, 5, 6]
c = []
for i in range(len(a)):
c.append(a[i] + b[i])
print(c) # 输出:[5, 7, 9]
# Ndarray:直接符号运算
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = a + b # 对应元素自动相加
print(c) # 输出:[5 7 9]
三、Ndarray数组创建
NumPy提供了多种创建数组的函数,可根据需求选择,以下是最常用的6种方法:
3.1 array函数:从序列创建(最基础)
array()函数可将列表、元组等序列转换为Ndarray,支持指定数据类型、存储顺序等参数。
- 函数原型:
numpy.array(object, dtype=None, copy=True, order='K', ndmin=0) - 关键参数:
object:输入序列(列表、元组等);dtype:指定数据类型(如np.int32、np.float64),默认自动推断;ndmin:指定最小维度(如ndmin=2强制生成2维数组)。
实战代码:
import numpy as np
# 1. 创建1维数组
arr1 = np.array([1, 2, 3, 4, 5])
print("1维数组:", arr1, " 维度:", arr1.ndim) # 输出:[1 2 3 4 5] 维度:1
# 2. 创建2维数组(列表嵌套)
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print("2维数组:\n", arr2, " 维度:", arr2.ndim) # 输出:2行3列数组,维度:2
# 3. 指定数据类型
arr3 = np.array([1.1, 2.2], dtype=np.int32)
print("指定int32类型:", arr3) # 输出:[1 2](浮点数转整数)
3.2 arange函数
arange()按指定步长生成1维数组,支持整数、浮点数步长。
- 函数原型:
numpy.arange([start], stop[, step], dtype=None) - 规则:左闭右开(包含start,不包含stop)。
实战代码:
# 1. 生成0-9(默认start=0,step=1)
arr1 = np.arange(10)
print(arr1) # 输出:[0 1 2 3 4 5 6 7 8 9]
# 2. 生成5-14,步长2
arr2 = np.arange(5, 15, 2)
print(arr2) # 输出:[ 5 7 9 11 13]
# 3. 生成0-1,步长0.1(浮点数)
arr3 = np.arange(0, 1, 0.1)
print(arr3) # 输出:[0. 0.1 0.2 ... 0.9]
3.3 zeros/ones函数
zeros():创建指定形状的全0数组,默认浮点型;ones():创建指定形状的全1数组,用法与zeros()一致。
实战代码:
# 1. 1维全0数组(长度5)
arr1 = np.zeros(5)
print(arr1) # 输出:[0. 0. 0. 0. 0.]
# 2. 2维全1数组(3行2列)
arr2 = np.ones((3, 2), dtype=int) # 指定int类型
print(arr2) # 输出:[[1 1],[1 1],[1 1]]
3.4 empty函数
empty()创建指定形状的数组,但不初始化元素(元素为随机值),速度比zeros()快,适合后续手动填充数据。
实战代码:
# 创建2行3列空数组(int类型)
arr = np.empty((2, 3), dtype=int)
print(arr) # 输出:随机整数(如[[1 2 3],[4 5 6]],每次运行结果不同)
3.5 full函数
full()可自定义填充值,比zeros()和ones()更灵活。
实战代码:
# 1. 2行3列全为7的数组
arr1 = np.full((2, 3), 7)
print(arr1) # 输出:[[7 7 7],[7 7 7]]
# 2. 1行4列全为5.5的浮点数组
arr2 = np.full(4, 5.5, dtype=float)
print(arr2) # 输出:[5.5 5.5 5.5 5.5]
3.6 随机数组创建
NumPy的random模块提供了多种随机数组生成函数,需先理解随机数种子:设置种子(如np.random.seed(42))可让随机序列可重复,便于调试。
| 函数 | 功能 | 示例 |
|---|---|---|
rand(d0,d1,...) | 生成[0,1)均匀分布的随机浮点数 | np.random.rand(2,3) → 2行3列数组 |
randn(d0,d1,...) | 生成标准正态分布(均值0,标准差1)的浮点数 | np.random.randn(5) → 1维5元素数组 |
randint(low,high,size) | 生成[low,high)的随机整数 | np.random.randint(1,10,(3,3)) → 3行3列整数数组 |
uniform(low,high,size) | 生成[low,high)均匀分布的浮点数 | np.random.uniform(5,10,2) → [5.2, 8.7] |
normal(loc,scale,size) | 生成指定正态分布(loc=均值,scale=标准差)的浮点数 | np.random.normal(5,2,(2,2)) → 均值5、标准差2的2行2列数组 |
shuffle(x) | 随机打乱1维数组(原地修改) | np.random.shuffle(arr) → 打乱arr元素顺序 |
实战代码:
import numpy as np
# 设置随机种子(确保结果可重复)
np.random.seed(42)
# 1. 生成2行3列[0,1)随机浮点数
arr1 = np.random.rand(2, 3)
print("rand数组:\n", arr1)
# 2. 生成3行3列[1,10)随机整数
arr2 = np.random.randint(1, 10, (3, 3))
print("randint数组:\n", arr2)
# 3. 打乱1维数组
arr3 = np.array([1,2,3,4,5])
np.random.shuffle(arr3)
print("打乱后:", arr3) # 输出:[4 5 3 1 2]
输出结果
rand数组:
[[0.37454012 0.95071431 0.73199394]
[0.59865848 0.15601864 0.15599452]]
randint数组:
[[8 5 4]
[8 8 3]
[6 5 2]]
打乱后: [1 3 5 2 4]
四、Ndarray数组属性
Ndarray有4个核心属性,可快速获取数组的维度、形状、数据类型等信息:
| 属性 | 含义 | 示例(arr = np.array([[1,2],[3,4]])) |
|---|---|---|
shape | 数组形状(元组形式) | arr.shape → (2,2)(2行2列) |
dtype | 元素数据类型 | arr.dtype → int64 |
size | 元素总个数 | arr.size → 4 |
ndim | 数组维度 | arr.ndim → 2(二维数组) |
实战代码:
import numpy as np
# 创建2行3列数组
arr = np.array([[1, 2, 3], [4, 5, 6]], dtype=np.float32)
print("形状(shape):", arr.shape) # 输出:(2, 3)
print("数据类型(dtype):", arr.dtype) # 输出:float32
print("元素个数(size):", arr.size) # 输出:6
print("维度(ndim):", arr.ndim) # 输出:2
输出结果
形状(shape): (2, 3)
数据类型(dtype): float32
元素个数(size): 6
维度(ndim): 2
五、Ndarray索引与切片
索引用于访问单个元素,切片用于访问连续区域的元素,支持1维和多维数组。
5.1 1维数组
- 索引:从左到右0开始,从右到左-1开始;
- 切片:
start:stop:step(左闭右开,start/stop/step均可省略)。
实战代码:
import numpy as np
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 1. 索引:访问第5个元素(索引4)和最后一个元素(索引-1)
print("索引4:", arr[4]) # 输出:5
print("索引-1:", arr[-1]) # 输出:10
# 2. 切片:访问索引4-6(不包含7)
print("4:7切片:", arr[4:7]) # 输出:[5 6 7]
# 3. 切片:步长2,从索引1到6
print("1:6:2切片:", arr[1:6:2]) # 输出:[2 4 6]
# 4. 批量赋值:将切片区域设为6
arr[4:7] = 6
print("批量赋值后:", arr) # 输出:[1 2 3 4 6 6 6 8 9 10]
输出结果
索引4: 5
索引-1: 10
4:7切片: [5 6 7]
1:6:2切片: [2 4 6]
批量赋值后: [ 1 2 3 4 6 6 6 8 9 10]
5.2 多维数组
以2维数组为例,arr[row, col]或arr[row][col],切片时各维度独立设置。
实战代码:
import numpy as np
# 创建3行3列数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 1. 索引:访问第1行第2列(行0,列1)
print("(0,1)元素:", arr[0, 1]) # 输出:2
# 2. 切片:访问第1-2行(不包含3)、第0-1列(不包含2)
print("行1:3,列0:2:\n", arr[1:3, 0:2]) # 输出:[[4 5],[7 8]]
# 3. 切片:访问所有行、第0和2列(不连续列)
print("所有行,列[0,2]:\n", arr[:, [0, 2]]) # 输出:[[1 3],[4 6],[7 9]]
# 4. 切片:访问第0和2行、所有列(不连续行)
print("行[0,2],所有列:\n", arr[[0, 2], :]) # 输出:[[1 2 3],[7 8 9]]
输出结果:
(0,1)元素: 2
行1:3,列0:2:
[[4 5]
[7 8]]
所有行,列[0,2]:
[[1 3]
[4 6]
[7 9]]
行[0,2],所有列:
[[1 2 3]
[7 8 9]]
六、Ndarray形状与类型修改
6.1 数据类型修改
astype()可将数组转换为指定数据类型,返回新数组(不修改原数组)。
实战代码:
import numpy as np
# 1. 浮点数转整数
arr1 = np.array([1.1, 2.2, 3.3])
arr2 = arr1.astype(np.int32)
print("浮点数转整数:", arr2) # 输出:[1 2 3]
# 2. 整数转布尔值(0→False,非0→True)
arr3 = np.array([0, 1, 2])
arr4 = arr3.astype(np.bool_)
print("整数转布尔:", arr4) # 输出:[False True True]
输出结果
浮点数转整数: [1 2 3]
整数转布尔: [False True True]
6.2 形状修改
| 方法 | 功能 | 特点 |
|---|---|---|
reshape(newshape) | 重塑形状,元素总数不变 | 返回新数组,原数组不变 |
resize(newshape) | 重塑形状,元素总数可变 | 原地修改原数组(少则截断,多则补随机值) |
flatten(order='C') | 展平为1维数组 | 返回原数组副本(修改新数组不影响原数组) |
ravel(order='C') | 展平为1维数组 | 优先返回视图(修改新数组可能影响原数组),效率高 |
T | 数组转置(行变列,列变行) | 2维数组常用,返回视图 |
实战代码:
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]]) # 2行3列,元素总数6
# 1. reshape:2行3列→3行2列
arr1 = arr.reshape((3, 2))
print("reshape(3,2):\n", arr1) # 输出:3行2列数组,原数组不变
# 2. flatten:展平为1维
arr2 = arr.flatten()
print("flatten:", arr2) # 输出:[1 2 3 4 5 6]
# 3. 转置:2行3列→3行2列
arr3 = arr.T
print("转置(T):\n", arr3) # 输出:3行2列数组
# 4. ravel vs flatten:视图与副本差异
arr4 = arr.ravel()
arr4[0] = 100 # 修改ravel返回的数组
print("修改ravel后原数组:\n", arr) # 输出:[[100 2 3],[4 5 6]](原数组被修改)
arr5 = arr.flatten()
arr5[0] = 200 # 修改flatten返回的数组
print("修改flatten后原数组:\n", arr) # 输出不变(副本不影响原数组)
输出结果
reshape(3,2):
[[1 2]
[3 4]
[5 6]]
flatten: [1 2 3 4 5 6]
转置(T):
[[1 4]
[2 5]
[3 6]]
修改ravel后原数组:
[[100 2 3]
[ 4 5 6]]
修改flatten后原数组:
[[100 2 3]
[ 4 5 6]]
七、Ndarray广播机制
通常,数组运算要求形状完全一致,但NumPy的广播机制允许不同形状数组“兼容运算”,核心是自动扩展数组维度至一致,避免手动循环。
广播规则
- 若两数组维度不同,形状较小的数组在前面补1(如标量→(1,1),1维→(1,n));
- 若某维度长度为1,沿该维度复制扩展至与另一数组一致;
- 若任一维度长度既不相等也不为1,报错(无法兼容)。
实战案例
案例1:标量与2维数组相加
import numpy as np
# 2行3列数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 标量(形状视为())
scalar = 2
# 广播过程:
# 1. 标量补1→(1,1);
# 2. 沿行、列复制→(2,3)(与arr形状一致);
# 3. 对应元素相加。
result = arr + scalar
print("标量+数组:\n", result)
# 输出:
# [[3 4 5]
# [6 7 8]]
输出结果
标量+数组:
[[3 4 5]
[6 7 8]]
案例2:1维数组与2维数组相加
import numpy as np
# 2行3列数组
arr1 = np.zeros((3, 3)) # [[0,0,0],[0,0,0],[0,0,0]]
# 1维数组(形状(3,))
arr2 = np.ones((3, 1)) # [[1],[1],[1]](补1后为(3,1))
# 广播过程:
# 1. arr2形状(3,1),沿列复制→(3,3);
# 2. 对应元素相加。
result = arr1 + arr2
print("1维+2维数组:\n", result)
# 输出:
# [[1. 1. 1.]
# [1. 1. 1.]
# [1. 1. 1.]]
输出结果
1维+2维数组:
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
八、Ndarray数组运算
NumPy支持标量与数组、数组与数组的运算,可通过符号或函数实现。
8.1 标量与数组运算(依赖广播)
直接使用+、-、*、/符号,运算自动作用于所有元素。
实战代码:
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 加法:所有元素+2
print("数组+2:\n", arr + 2)
# 减法:所有元素-1
print("数组-1:\n", arr - 1)
# 乘法:所有元素*3
print("数组*3:\n", arr * 3)
# 除法:所有元素/2(浮点数)
print("数组/2:\n", arr / 2)
输出结果
数组+2:
[[3 4 5]
[6 7 8]]
数组-1:
[[0 1 2]
[3 4 5]]
数组*3:
[[ 3 6 9]
[12 15 18]]
数组/2:
[[0.5 1. 1.5]
[2. 2.5 3. ]]
8.2 数组与数组运算
(1)对应元素运算(形状完全一致)
使用+、-、*、/符号或np.add()、np.subtract()等函数,对应元素逐一运算。
实战代码:
import numpy as np
arr1 = np.array([[1, 2], [3, 4]])
arr2 = np.array([[5, 6], [7, 8]])
# 1. 符号运算:对应元素相加
print("arr1+arr2:\n", arr1 + arr2) # 输出:[[6 8],[10 12]]
# 2. 函数运算:对应元素相乘(np.multiply())
print("arr1*arr2:\n", np.multiply(arr1, arr2)) # 输出:[[5 12],[21 32]]
输出结果
arr1+arr2:
[[ 6 8]
[10 12]]
arr1*arr2:
[[ 5 12]
[21 32]]
(2)矩阵点积
矩阵点积是线性代数核心运算,需用np.dot(a, b),要求a的列数等于b的行数(如a(2,3)可与b(3,4)点积,结果为(2,4))。
实战代码:
import numpy as np
# 2行2列矩阵A
A = np.array([[1, 2], [3, 4]])
# 2行2列矩阵B(A的列数=B的行数=2,可点积)
B = np.array([[2, 0], [1, 3]])
# 矩阵点积:A[行]·B[列](对应元素相乘再求和)
result = np.dot(A, B)
print("矩阵点积:\n", result)
# 计算过程:
# 第1行第1列:1*2 + 2*1 = 4
# 第1行第2列:1*0 + 2*3 = 6
# 第2行第1列:3*2 + 4*1 = 10
# 第2行第2列:3*0 + 4*3 = 12
# 输出:[[4 6],[10 12]]
输出结果
矩阵点积:
[[ 4 6]
[10 12]]
九、Ndarray进阶操作
9.1 数组连接:4种常用函数
| 函数 | 功能 | 关键参数 |
|---|---|---|
concatenate((a1,a2), axis=0) | 沿现有轴连接数组 | axis=0(垂直)、axis=1(水平) |
stack((a1,a2), axis=0) | 沿新轴连接数组(增加维度) | axis=0(新轴在最前)、axis=1(新轴在中间) |
hstack((a1,a2)) | 水平连接(等价于concatenate(..., axis=1)) | 无需指定axis |
vstack((a1,a2)) | 垂直连接(等价于concatenate(..., axis=0)) | 无需指定axis |
实战代码:
import numpy as np
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6]])
# 1. vstack:垂直连接(行数增加)
v_result = np.vstack((a, b))
print("vstack:\n", v_result) # 输出:[[1 2],[3 4],[5 6]]
# 2. hstack:水平连接(列数增加,需先转置b)
h_result = np.hstack((a, b.T)) # b.T将b从(1,2)转为(2,1)
print("hstack:\n", h_result) # 输出:[[1 2 5],[3 4 6]]
输出结果
vstack:
[[1 2]
[3 4]
[5 6]]
hstack:
[[1 2 5]
[3 4 6]]
9.2 数组分割:3种常用函数
| 函数 | 功能 | 特点 |
|---|---|---|
split(ary, indices_or_sections, axis=0) | 沿指定轴分割数组 | 可指定分割数量或位置 |
hsplit(ary, ...) | 水平分割(沿axis=1) | 专门用于列分割 |
vsplit(ary, ...) | 垂直分割(沿axis=0) | 专门用于行分割 |
实战代码:
import numpy as np
# 创建1维数组
arr = np.array([1, 2, 3, 4, 5, 6])
# 1. split:平均分割为3个子数组
split1 = np.split(arr, 3)
print("平均分割3份:", split1) # 输出:[array([1,2]), array([3,4]), array([5,6])]
# 2. split:按位置[2,4]分割
split2 = np.split(arr, [2, 4])
print("按位置[2,4]分割:", split2) # 输出:[array([1,2]), array([3,4]), array([5,6])]
输出结果
平均分割3份: [array([1, 2]), array([3, 4]), array([5, 6])]
按位置[2,4]分割: [array([1, 2]), array([3, 4]), array([5, 6])]
9.3 统计计算
NumPy内置丰富的统计函数,支持沿指定轴计算,关键参数axis=0(按列)、axis=1(按行)。
| 函数 | 功能 | 示例(arr = [[1,2],[3,4]]) |
|---|---|---|
np.mean(arr) | 计算平均值 | np.mean(arr) → 2.5;np.mean(arr, axis=0) → [2, 3] |
np.sum(arr) | 计算总和 | np.sum(arr) → 10;np.sum(arr, axis=1) → [3, 7] |
np.max(arr)/np.min(arr) | 最大值/最小值 | np.max(arr) → 4;np.min(arr, axis=0) → [1, 2] |
np.var(arr) | 计算方差 | np.var(arr) → 1.25(衡量数据分散程度) |
np.std(arr) | 计算标准差 | np.std(arr) → 1.118(方差的平方根) |
np.argmax(arr)/np.argmin(arr) | 最大值/最小值索引 | np.argmax(arr) → 3;np.argmin(arr, axis=1) → [0, 0] |
实战代码:
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 1. 计算所有元素的平均值
print("全局均值:", np.mean(arr)) # 输出:5.0
# 2. 按列计算最大值
print("按列最大值:", np.max(arr, axis=0)) # 输出:[7 8 9]
# 3. 按行计算标准差
print("按行标准差:", np.std(arr, axis=1)) # 输出:[0.816 0.816 0.816]
# 4. 找出全局最小值的索引
print("全局最小值索引:", np.argmin(arr)) # 输出:0(对应元素1)
输出结果
全局均值: 5.0
按列最大值: [7 8 9]
按行标准差: [0.81649658 0.81649658 0.81649658]
全局最小值索引: 0
9.4 条件筛选
np.where(condition)返回满足条件的元素索引,可用于快速筛选数据。
实战代码:
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 筛选出大于5的元素索引
condition = arr > 5
row_idx, col_idx = np.where(condition)
print("大于5的元素索引:")
print("行索引:", row_idx) # 输出:[1 2 2 2]
print("列索引:", col_idx) # 输出:[2 0 1 2]
# 输出满足条件的元素
print("大于5的元素:", arr[row_idx, col_idx]) # 输出:[6 7 8 9]
输出结果
大于5的元素索引:
行索引: [1 2 2 2]
列索引: [2 0 1 2]
大于5的元素: [6 7 8 9]
十、总结与学习建议
NumPy 作为 Python 科学计算的核心库,凭借ndarray多维数组和高效运算能力,解决了原生列表在大规模数值计算中的性能瓶颈。从数组创建(如array、arange、随机数组生成等)、属性查看(shape、dtype等),到索引切片、广播机制、各类运算(标量与数组、数组与数组、矩阵点积等),再到进阶的连接、分割、统计与条件筛选操作,NumPy 提供了一套完整且高效的数值计算工具链。它不仅自身功能强大,还为 Pandas、SciPy、Matplotlib 等众多数据科学与机器学习库奠定了基础,是进入 Python 数据科学领域必须掌握的核心技能。



















 1952
1952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











