




 本文详细区分了Java内存模型(JMM)与JVM内存结构的概念,解释了两者之间的不同,并介绍了工作内存与主内存间的数据交互机制,以及如何通过内存屏障和volatile确保数据的一致性和可见性。
本文详细区分了Java内存模型(JMM)与JVM内存结构的概念,解释了两者之间的不同,并介绍了工作内存与主内存间的数据交互机制,以及如何通过内存屏障和volatile确保数据的一致性和可见性。
内存结构==内存模型??
前段时间在度娘上面想查查JVM的发展史的,后来就有一大片引荐文章,让我记忆最为深刻的是,看到很多文章将JVM的内存模型和内存结构混淆在一起的。

作为一名优秀的开发人员,JVM的内存模型和内存结构是一定要区分开来的,因为这俩者的根本就不是一个概念,而且这俩者的区别是非常非常的大的。
JVM的发展历程:https://blog.youkuaiyun.com/qq_45057072/article/details/106977794?utm_medium=distribute.pc_relevant.none-task-blog-title-9&spm=1001.2101.3001.4242 提供简单了解。
本篇文章首先简单介绍内存模型:

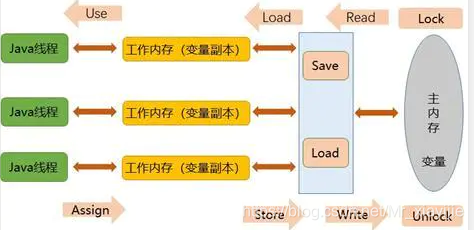
上面这幅图就是内存模型这么一个结构,看到这里很多人也很熟悉了,这就是我们所熟悉的JMM(JAVA Memory Model)
其实内存模型就是工作内存和主内存之间数据交互这一套关系
Java线程:若开发人员自己不定义Thread的话 那么所有的方法都在主线程中执行,开发人员通过继承Thread或者实现Runnable进行多个多线程开发
工作内存:在上面的图中可以理解cpu中的高速缓存,但是工作内存真正的含义是:缓存、写缓冲区、寄存器以及其他硬件和编译器优化,高速内存只是其中的一部分。
主内存:就是我们平时硬件上所说的运行内存即本地内存,区别于磁盘其相当于高速缓冲区,用于与cpu中的高速缓存进行数据交互
cpu中的高速缓存:由于现在cpu发展的迅速,出现多核cpu,因为cpu和内存的交互也最为频繁,但是内存的读写数据往往是赶不上cpu的,所以为了解决这一快一慢的矛盾<缓存一致性>,多核cpu在每个cpu上加上了高速缓存,cpu高速缓存和内存的关系这里可以理解成redis和mysql或者其他DB之间的关系,当然意义肯定不一样,只是相似类比。
比如:多核cpu,3个cpu(L1、L2、L3三个高速缓存),当cpu读取一个数据的时候首先从L1中找,L1没有再找L2依次类推,最后高速缓存中都没有的话就从主内存中获取出来放到自己对应的高速缓存中。
那么问题来了:
高速缓存去对应的内存区域中获取数据的时候,这里会引申出一个问题,不同高速缓存获取了同一内存区域进行数据操作后然后再写入内存,那么这里就涉及到一个可见性的问题。
模拟流程:
1.L1 Read变量A=0于主内存Load工作内存(高速缓存)到->Java线程1
最后Use到Java线程1中将变量A+1 =2 再Assign(赋值)到工作内存(高速缓存)再Store(存储)到内存再Write入到内存 ,那么现在内存中变量A=2
2.重点:在上一步操作的时候A=2还未写入到内存中这时候L2 Read变量A=0于主内存Load工作内存(高速缓存)->Java线程2
3.那么Java线程2获取的A还是为0,然后将变量A加1 A=1 再Assign到工作内存(高速缓存)再Store(存储)到内存再Write入到内存 ,那么现在内存中变量A=1
那么按正常逻辑来说肯定是不正确的,因为L1和L2都是操作的同一变量,那么这里必然是一个先后顺序,正确结果应该为3

有问题的地方就肯定有很多解决方案,有问题我们就解决问题:
那么解决方案如下:
内存屏障:缓存一致性协议(MESI):
这是属于硬件层的,分俩种:LoadBarrier(读屏障)和StoreBarrier(写屏障),作用是强制让高速缓存也就是工作内存中对应的数据清空再从主内存中获取
如上图说明就是:
1.Java线程1将变量A=2写入主内存之前加一个StoreBarrier即lock加锁,防止还没写入就被其他的cpu读取了,write后再unlock释放锁
2.Java线程2再去读取前加一个LoadBarrier首先将L2中的A先清空,再从主内存获取A=2再进行操作
常用字段volatile(可见性):修饰变量,其原理也就是在变量进行写操作的时候会促发MESI协议,会存在一个总线嗅探机制,一旦这个嗅探到变量发生了变化,那么会将其他cpu中缓存的该变量清空掉,强制重新获取主内存数据,这里要注意:变量A++为原子操作,这里就没用了,可以加锁解决。
内存结构:
这里其实JMM中所说的主内存其实就是这个内存结构整个大块: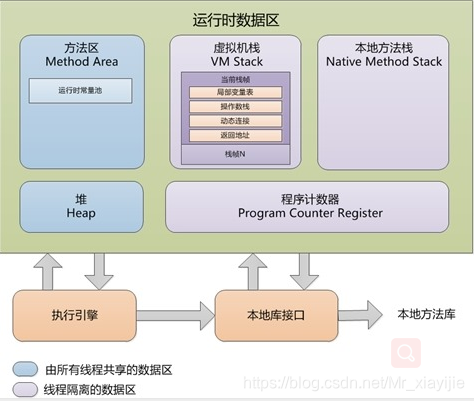
那么最后的结论是:内存模型包含了内存结构 即内存模型>内存结构
由于内容篇幅,就不拉那么长了,后续我们再介绍内存结构。
内存结构地址:https://blog.youkuaiyun.com/Mr_xiayijie/article/details/109311924

















 1324
1324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









