



基础介绍
距离上次写作已经过去3年,还是要保持写作的习惯。
本人从事金融科技行业,有4年左右的数据平台产品经理经验,25年3月起陆续面试了几家公司,写一下面试总结及知识点。
建发 厦门
安踏 厦门
平安银行 深圳
招商银行 深圳
面试的Q&A总结
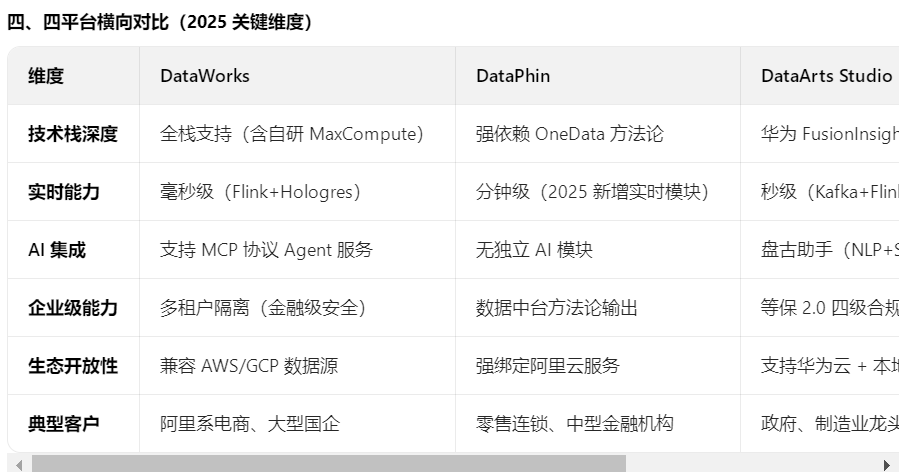
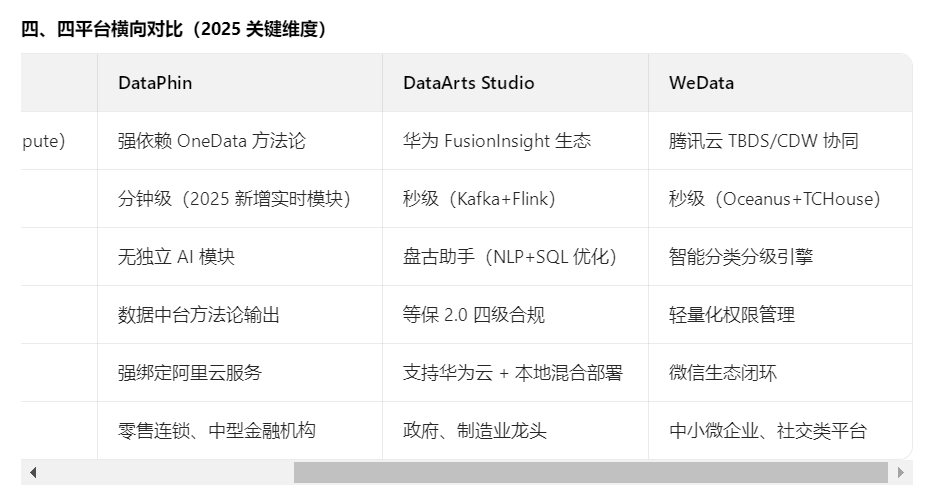
1)是否了解市面上的其他大数据平台,比如阿里的dataworks,dataphin,华为云DataArts Studio、腾讯云WeData
答:
平台能力对比
| 平台 | 核心定位 | 关键能力 | 适用场景 |
|---|---|---|---|
| 阿里云DataWorks | 一站式开发治理平台 | 数据集成(50+数据源)、可视化编排、千万级调度、智能诊断(Copilot)、全链路血缘管理 | 高并发企业级数据流水线(如电商实时分析) |
| 阿里云Dataphin | 数据资产构建与管理 | 自动化数据建模、指标标准化、资产质量管控(需与DataWorks协同使用) | 大型企业中台建设与资产规范化治理 |
| 华为DataArts Studio | 行业化数据治理中心 | 行业知识库(政务/税务)、可视化数据架构设计、全生命周期质量监控、安全分级分类 | 政府及传统企业合规性数据治理 |
| 腾讯云WeData | 全链路敏捷开发平台 | 统一元数据管理、低代码编排、异构算力调度(ClickHouse/Flink)、DataOps协作 | 金融/泛互联网实时分析与快速迭代场景 |
⚙️ 二、架构与技术特点
-
计算引擎支持
- DataWorks:深度集成MaxCompute,支持Flink实时计算、EMR开源引擎,满足EB级离线/实时处理 。
- DataArts Studio:依托MRS Hive/DWS数据仓库,强调查算分离湖仓架构 。
- WeData:通过TBDS套件整合ClickHouse、Oceanus流计算,优化实时查询性能(如QQ音乐分析提速至秒级)。
-
智能化与自动化
- DataWorks Copilot:支持SQL生成/优化、UDF转换、血缘分析,降低开发门槛 。
- DataArts:基于行业模板自动生成数据标准与质量规则,减少人工配置 。
- WeData:智能血缘分析驱动数据变更影响评估,提升协作效率 。
-
治理与安全
- DataWorks:双环境隔离(开发/生产)、敏感数据识别(保护伞)、脱敏策略 。
- DataArts:提供端到端数据安全生命周期管理,支持隐私合规审计 。
- WeData:通过神盾联邦计算实现跨企业安全数据融合 。
🏭 三、行业解决方案与落地案例
- DataWorks:
婚礼纪实现湖仓一体架构,用户行为日志处理效率提升50%,支撑日均5亿条数据分析 。 - WeData:
中金财富证券采用DataOps模式,数据交付周期缩短50%,日调度超万任务,通过DCMM三级认证 。 - DataArts Studio:
某市出租车数据治理案例中,完成收入统计、支付分析等场景的标准化建模与质量监控 。
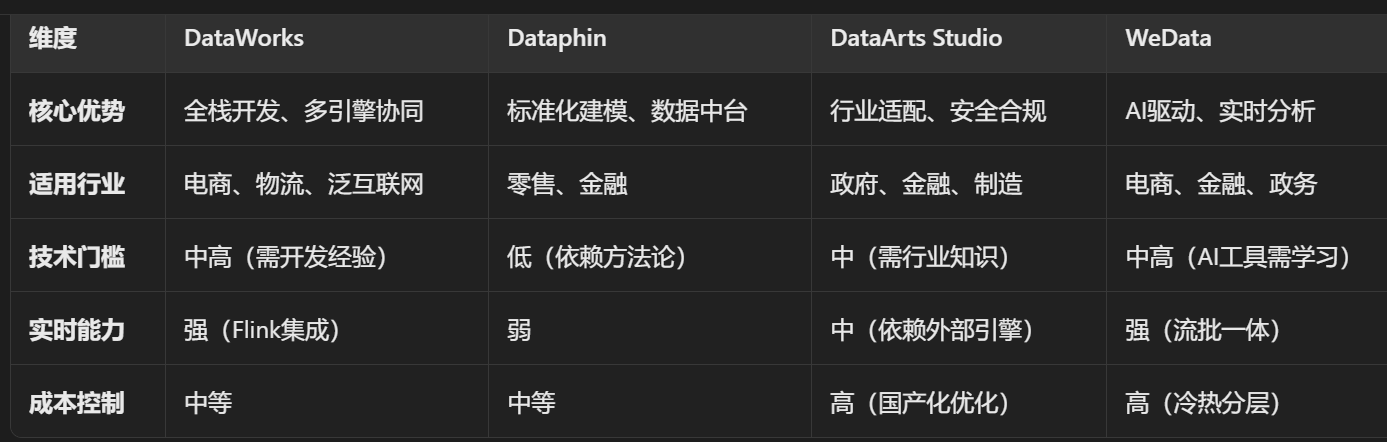
🎯 四、差异化优势总结
| 平台 | 核心优势 |
|---|---|
| DataWorks | 超大规模调度稳定性(双11验证)、AI增强开发体验 |
| Dataphin | 企业级资产规范管理(补充DataWorks治理深度) |
| DataArts Studio | 垂直行业知识库复用、政府合规性支持 |
| WeData | DataOps敏捷协作、异构算力弹性扩展、金融场景优化 |
综上:
dataworks
偏开发,一站式大数据开发治理平台,覆盖数据集成、开发、运维、治理全链路,支持 Hadoop/Spark/Flink 等主流引擎。
AI 驱动升级:2025 年推出 DataWorks Agent,支持自然语言交互自动完成数据集成、任务运维等工作,SQL 生成效率提升 60%。
实时计算增强:整合 Flink 和 Hologres,实现流批一体处理,实时数仓查询延迟降至毫秒级。
应用在电商、物流场景居多,
DataPhin
数据中台的方法论落地,偏资产管理平台,输出阿里“OneData+OneID+OneService”方法论,专注数据资产治理与标准化建模。
核心定位:基于阿里 “OneData” 方法论的智能数据构建平台,强制维度建模规范,降低数据仓库建设门槛。
技术亮点:
零代码建模:通过业务板块→数据域→原子指标的层级设计,自动生成 SQL 代码,开发周期缩短 70%。
实时能力突破:2025 年新增 Flink 实时流处理模块,支持订单状态实时同步(如盒马鲜生)。
资产运营:内置数据地图和指标中台,支持跨部门指标共享(如集团统一 “GMV” 定义)。
华为云 DataArts Studio
企业级治理的标杆,偏政务处理类
全生命周期数据治理平台,主打库仓湖智一体化,尤其擅长政务、制造业等合规性要求高的场景
AI 增强治理:盘古助手实现自然语言 SQL 生成(准确率 85%)、SQL 优化(执行效率提升 30%)和数据质量自动修复
典型案例:
智慧物流:某头部物流企业通过 DataArts Studio 构建 Hudi 数据湖,实现订单数据准实时入库(延迟 < 5 分钟),支撑智能配送调度。
政务大数据:某省政务云平台接入 30 + 委办局数据,通过 DataArts Studio 实现数据分类分级(覆盖 500 + 敏感字段)和跨部门共享。
腾讯云 WeData 轻量化
轻量化数据开发治理平台,深度绑定微信生态,适合中小微企业快速落地数据应用
微信生态联动:无缝对接企业微信审批流、小程序支付数据,支持用户行为分析(如公众号粉丝画像)
偏金融类
未来趋势洞察
AI 原生融合:2025 年各平台均推出 AI 助手(如 DataWorks Agent、盘古助手),预计 2026 年实现 80% 常规任务自动化。
湖仓一体普及:DataArts Studio 的 Hudi 集成、DataWorks 的 Hologres 整合显示,混合存储架构成为主流,查询性能提升 3 倍。
边缘计算协同:腾讯云 WeData 支持边缘节点数据预处理,华为云推出边缘数据网关,预计 2026 年边缘端数据处理占比达 30%。
开源生态博弈:阿里开源 MaxCompute 部分组件,华为贡献 FusionInsight 社区,腾讯开放 WeData 低代码引擎,争夺开发者话语权
2)大数据平台的底层架构
我们做的应用级平台是mysql+
3)mpp的底层数据库
Spark:熟悉SparkCore和SparkSQL模块,能够使用Spark进行数据开发,并进行基本性能调优。Hadoop:熟悉Hadoop生态体系架构,理解HDFS、MapReduce以及YARN的原理。
Hive:熟悉Hive执行原理和常用函数,能够使用Hive SQL进行离线开发业务并进行基本的调优。Flink:掌握Flink流批一体架构,具备实时数据开发经验。
Zookeeper:了解Zookeeper的架构、工作方式及原理。
HBase:了解HBase的架构、存储原理、数据模型及RowKey设计原理。
Kafka:了解Kafka的架构,理解高性能、高可用性和高扩展性的原理。
Java:熟练Java相关知识,能够使用Java进行大数据开发。
Scala:熟悉Scala的基本语法,能够使用Scala进行大数据开发。
熟练掌握 Hadoop 体系架构,
包括 HDFS(文件分区存储,一般把历史数据存放于此)
MapReduce 计算框架工作原理(分成map和reduce)
Yarn 资源调度,具备构建 Hive 数仓经验,同时熟悉 Zookeeper、Spark、Kafka 等数据处理相关工具
4)你在项目中主要扮演了什么角色
事后回想应该要突出自己的产品功能设计,例如参考了什么平台,引用了什么技术,实现了什么价值,而不是直接说都是自己做的,没有什么重点
其次要突出自己的协调和管理能力,对接多少团队,管理多少开发,在什么期限内做完
5)数据治理体系了解多少
数据标准、数据质量、数据安全、数据运营(时效等)
6)dcmm是什么知道吗
DCMM将数据管理能力划分为8个核心领域,覆盖数据全生命周期管理:
数据战略:规划数据目标与实施路径;
数据治理:建立组织架构与制度规范;
数据架构:设计数据模型、集成与元数据管理;
数据应用:支持分析、开放共享与服务化;
数据安全:制定策略、实施管控与审计;
数据质量:定义标准、监控问题并持续提升;
数据标准:统一业务术语、主数据和指标;
数据生存周期:管理从需求到退役的全流程。
7)支付系统
8)信贷信息,贷前、贷中、贷后
9)什么是区块链、冷钱包、热钱包
10)什么是web3,Cefi、Defi、NFT、DAO等有深刻理解
11)决策引擎工具:Experian SMG3、Blaze、sds是否有了解
12)架构设计(mysql+es+arrangodb+敏捷框架)
13)常见风险策略有哪些

















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









