






 本文汇总了Flink面试中的常见问题,涵盖实时任务提交、压力测试、容错机制等核心知识点,旨在帮助读者深入理解Flink的工作原理和技术细节。
本文汇总了Flink面试中的常见问题,涵盖实时任务提交、压力测试、容错机制等核心知识点,旨在帮助读者深入理解Flink的工作原理和技术细节。
随着近几年大数据的飞速发展,不仅对数据量的存储和计算有着非常高的要求,在实时性方面,也是有着很高的要求。说到实时性,就不得不说到Flink了。在Flink发展的如火如荼的今天,也相信有许多公司在使用。这个小编在今年面试的时候深有体会,虽然也被问得一头雾水~~哈哈。接下来小编就分享一篇关于Flink的必备面试题。希望在复习的同时也能帮助到大家。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!
小编博客主页:https://blog.youkuaiyun.com/Mr_Yang888
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好。因为我相信,努力就会有希望。如果你的内在一直成长,那么你早晚会破土而出
码字不易,先赞再看,养成习惯~~~

文章目录
- Flink面试题汇总
- 1.在日常开发过程中,公司使用哪种方式提交的实时任务,有多少Job Manager、Task Manager?
- 2.怎么做压力测试和监控?
- 3.为什么使用 Flink 替代 Spark?
- 4.checkpoint 的存储?
- 5.如果下级存储不支持事务,Flink 怎么保证 exactly-once?
- 6.说一下 Flink 状态机制?
- 7.怎么去重?考虑一个实时场景:双十一场景,滑动窗口长度为 1 小时, 滑动距离为 10 秒钟,亿级用户,怎样计算 UV?(考点:海量key去重)
- 8.:Flink 的 checkpoint 机制对比 spark 有什么不同和优势?
- 9.请详细解释一下 Flink 的 Watermark 机制。
- 10.Flink 中 exactly-once 语义是如何实现的,状态是如何存储的?
- 11.Flink CEP 编程中当状态没有到达的时候会将数据保存在哪里?
- 12.Flink 三种时间语义是什么,分别说出应用场景?
- 13.Flink 程序在面对数据高峰期时如何处理?
- 14.Flink相比传统的Spark Streaming区别?
- 15.Flink的组件栈有哪些?
- 16.你们的Flink集群规模多大?
- 17.Flink的基础编程模型了解吗?
- 18、Flink集群有哪些角色?各自有什么作用?
- 19、说说 Flink 资源管理中 Task Slot 的概念
- 20、说说 Flink 的常用算子?
- 21、说说 Flink 的常用算子?
- 22、Flink的Slot和parallelism有什么区别?
- 23.Flink有没有重启策略?说说有哪几种?
- 24.用过Flink中的分布式缓存吗?如何使用?
- 25.说说Flink中的广播变量,使用时需要注意什么?
- 26.说说Flink中的状态存储?
- 27.Flink中的时间有哪几类?
- 28. Flink 中水印是什么概念,起到什么作用?
- 29. Flink Table & SQL 熟悉吗?TableEnvironment这个类有什么作用
Flink面试题汇总
1.在日常开发过程中,公司使用哪种方式提交的实时任务,有多少Job Manager、Task Manager?
答:
- 我们使用的是yarn session模式提交任务;这一种方式时每次提交都会创建一个新的Flink集群,为每一个job提供资源,且任务之间相互独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。线上命令脚本如下:
bin/yarn-session.sh -n 7 -s 8 -jm 3072 -tm 32768 -qu root.*.* -nm *-* -d
其中申请了7个taskManager。每个8核,每个taskmanager有32G内存。
- 集群只有一个Job Manager。但是为了防止单点故障,我们配置了高可用。对于standlone模式,我们公司一般配置一个主Job Manager,两个备用 Job Manager,然后结合 ZooKeeper 的使用,来达到高可用;对于 yarn 模式,yarn 在 Job Mananger 故障会自动进行重启,所以只需要一个,我们配置的最大重启次数是 10 次。
2.怎么做压力测试和监控?
答:
- 产生数据流的速度如果过快,而下游的算子消费不过来的话,会产生背压。 背压的监控可以使用 Flink Web
UI(localhost:8081) 来可视化监控 Metrics,一旦报警 就能知道。一般情况下背压问题的产生可能是由于 sink 这个
操作符没有优化好, 做一下优化就可以了。比如如果是写入 ElasticSearch, 那么可以改成批量写入, 可以调大
ElasticSearch 队列的大小等等策略。 - 设置 watermark 的最大延迟时间这个参数,如果设置的过大,可能会造成内存的压力。可以设置最大延迟时间小一些,然后把迟到元素发送到侧输出流中去。 晚一点更新结果。或者使用类似于 RocksDB这样的状态后端, RocksDB 会开辟 堆外存储空间,但 IO 速度会变慢,需要权衡。
- 还有就是滑动窗口的长度如果过长,而滑动距离很短的话,Flink 的性能会下降的很厉害。我们主要通过时间分片的方法,将每个元素只存入一个“重叠窗 口”,这样就可以减少窗口处理中状态的写入。
3.为什么使用 Flink 替代 Spark?
答:
主要考虑的是flink的低延迟、高吞吐量和对流式数据应用场景更好的支持;另外,flink可以很好地处理乱序数据,而且可以保证exactly-once的状态一致性。
4.checkpoint 的存储?
答:
可以是内存中,磁盘上,rocksDB上。
- MemoryStateBackend
内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储 在 TaskManager 的 JVM 堆上;而将 checkpoint 存储在 JobManager 的内存中。 - FsStateBackend
将 checkpoint 存到远程的持久化文件系统(FileSystem)上。而对于本地状态, 跟 MemoryStateBackend 一样,也会存在 TaskManager 的 JVM 堆上。 - RocksDBStateBackend
将所有状态序列化后,存入本地的 RocksDB 中存储。
5.如果下级存储不支持事务,Flink 怎么保证 exactly-once?
答:
端到端的 exactly-once 对 sink 要求比较高,具体实现主要有幂等写入和 事务性写入两种方式。幂等写入的场景依赖于业务逻辑,更常见的是用事务性写入。 而事务性写入又有预写日志(WAL)和两阶段提交(2PC)两种方式。
如果外部系统不支持事务,那么可以用预写日志的方式,把结果数据先当成状 态保存,然后在收到 checkpoint 完成的通知时,一次性写入 sink 系统。
6.说一下 Flink 状态机制?
答:
Flink 内置的很多算子,包括源 source,数据存储 sink 都是有状态的。在 Flink 中,状态始终与特定算子相关联。Flink 会以 checkpoint 的形式对各个任务的 状态进行快照,用于保证故障恢复时的状态一致性。Flink 通过状态后端来管理状态 和 checkpoint 的存储,状态后端可以有不同的配置选择。
7.怎么去重?考虑一个实时场景:双十一场景,滑动窗口长度为 1 小时, 滑动距离为 10 秒钟,亿级用户,怎样计算 UV?(考点:海量key去重)
答:
使用类似于 scala 的 set 数据结构或者 redis 的 set 显然是不行的, 因为可能有上亿个 Key,内存放不下。所以可以考虑使用布隆过滤器(Bloom Filter) 来去重
8.:Flink 的 checkpoint 机制对比 spark 有什么不同和优势?
答:
spark streaming 的 checkpoint 仅仅是针对 driver 的故障恢复做了数据 和元数据的 checkpoint。而 flink 的 checkpoint 机制 要复杂了很多,它采用的是 轻量级的分布式快照,实现了每个算子的快照,及流动中的数据的快照。
参见文档 9.3 节及文章链接: https://cloud.tencent.com/developer/article/1189624
9.请详细解释一下 Flink 的 Watermark 机制。
答:
Watermark 本质是 Flink 中衡量 EventTime 进展的一个机制,主要用来处 理乱序数据
10.Flink 中 exactly-once 语义是如何实现的,状态是如何存储的?
答:
Flink 依靠 checkpoint 机制来实现 exactly-once 语义,如果要实现端到端 的 exactly-once,还需要外部 source 和 sink 满足一定的条件。状态的存储通过状态 后端来管理,Flink 中可以配置不同的状态后端。
11.Flink CEP 编程中当状态没有到达的时候会将数据保存在哪里?
答:
Flink CEP 编程中当状态没有到达的时候会将数据保存在哪里? 解答:在流式处理中,CEP 当然是要支持 EventTime 的,那么相对应的也要 支持数据的迟到现象,也就是 watermark 的处理逻辑。CEP 对未匹配成功的事件序 列的处理,和迟到数据是类似的。在 Flink CEP 的处理逻辑中,状态没有满足的和 迟到的数据,都会存储在一个 Map 数据结构中,也就是说,如果我们限定判断事件 序列的时长为 5 分钟,那么内存中就会存储 5 分钟的数据,这在我看来,也是对内 存的极大损伤之一。
12.Flink 三种时间语义是什么,分别说出应用场景?
答:
- Event Time:是事件创建的时间。这是实际应用最常见的时间语义。
- Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器 相关,默认的时间属性就是 Processing Time。没有事件时间的情况下,或者对实时性要求超高的情况下。
- Ingestion Time:存在多个 Source Operator 的情况下,每个 Source Operator 可以使用自己本地系统时钟指派 Ingestion Time是数据进入 Flink 的时间。后续基于时间相关的各种操作, 都会使用数据记录中的 Ingestion Time。
13.Flink 程序在面对数据高峰期时如何处理?
答:
使用大容量的 Kafka 把数据先放到消息队列里面作为数据源,再使用 Flink 进行消费,不过这样会影响到一点实时性
14.Flink相比传统的Spark Streaming区别?
答:
1.Flink是标准的实时流处理引擎,基于事件驱动。实时流是一种无界的流,离线是一种有界的流。而Spark Streaming是微批处理。实时流是一种微批次处理,离线是一种大批次处理。
2. 架构模型Spark Streaming 在运行时的主要角色包括:Master、Worker、Driver、Executor,Flink 在运行时主要包含:Jobmanager、Taskmanager和Slot。
3. 任务调度Spark Streaming 连续不断的生成微小的数据批次,构建有向无环图DAG,Spark Streaming 会依次创建 DStreamGraph、JobGenerator、JobScheduler。Flink 根据用户提交的代码生成 StreamGraph,经过优化生成 JobGraph,然后提交给 JobManager进行处理,JobManager 会根据 JobGraph 生成 ExecutionGraph,ExecutionGraph 是 Flink 调度最核心的数据结构,JobManager 根据 ExecutionGraph 对 Job 进行调度。
4. 时间机制Spark Streaming 支持的时间机制有限,只支持处理时间。 Flink 支持了流处理程序在时间上的三个定义:处理时间、事件时间、注入时间。同时也支持 watermark 机制来处理滞后数据。
5. 容错机制对于 Spark Streaming 任务,我们可以设置 checkpoint,然后假如发生故障并重启,我们可以从上次 checkpoint 之处恢复,但是这个行为只能使得数据不丢失,可能会重复处理,不能做到恰好一次处理语义。Flink 则使用两阶段提交协议来解决这个问题。
15.Flink的组件栈有哪些?
答:
根据 Flink 官网描述,Flink 是一个分层架构的系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件。
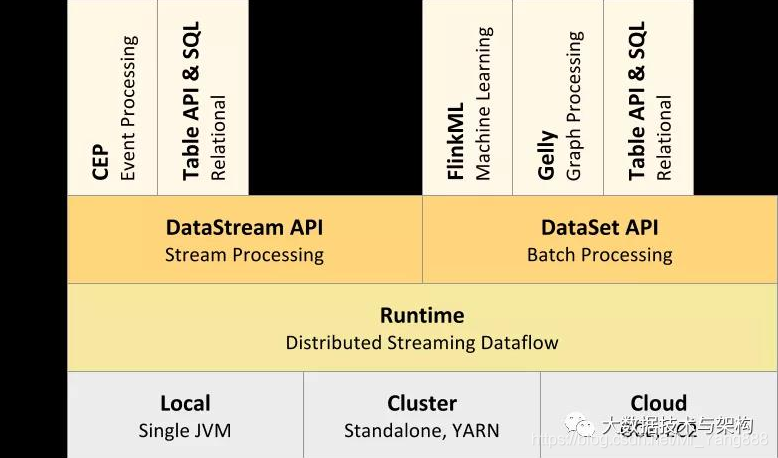
自下而上,每一层分别代表:
Deploy 层: 该层主要涉及了Flink的部署模式,在上图中我们可以看出,Flink 支持包括local、Standalone、Cluster、Cloud等多种部署模式。
Runtime 层: Runtime层提供了支持 Flink 计算的核心实现,比如:支持分布式 Stream 处理、JobGraph到ExecutionGraph的映射、调度等等,为上层API层提供基础服务。
API层: API 层主要实现了面向流(Stream)处理和批(Batch)处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API,后续版本,Flink有计划将DataStream和DataSet API进行统一。
Libraries层: 该层称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理支持:FlinkML(机器学习库)、Gelly(图处理)。
16.你们的Flink集群规模多大?
答:
大家注意,这个问题看起来是问你实际应用中的Flink集群规模,其实还隐藏着另一个问题:Flink可以支持多少节点的集群规模?在回答这个问题时候,可以将自己生产环节中的集群规模、节点、内存情况说明,同时说明部署模式(一般是Flink on Yarn),除此之外,用户也可以同时在小集群(少于5个节点)和拥有 TB 级别状态的上千个节点上运行 Flink 任务。
17.Flink的基础编程模型了解吗?
答:
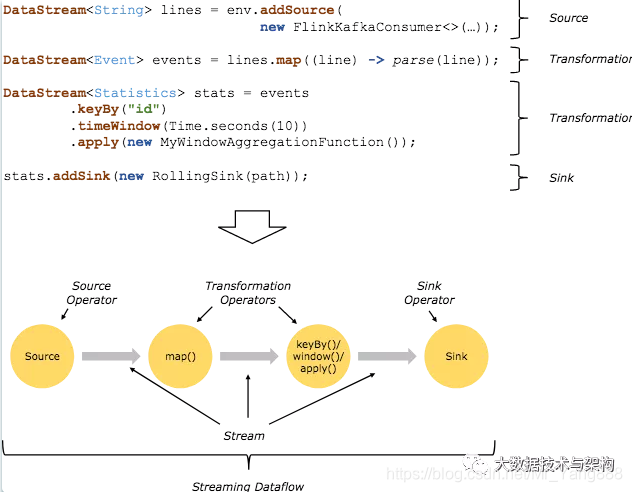
上图是来自Flink官网的运行流程图。通过上图我们可以得知,Flink 程序的基本构建是数据输入来自一个 Source,Source 代表数据的输入端,经过 Transformation 进行转换,然后在一个或者多个Sink接收器中结束。数据流(stream)就是一组永远不会停止的数据记录流,而转换(transformation)是将一个或多个流作为输入,并生成一个或多个输出流的操作。执行时,Flink程序映射到 streaming dataflows,由流(streams)和转换操作(transformation operators)组成。
18、Flink集群有哪些角色?各自有什么作用?
答:
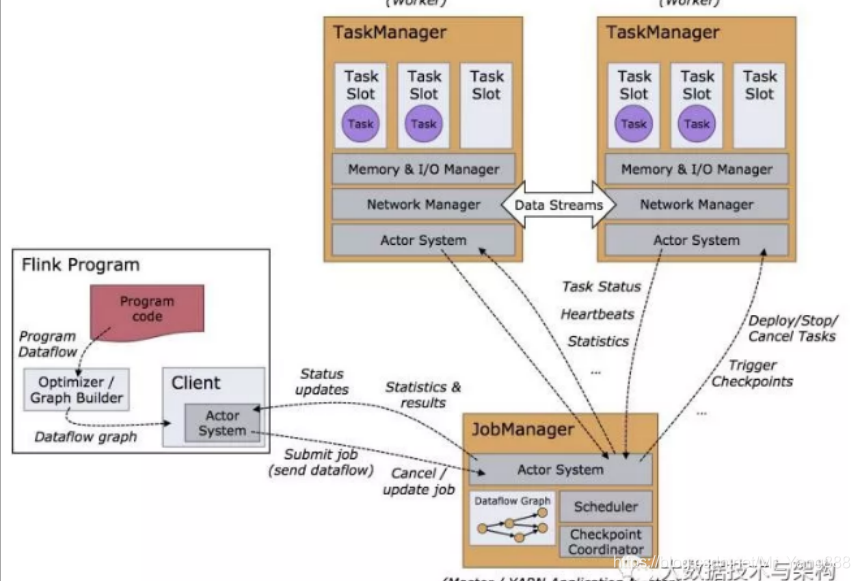
Flink 程序在运行时主要有 TaskManager,JobManager,Client三种角色。
JobManager:JobManager扮演着集群中的管理者Master的角色,它是整个集群的协调者,负责接收Flink Job,协调检查点,Failover 故障恢复等,同时管理Flink集群中从节点TaskManager。
TaskManager:TaskManager是实际负责执行计算的Worker,在其上执行Flink Job的一组Task,每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报。
Client:Client是Flink程序提交的客户端,当用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处理,所以Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给JobManager。
19、说说 Flink 资源管理中 Task Slot 的概念
答:
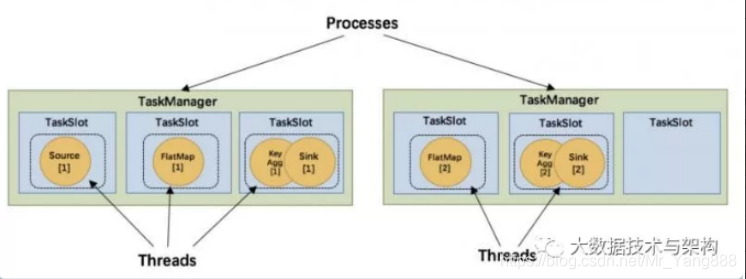
在Flink架构角色中我们提到,TaskManager是实际负责执行计算的Worker,TaskManager 是一个 JVM 进程,并会以独立的线程来执行一个task或多个subtask。为了控制一个 TaskManager 能接受多少个 task,Flink 提出了 Task Slot 的概念。简单的说,TaskManager会将自己节点上管理的资源分为不同的Slot:固定大小的资源子集。这样就避免了不同Job的Task互相竞争内存资源,但是需要主要的是,Slot只会做内存的隔离。没有做CPU的隔离。
20、说说 Flink 的常用算子?
答:
map:可以理解为映射,对每个元素进行一定的变换后,映射为另一个元素。
flatmap:可以理解为将元素摊平,每个元素可以变为0个、1个、或者多个元素。
filter:条件筛选,返回结果为true的
keyBy:逻辑上将Stream根据指定的Key进行分区,是根据key的散列值进行分区的。
reduce:reduce是归并操作,它可以将KeyedStream 转变为 DataStream。
fold:给定一个初始值,将各个元素逐个归并计算。它将KeyedStream转变为DataStream。
union:union可以将多个流合并到一个流中,以便对合并的流进行统一处理。是对多个流的水平拼接。参与合并的流必须是同一种类型。
join:根据指定的Key将两个流进行关联。
coGroup:关联两个流,关联不上的也保留下来。
connect:将两个流纵向地连接起来。DataStream的connect操作创建的是ConnectedStreams或BroadcastConnectedStream,它用了两个泛型,即不要求两个dataStream的element是同一类型。
split:将一个流拆分为多个流。
21、说说 Flink 的常用算子?
答:
Flink中的任务被分为多个并行任务来执行,其中每个并行的实例处理一部分数据。这些并行实例的数量被称为并行度。我们在实际生产环境中可以从四个不同层面设置并行度:
操作算子层面(Operator Level)
执行环境层面(Execution Environment Level)
客户端层面(Client Level)
系统层面(System Level)
需要注意的优先级:算子层面>环境层面>客户端层面>系统层面。
22、Flink的Slot和parallelism有什么区别?
答:
- slot是指taskmanager的并发执行能力,假设我们将 taskmanager.numberOfTaskSlots 配置为3那么每一个 taskmanager 中分配3个 TaskSlot, 3个 taskmanager 一共有9个TaskSlot。
- parallelism是指taskmanager实际使用的并发能力。假设我们把 parallelism.default 设置为1,那么9个 TaskSlot 只能用1个,有8个空闲。
23.Flink有没有重启策略?说说有哪几种?
答:
Flink 实现了多种重启策略。
- 固定延迟重启策略(Fixed Delay Restart Strategy)
- 故障率重启策略(Failure Rate Restart Strategy)
- 没有重启策略(No Restart Strategy)
- Fallback重启策略(Fallback Restart Strategy)
24.用过Flink中的分布式缓存吗?如何使用?
答:
Flink实现的分布式缓存和Hadoop有异曲同工之妙。目的是在本地读取文件,并把他放在 taskmanager 节点中,防止task重复拉取。
25.说说Flink中的广播变量,使用时需要注意什么?
答:
我们知道Flink是并行的,计算过程可能不在一个 Slot 中进行,那么有一种情况即:当我们需要访问同一份数据。那么Flink中的广播变量就是为了解决这种情况。我们可以把广播变量理解为是一个公共的共享变量,我们可以把一个dataset 数据集广播出去,然后不同的task在节点上都能够获取到,这个数据在每个节点上只会存在一份。
26.说说Flink中的状态存储?
答:
Flink在做计算的过程中经常需要存储中间状态,来避免数据丢失和状态恢复。选择的状态存储策略不同,会影响状态持久化如何和 checkpoint 交互。Flink提供了三种状态存储方式:MemoryStateBackend、FsStateBackend、RocksDBStateBackend。
27.Flink中的时间有哪几类?
答:
Flink 中的时间和其他流式计算系统的时间一样分为三类:事件时间,摄入时间,处理时间三种。如果以 EventTime 为基准来定义时间窗口将形成EventTimeWindow,要求消息本身就应该携带EventTime。如果以 IngesingtTime 为基准来定义时间窗口将形成 IngestingTimeWindow,以 source 的systemTime为准。如果以 ProcessingTime 基准来定义时间窗口将形成 ProcessingTimeWindow,以 operator 的systemTime 为准。
28. Flink 中水印是什么概念,起到什么作用?
答:
Watermark 是 Apache Flink 为了处理 EventTime 窗口计算提出的一种机制, 本质上是一种时间戳。 一般来讲Watermark经常和Window一起被用来处理乱序事件。
29. Flink Table & SQL 熟悉吗?TableEnvironment这个类有什么作用
答:
TableEnvironment是Table API和SQL集成的核心概念。这个类主要用来:
- 在内部catalog中注册表
- 注册外部catalog
- 执行SQL查询
- 注册用户定义(标量,表或聚合)函数
- 将DataStream或DataSet转换为表
- 持有对ExecutionEnvironment或StreamExecutionEnvironment的引用
我是DJ丶小哪吒。是一名互联网行业的工具人,不生产代码,我只做代码的搬运工。哈哈哈,我们下期见哦,Bye~
| 其实我们往往失败不是在昨天,而是失败在没有很好利用今天。 |

















 1922
1922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









