



 本文深入剖析了Elasticsearch的分布式架构特点及其对系统扩展性和可用性的影响。探讨了ES的节点角色分工、数据分片机制、索引管理和搜索流程等关键技术细节。
本文深入剖析了Elasticsearch的分布式架构特点及其对系统扩展性和可用性的影响。探讨了ES的节点角色分工、数据分片机制、索引管理和搜索流程等关键技术细节。
ES的分布式架构有什么好处?
- 存储的水平扩容,能够支持PB级数据
- 提高系统的可用性(某些节点如果挂掉,对于整个集群没有太大影响)
分布式架构
不同的集群通过不同的名字来区分,默认是elasticsearch,具体的名字我们可以通过配置文件进行修改,或者在命令行里用-E cluster.name = Duters 进行设定。
此外,每一个Node节点就是一个ElasticSearch实例,也就是一个Java进程,一般生产环境下一台机器就运行一个ES实例,每个节点启动之后都会分配一个UID,保存在data目录下面。
Coordinating Node
处理请求的节点就叫做Coordinating Node
-
从上篇文章我们能看到创建Index的时候,我们只提到了请求会被打到一个节点上,但是这个节点(Coordinating Node)是需要通过路由打到Master节点上的。
-
所有节点默认都是Coordinating Node
-
通过设置其他类型为False,我们可以使节点变成Dedicated Coordinating Node
我们可以通过Cerebro查看相应的集群状态和节点分片信息:
Data Node与Master Node
保存数据的节点,并且保存的是分片的数据,在数据扩展上起到了关键的作用,也就是说是由Master节点来决定怎样把数据发送到数据节点上,增加数据节点可以解决数据水平扩展和解决数据单点的问题
-
节点启动后默认就是数据节点,可以设置
node.data:false来禁止 -
Master Node负责创建、删除index/决定分片被分配到哪个节点
-
维护和更新cluster State
-
实践:master节点很重要,要考虑单点问题,一个集群最好有多个master节点/每个节点只承担master的单一角色
-
如果说其中一个master节点出现了故障,那么就要有选举流程选出一个master节点,每个节点启动后默认是一个master eligible节点(配置
node.master:false来禁止) -
集群内的第一个master eligible节点启动的时候默认是把自己选举成master节点
-
集群状态:节点信息,所有的索引和相关的mapping和setting信息,分片的路由信息,每个节点上都保存了集群的状态信息,但是只有master节点能修改信息,并且负责同步给其他节点,
选举过程
1.互相ping对方,Node id小的会被选举成master节点
-
寻找 clusterStateVersion 比自己高的 master eligible 的节点,向其发送选票
-
如果 clusterStatrVersion 一样,则计算自己能找到的 master eligible 节点(包括自己)中节点 id 最小的一个节点,向该节点发送选举投票
-
如果一个节点收到足够多的投票(即
minimum_master_nodes的设置),并且它也向自己投票了,那么该节点成为 master 开始发布集群状态
2.其他节点加入集群后,不承担master节点的角色,如果发现被选中的master节点挂掉了,再重新选举
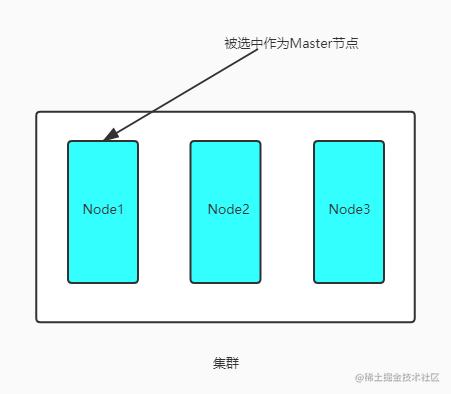
怎么触发一次选举?
- 当前的master eligible节点不是master
- 节点之间做网络通信
- 集群中无法连接到 master 的 master eligible 节点数量已达到
discovery.zen.minimum_master_nodes所设定的值
脑裂问题:分布式系统的经典网络问题,当出现网络问题的时候,一个节点和其他节点无法进行通信,
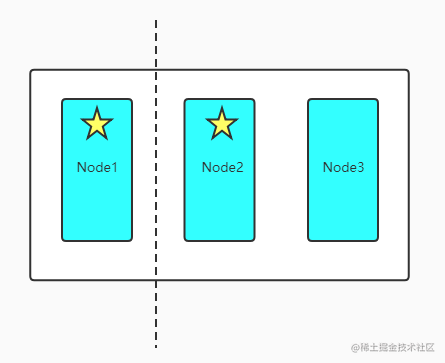
如上图所示,Node2和Node3会重新选举Master节点,而Node1自己作为master组成一个集群,同时更新了cluster state,这就导致了产生两个master节点,并且有两个集群状态,网络一旦恢复了,就没有办法正确恢复。
怎么避免脑裂?
限定一个选举条件,设置Quorum仲裁,只有Master eligible节点数大于quorum时,才能进行选举
-
Quorum = (master节点总数/2)+1
-
当三个master eligible 时,设置discovery.zen.minimum_master_nodes为2,就可以避免脑裂
-
7.0以后的版本不需要配置了
分片的若干问题
从上一篇文章我们知道,文档会存储在具体的某个主分片和副本分片上,但是怎么决定这个文档存储到哪个分片上呢?
映射算法
-
确保文档能均匀的分布在所用的分片上,充分利用硬件资源,从而避免部分机器空闲,部分机器繁忙。
-
潜在的算法:
<ul> <li>随机/Round Robin:当查询文档1的时候,如果说分片数很多,可能就需要多次查询才有可能查到文档1。</li> <li>维护一个文档到分片的映射关系。那么当文档数据量大的时候,维护的成本也很高。</li> <li>实时计算,通过文档1,自动算出一个值,从而去该值对应的分片上获取文档。</li> </ul> <p>ES是怎么路由的呢?</p> <ul> <li> <p>公式:<code>shard = hash(_routing) % number_of_primary_shards</code></p> <p>1.Hash算法确保了文档均匀分散。</p> <p>2.默认的_routing值是文档id。</p> <p>3.可以自行指定_routing数值。</p> <p>4.这也是设置了Index Settings后,Primary数就不能随意更改的原因。</p> </li> </ul> </li>
倒排索引的不可变性
此外,我们再创建一个Index的时候会生成倒排索引,倒排索引是不可变的,一旦生成就不能再更改。
这带来的好处有:
- 无需考虑并发写文件的问题,避免了锁机制带来的性能问题
- 一旦读入内核的文件系统缓存,便留在那里,只要文件系统有足够的空间,大部分请求就会直接去请求内存,不会命中磁盘,提升了很大的性能
- 缓存容易生成和维护,数据也可以被压缩
但是这也带来了挑战:如果需要让一个新的文档可以被搜索就需要重建索引。
那么在Lucene Index中是包含很多的分段的,而分段也被就是单个倒排索引,多个segment汇总在一起就组成了相应的分片
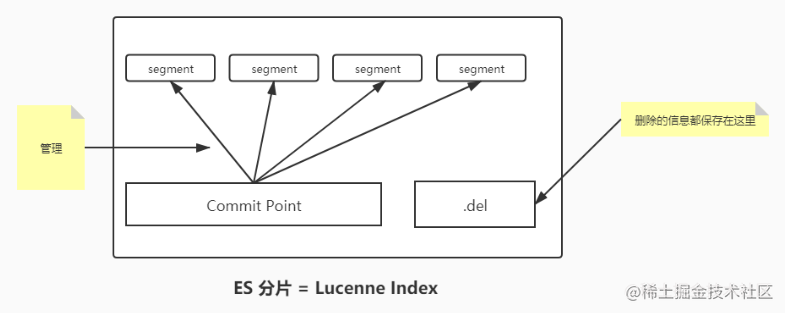
文档的写入和删除具体流程
那么我们知道了相应的分片路由公式之后,具体我们想写入一个文档的流程是怎么样的呢?在前一篇我们仅仅从宏观上阐述了过程,下面在我们来看一下相对详细一点的过程:
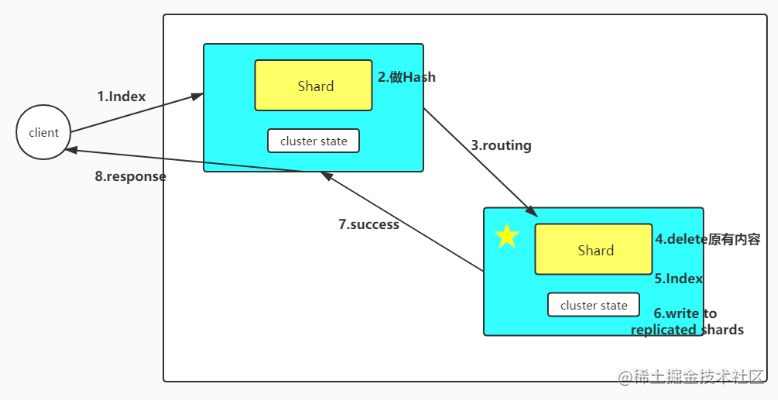
在进行写操作时,因为任意一个节点都是coordinating Node,因此请求达到了一个节点上都可以进行处理,那么ES会根据传入的_routing参数(或mapping中设置的_routing, 如果参数和设置中都没有则默认使用_id), 按照公式 shard_num=hash(\routing)%num_primary_shards,计算出文档要分配到的分片,在从集群元数据中找出对应主分片的位置,将请求路由到该分片进行文档写操作,此外还需要并发的写入到副本分片中从而完成一次写入。
-
那么问题来了,一个文档被写入了以后能够被立刻查询到吗?
<p><em>回忆一下我们上一篇文章中说的,分段关闭了才能被查询,关闭的过程叫做refresh刷新</em></p> <p>答案是可以的,这也是为什么ES是近实时性的体现,首先我们知道ES的每一个分片都是一个Lucene索引,ES提供了一个refresh操作,首先再Index一个文档的时候,ES会先把docunment写入到index buffer中(内存里的),然后他会定时的调用lucene的reopen(新版本是openIfChanged)给内存中新写入的数据生成一个分段segment,此时被处理的文档均可以被检索到,refresh的时间间隔由 <code>refresh_interval</code>参数控制,默认为1s, 当然还可以在写入请求中带上refresh表示写入后立即refresh,另外还可以调用refresh API显式refresh。</p> </li> <li> <p>第二个问题,那么数据怎么保证存储可靠性呢?</p> <p>我们知道我们虽然在前面写入了数据,但是此时的数据是存储在内存中的,那么如果说这个时候ES服务器宕机了,那么这部分数据就会丢失,为了解决这个问题,ES引入了<code>translog</code>:当我们进行文档的写入操作时,会先将文档写入到Lucene的分段中,然后再写一份到<code>translog</code>中,写入<code>translog</code>是落盘的(如果对可靠性要求不是很高,也可以设置异步落盘,可以提高性能,由配置 <code>index.translog.durability</code>和 <code>index.translog.sync_interval</code>控制),这样就可以防止服务器宕机后数据的丢失。由于<code>translog</code>是追加写入,因此性能要比随机写入要好。与传统的分布式系统不同,这里是先写入Lucene再写入<code>translog</code>,原因是写入Lucene可能会失败,为了减少写入失败回滚的复杂度(ES是不支持事务的),因此先写入Lucene。</p> </li> <li> <p>第三个问题,<code>translog</code>是落盘的,那么什么时候落盘呢?频率是什么样子?</p> <p>这就涉及到flush操作,每30分钟或当<code>translog</code>达到一定大小(由 <code>index.translog.flush_threshold_size</code>控制,默认512mb), ES会触发一次flush操作,此时ES会先执行refresh操作将index buffer中的数据生成segment,然后调用lucene的commit方法将所有内存中的segment fsync到磁盘。此时lucene中的数据就完成了持久化,会清空<code>translog</code>中的数据(6.x版本为了实现sequenceIDs,不删除<code>translog</code>)</p> <p><img alt="" src="https://p1-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/082564debdd64d29b028a86317050bca~tplv-k3u1fbpfcp-watermark.image" /></p> </li>
除了上面的flush过程,我们在第一篇文章中也说到过,分段大小超过一定阈值会进行合并吗,具体过程就是:
- merge操作 由于refresh默认间隔为1s,因此在这个过程中不断地写入打开的分段就会产生大量的小segment,为此ES会运行一个任务检测当前磁盘中的segment,对符合条件的segment进行合并操作,减少lucene中的segment个数,提高查询速度,降低负载。不仅如此,merge过程也是文档删除和更新操作后,旧的doc真正被删除的时候。用户还可以手动调用_forcemerge API(
POST my_index/__forcemerge)来主动触发merge,以减少集群的segment个数和清理已删除或更新的文档。 - 多副本机制 另外ES有多副本机制,一个分片的主副分片不能分片在同一个节点上,进一步保证数据的可靠性。
分片的写入说完了,同理,删除一个文档也同样,具体就不再赘述了:
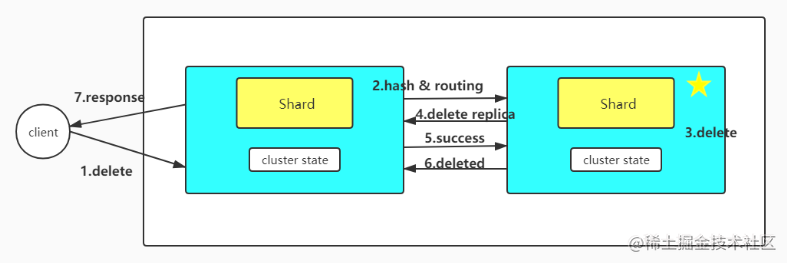 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1PHrXuta-1607572714812)(F:\YoungLH's blog\source\images\删除的详细过程.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1PHrXuta-1607572714812)(F:\YoungLH's blog\source\images\删除的详细过程.jpg)]
分布式搜索的运行机制
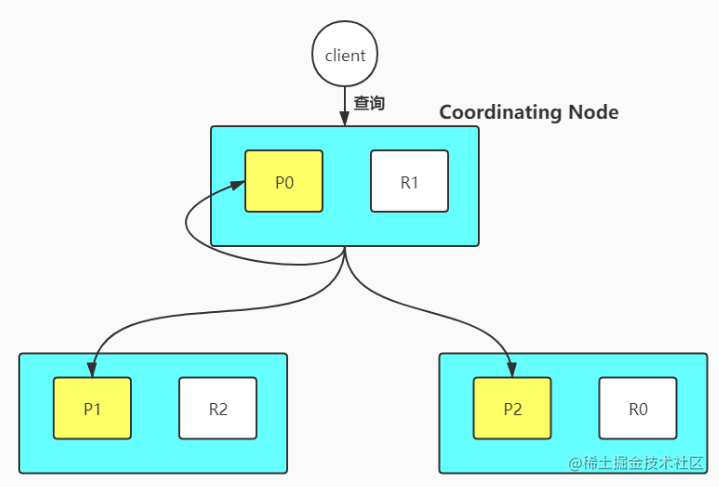
ES的搜索分成两部分
-
第一阶段是Query
-
第二阶段是Fetch
<p>具体流程是:</p> <ul> <li> <p>用户发出搜索请求到ES节点,节点收到请求后会以Coordinating Node的身份,在6个主副节点中随机选择三个分片发送查询请求。</p> </li> <li> <p>被选中的分片执行查询,<strong>进行排序</strong>,然后每个分片都会返回From+Size个排序后的文档id和排序值给Coordinating Node。</p> </li> <li> <p>Fetch阶段Coordinating Node会把query阶段首先拿到从每个获取的排序后的文档id列表进行重新排序,选取From到From+Size的文档id。</p> </li> <li> <p>用multi_get请求的方式到相应的分片获取详细的文档数据</p> </li> </ul> <p>问题:</p> <ul> <li> <p>性能问题:</p> <ul> <li>每个分片都需要查的文档个数=from+size</li> <li>最终Coordinating Node需要处理:number of shards * (from + size)这么多数据</li> <li>深度分页,这也是搜索引擎一直存在的问题(ES可以试用search after的api)</li> </ul> </li> <li> <p>相关性算分问题</p> <ul> <li>每个分片都是基于自己分片上的数据进行相关度计算,这会导致score的偏离</li> </ul> <p>怎么解决相关性算分问题?</p> <ul> <li> <p>当数据量不大的时候可以设置主分片数量为1</p> </li> <li> <p>数据量足够大的时候,只要保证文档均匀分散在哥哥分片上,结果就不会出现太大偏差</p> </li> <li> <p>可以试用DFS Query Then Fetch:搜索URL中添加</p> <p><code>_search?search_type=dfs_query_then_fetch</code>参数,原理是到每个分片上把各个分片的词频和文档频率进行搜集,然后完整的进行一次相关度算分,但是这种情况会消耗更多的CPU和内存,执行性能不好。</p> </li> </ul> </li> </ul> </li>
ES并发控制
看一个例子:
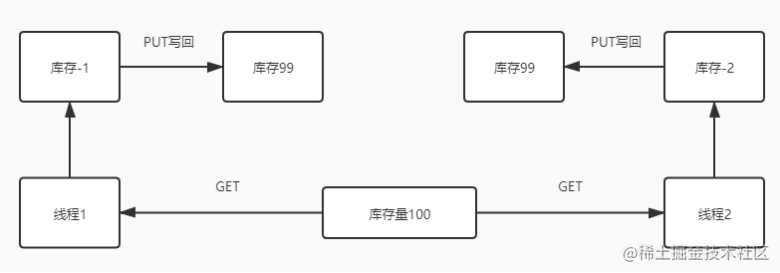
为什么第二个线程扣完了库存以后库存量还是99呢?
首先数据库的锁包含悲观锁和乐观锁
ES采用的是乐观并发控制的思想,假定不会发生冲突,不会阻塞正在尝试的操作,如果数据在读写的过程中被修改了,更新就会失败。ES会将怎么解决冲突交给我们编写的应用程序来实现,比如我们可以做失败重试,或者提交错误报告等等。
-
ES提供了_seq_no和__primary_term这两个字段,我们可以去用这两个字段在程序里做判断从而实现版本控制
<p>比如上一次查询结果我们拿到的_seq_no和primary_term分别是0和1,那么下次更新的时候我们的QSL语句可以这么写:</p> </li>
PUT my_idx/_doc/1?if_seq_no=0&if_primary_term=1
{
"title":"DaLian University of Technology"
"department" : "Control Science and engineering"
}
复制代码- 如果我们现在的情况是ES的数据是从类似MySQL同步过来的,纳闷我们还可以利用版本号MySQL中的version和ES中的version_type进行比较从而进行并发控制。
PUT my_idx/_doc/1?version=100000&version_type=external
{
"title":"DaLian University of Technology"
"department" : "Control Science and engineering"
}
作者:kgpp34


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









