




- LISTEN, THINK, AND UNDERSTAND
- 一种模型优化技术:这篇论文的核心贡献在于提出了一个新的多模态大型语言模型LTU,它不仅能够处理音频分类和描述任务,还能够理解和回答开放性问题,是音频模型领域一个创新的尝试。
章节1:背景介绍
日常生活中,我们被各种音频信号包围,如汽车鸣笛声、火车轰鸣声、鸟叫声、聊天声等,人不仅能够感知和识别这些声音,而且还能理解一些隐含含义。如当听到时钟敲6次时,可能会认为现在是6点钟;根据火车鸣笛声,能推断出火车是到来或离去。此外,人还能获取到音频线索所传达的情感氛围。无所不能的人工智能也应该具备这样的能力!
理想很丰满,现实很骨感。当前音频标签模型,几乎没有推理和理解能力,所以音频标签模型能识别出“时钟敲了6次”,但不知道这意味着“6点钟”;而像GPT这样的大语言模型(LLMs)具有强大的音频知识和推理能力,如问“狗的叫声是怎样的?”,GPT可能给出基本正确的回答:“狗的叫声是短促、重复、尖嘴的汪汪声或叫声”,但对音频事件又缺乏感知(无法从音频文件中辨识出狗叫)。
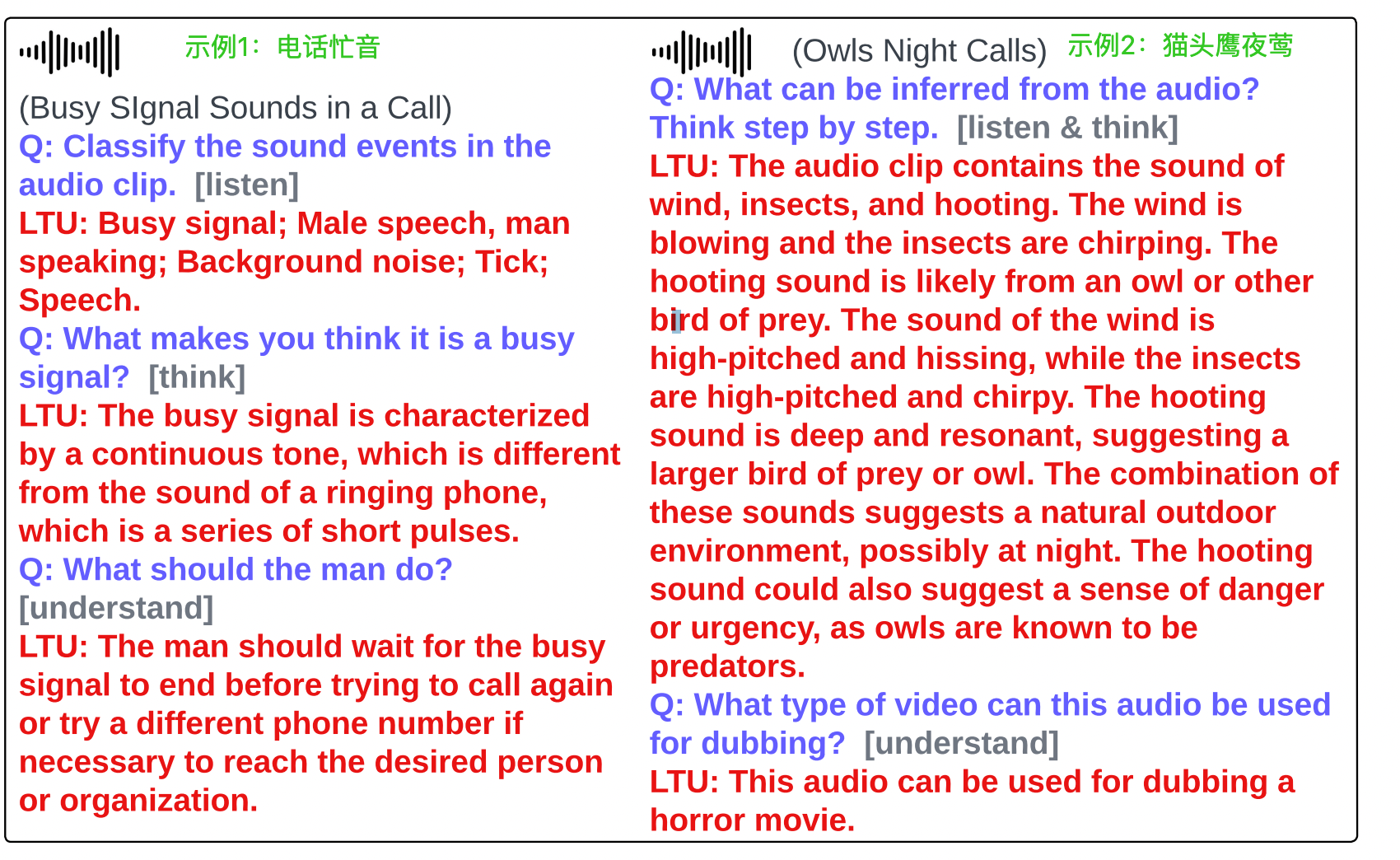
如何让大模型具备音频感知能力喃?论文提出一种的大模型架构 LTU (Listen, Think, and Understand)来解决这一问题,下图是2个示例,效果看着还挺有意思。我们以下图左边“电话忙音”为示例来看看LTU的能力:
- 能听(listen):音频片段都是些什么声音?LTU首先能给出音频是电话忙音信号,有一个男人在说话,有背景噪声
- 能想(think):为什么是电话忙音喃?因为电话忙音是连续低音,而电话响铃的声音是连续的脉冲信号
- 能理解(understand):这个男人应该怎么做喃?既然已经判定是忙音,意味着对方可能正在通话中,背后的含义就是要不男人等一会再次重播或者换个号码再拨。
章节2:方案阐述
框架设计
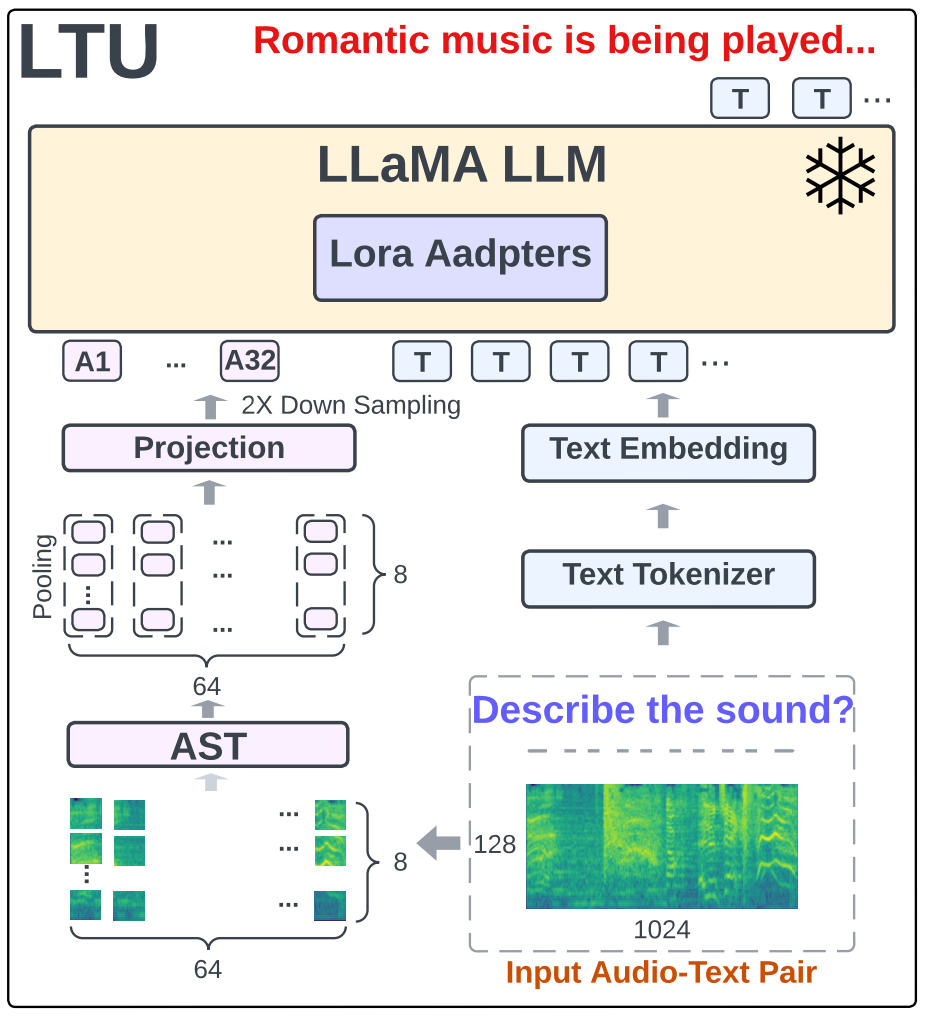
LTU模型架构如上图,可以看出主要包括三个模块:音频编码器-AST(Audio S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









