




 本文详细指导如何从GitHub克隆CaffeSSD项目,配置环境(包括关闭CUDA和CUDNN使用CPU版本),安装并验证Caffe,以及准备VOC2007和2012数据集,将其转换为LMDB格式,以便进行对象检测任务。
本文详细指导如何从GitHub克隆CaffeSSD项目,配置环境(包括关闭CUDA和CUDNN使用CPU版本),安装并验证Caffe,以及准备VOC2007和2012数据集,将其转换为LMDB格式,以便进行对象检测任务。
git clone -b ssd https://github.com/weiliu89/caffe.git caffe_ssd
cd caffe_ssd
cp caffe/Makefile.config caffe_ssd/
# 把 cuda 和 cudnn 关了,用 cpu 版本的就好了
make -j32
make pycaffe
make test -j8
make runtest -j8
vim ~/.bashrc
# 加入
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/your/caffe_ssd/python
source ~/.bashrc
验证python环境中的 caffe 是不是你的 ssd_caffe
import caffe
print(caffe.__file__) # 返回 pycaffe 的路径,你就可以知道是哪个caffe了
制作 VOC0712 lmdb
## 1. 下载VOC2007和VOC2012数据集, 放在caffe_ssd/data目录下:
cd data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar
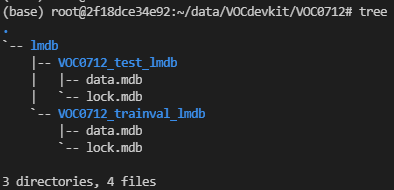
## 2. 创建lmdb格式的数据:
cd caffe_ssd
./data/VOC0712/create_list.sh
./data/VOC0712/create_data.sh


















 554
554


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








