



 本文分享了在知网上爬取博硕士论文的详细过程,包括如何定位目标链接、解析请求URL以及组合链接的方法,为读者提供了一套实用的爬虫技巧。
本文分享了在知网上爬取博硕士论文的详细过程,包括如何定位目标链接、解析请求URL以及组合链接的方法,为读者提供了一套实用的爬虫技巧。
作为一个合格的萌新,这个步骤卡了我很久!
我要爬取的页面长这个样子:
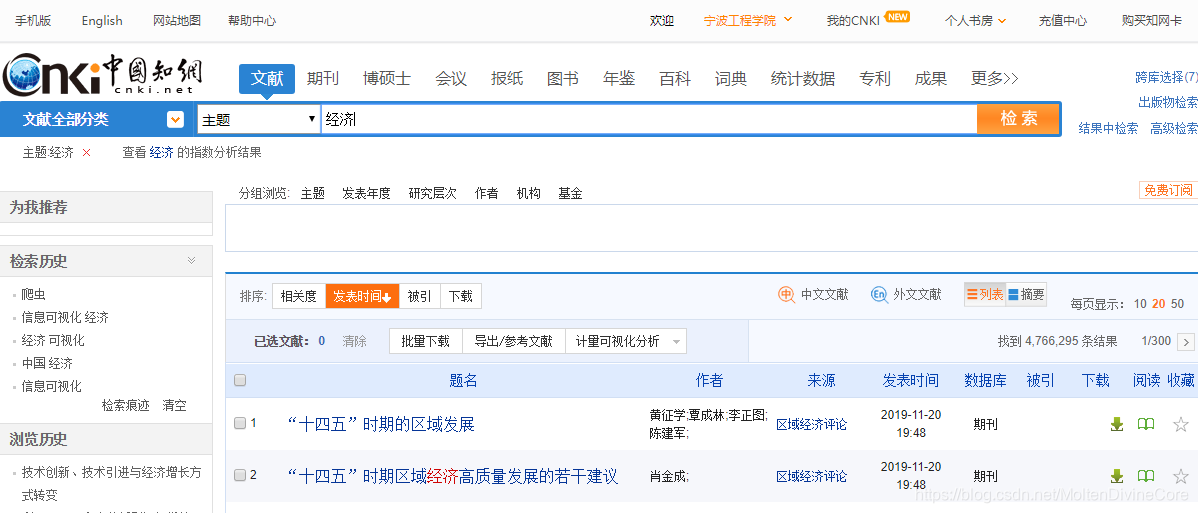
但是这个网页的连接是这样:![]()
【没有任何特点】
知网先把搜索要求发给【不知道哪里】,再从【不知道哪里】把结果发送到这个defaul_result.aspx页面上。所以网页地址里没有任何信息。这肯定代表了什么机制……不过没那么现在不去摸索这个,要绕过他。
第一步:直接F12,在elements里康康内容
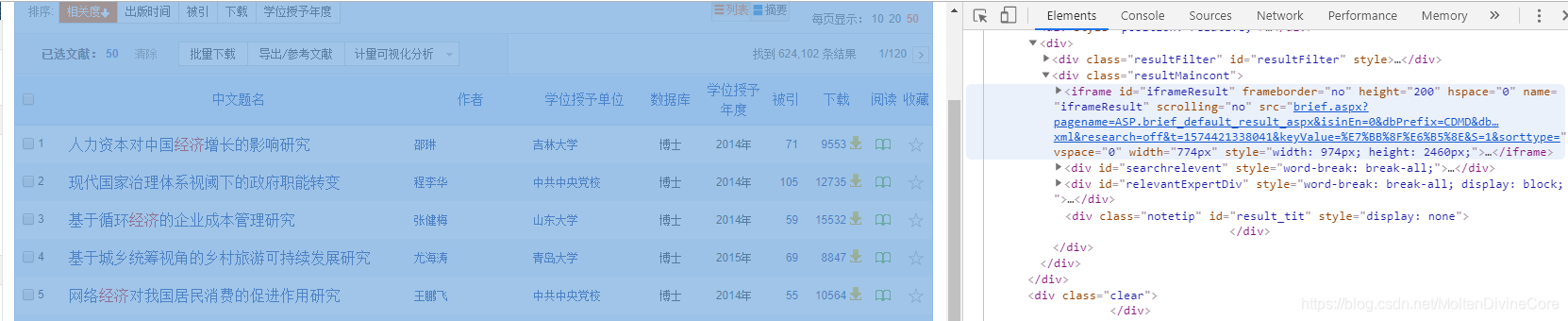
找到了链接,链接对应的是我说要爬取的内容,但是,这个链接并不能直接通过简单爬虫直接获得,也不能直接copy出来作为网络链接。
那咋办呢?百度呗……
第二步:网页加载了什么?康康Network
首先,我需要的是博硕士论文,然后需要相关度降序。所以需要一点操作。
点击"博硕士",;打开"F12";点击"Network";点击"相关度"。会得到下面的界面:
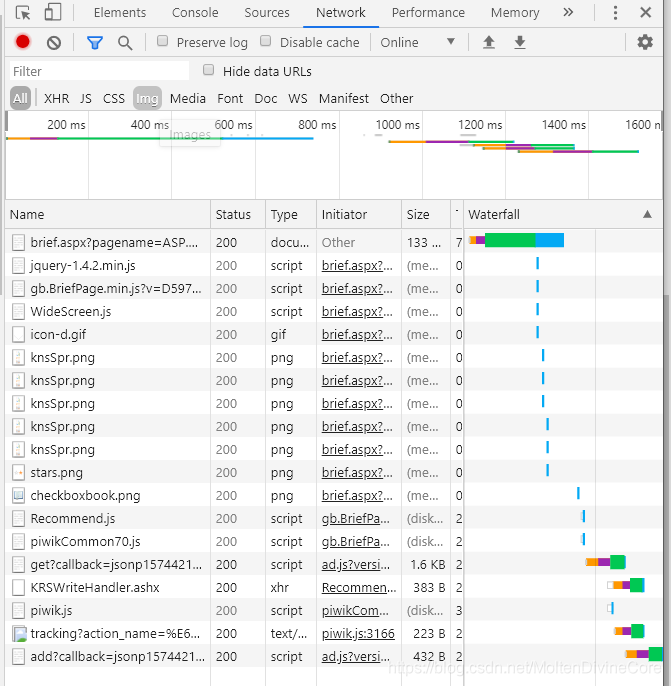
显示了一堆东西, 最关键的是:第一条
联系下第一步里获得的src,是不是一模一样!
打开它,里面是:
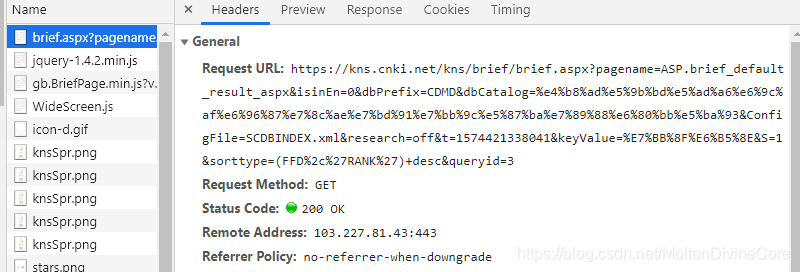
Request URL就是我需要的东西了!
关键不只是这条链接,还有链接的组合方式。
其中 "id" 和 "queryid" 似乎是登录使用网页是专门分配的,我不知道怎么获取,但,可以从上面那个页面里复制出来用,链接别的东西就完全不需要变,每次爬的时候都复制一次这两个东西就好了。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









