




1、切片语法基本结构
Python 中切片的通用格式如下:
sequence[start : stop : step]
| 参数 | 含义 |
|---|---|
| start | 起始索引(包含) |
| stop | 结束索引(不包含) |
| step | 步长,默认是 1 |
这个规则适用于字符串、列表、元组、range 等大多数原生序列对象。
2、字符串、列表、元组、range的切片规则:不包含末尾元素
以字符串为例,它本质上是一个字符序列,序号从 0 开始。如果字符串长度为 L,那么最后一个字符的索引就是 L-1。此外,Python 还支持从右往左数的负索引(如 -1 表示最后一个字符)。
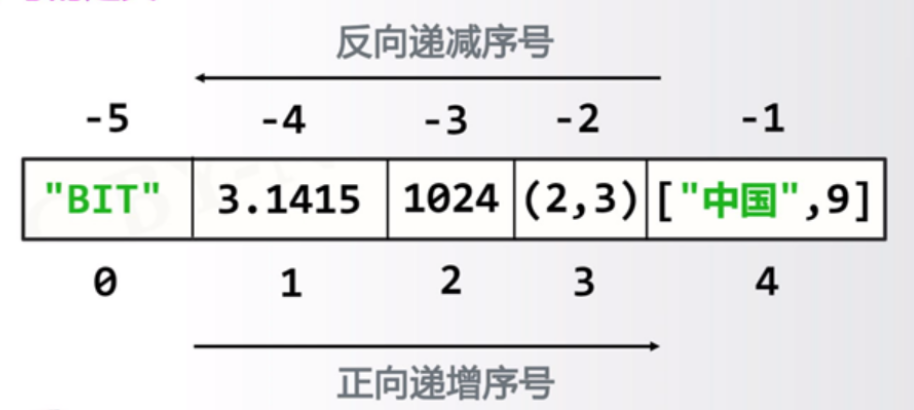
2.1 切片省略参数的基本情况
虽然切片看起来简单,但在实际使用中,经常会省略 start、stop 和 step 参数。如果不理解清楚,就很容易出错。我们先来看一些典型用法:
nums[2:5] # [2, 3, 4] → 从索引 2 到 4(不包括 5)
nums[:4] # [0, 1, 2, 3] → 从头开始到索引 3
nums[5:] # [5, 6, 7, 8, 9] → 从索引 5 到结尾
1:起始索引与终止索引都填写数值。以下面的这个列表,print()中的索引从0开始,到3结束,表示为0、1、2的位置上的元素。stop =3是不包含3位置上的元素。也就是说,切片的结果是从start 开始,到stop -1为止,步长为step(默认为1)。
lst = [12, 23, 21, 45, 31]
print(lst[0:3]) # [12, 23, 21]
2:只填写了终止索引。那么默认从第0个开始,到3 -1 =2这个位置结束,也就取到了12、23、41 这三个元素。
lst = [12, 23, 21, 45, 31]
print(lst[:3]) # [12, 23, 21]
3:只填起始值。说明从索引2 开始取到结尾。
lst = [12, 23, 21, 45, 31]
print(lst[2:]) # [21, 45,31]
4:只填步长。那也就是说按照步长每隔n取一个,直到
取完。这里的nums[::2]表示的是从第0个开始,每隔一个取一个,直到列表取完。
nums = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
nums[::2] # [0, 2, 4, 6, 8] → 每隔一个取一个
5.反向索引(从右向左数)
nums = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
nums[-3:] # [7, 8, 9] → 倒数第三个到结尾
nums[:-5] # [0, 1, 2, 3, 4] → 开头到倒数第五个之前
- nums[-3: ] 表示的是从索引-3 开始,往后取直到列表结束。
- nums[: -5 ]表示的是从索引0开始取,到索引-5 前一个结束。
2.2 与range() 函数的原则一致
切片的行为与range() 非常一致, 都是“左闭右开区间”的区间逻辑:
for i in range(1, 4):
print(i) # 输出 1、2、3,不包括 4
这使得我们可以通过 stop - start 轻松算出切片长度。
len(nums[2:5]) == 3 # 等于 5 - 2
省略参数时的含义:
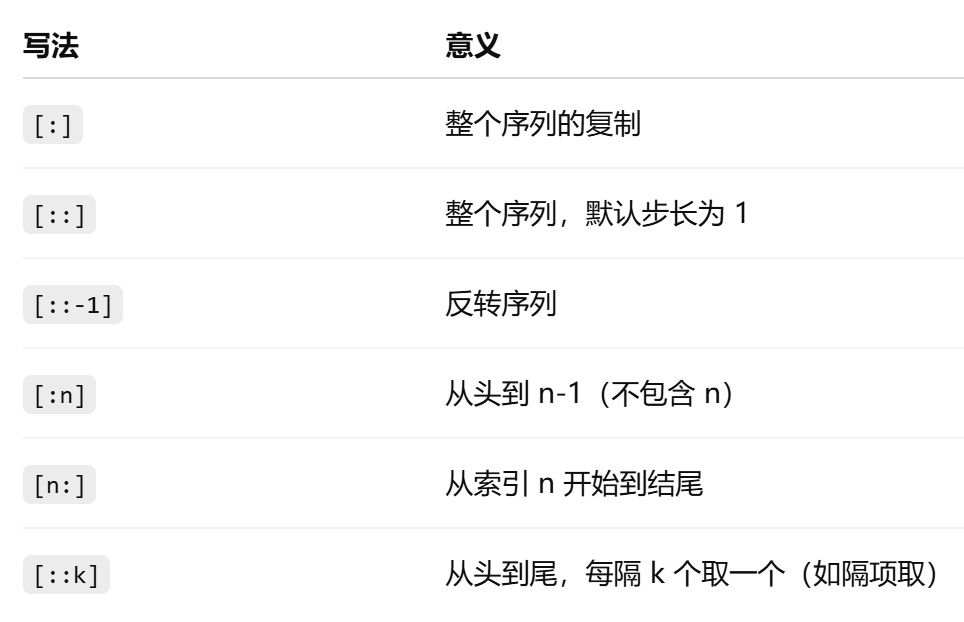
3、DataFrame.loc 的切片规则:包含末尾元素!
再来看 pandas 中 DataFrame 的 loc 切片, 它与原生的python序列切片行为不同:
import pandas as pd
df = pd.DataFrame({"A": [1, 2, 3, 4]})
print(df.loc[0:2])
输出的结果为:
A
0 1
1 2
2 3
解析:
引入pandas库的方法:
1.在终端windows 搜索框中搜索命令提示符(cmd) , 再以管理员的身份打开,输入 pip install pandas 。
2. 加载完成之后打开python , 输入python -m pip install 换行再输入pip install pandas运行之后就已经连接啦。
(如果还有操作不明白的地方, 也可以参考我之前出过一篇文章,里面有详细的连接方式! )
-
loc[0:2]包含了索引为 2 的行 -
这与 Python 原生 list 的切片行为 不一致
-
属于“闭区间”行为(即包含两端)
这通常是因为 loc 是基于 标签值 而非纯粹的整数位置,其设计初衷更像 SQL 查询,强调 包含终点 更符合用户直觉。
总结:
切片操作是 Python 对所有“可序列对象”的统一抽象,在这篇文章中我主要以list为例来说明 。Python 原生序列(如 list、str、range)切片遵循 左闭右开 规则,而 pandas 的
.loc则采用 左右闭合 区间。
希望本文能够帮助你理解如何使用python中的切片,并在实际数据处理中得到应用。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









