



Stable
Diffusion模型目前有版本1和版本2,2个都是开源的。但1版本使用的是OpenAI的CLIP,2版本用的是OpenCLIP,它是CLIP的开源版本。虽然从解码提示词的角度来说,Stable
Diffusion1.5的版本比Stable Diffusion2的版本要表现得更好些,因此,我们比较推荐的是Stable Diffusion1.5版本。
这种不再使用CLIP的转变,可能会为项目贡献者提供一些保护,避免潜在的责任问题,鉴于即将到来的知识产权诉讼浪潮肯定会影响此类模型,这一点很重要。
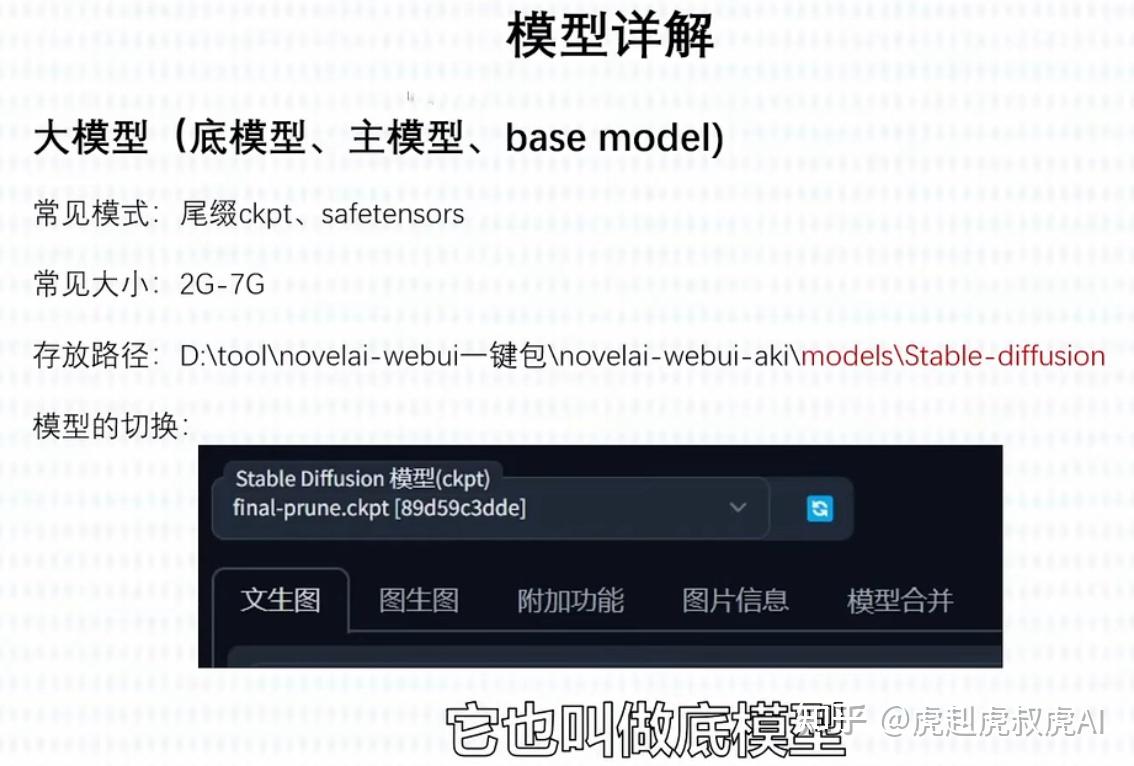
【1】大模型/底模型-属于基础模型也叫预调模型
首先介绍的是大模型,是SD能够绘图的基础模型。安装完SD软件后,必须搭配基础模型才能使用。不同的基础模型,其画风和擅长的领域会有侧重。
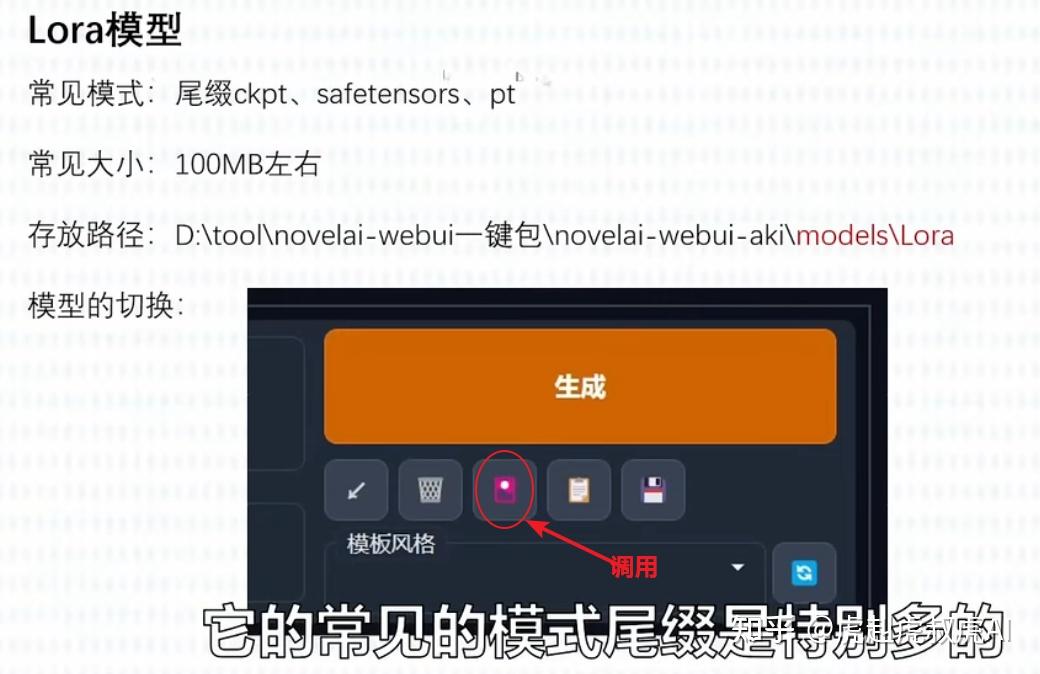
【2】Lora模型-属于微调模型
介绍:
如果把基础模型比喻作一座房子的地基,那么Lora模型就好比在这个地基上盖起来的房子。我们通常也称为微调模型,用于满足一种特定的风格,或指定的人物特征属性。在数据相似度非常高的情形下,使用微调模型,可以节省大量的训练时间和训练资源,就可以产出我们需要的结果。
获得:
要想获得不同的lora,可以是到网络上C站或国内的AI图站下载。下载后的lora文件直接放到Stable
Diffusion安装目录的models的lora目录里。刷新后就可使用。
使用:
点击lora调用按钮后,在tag栏就可以看到一个词条,然后再继续编辑描述语即可。
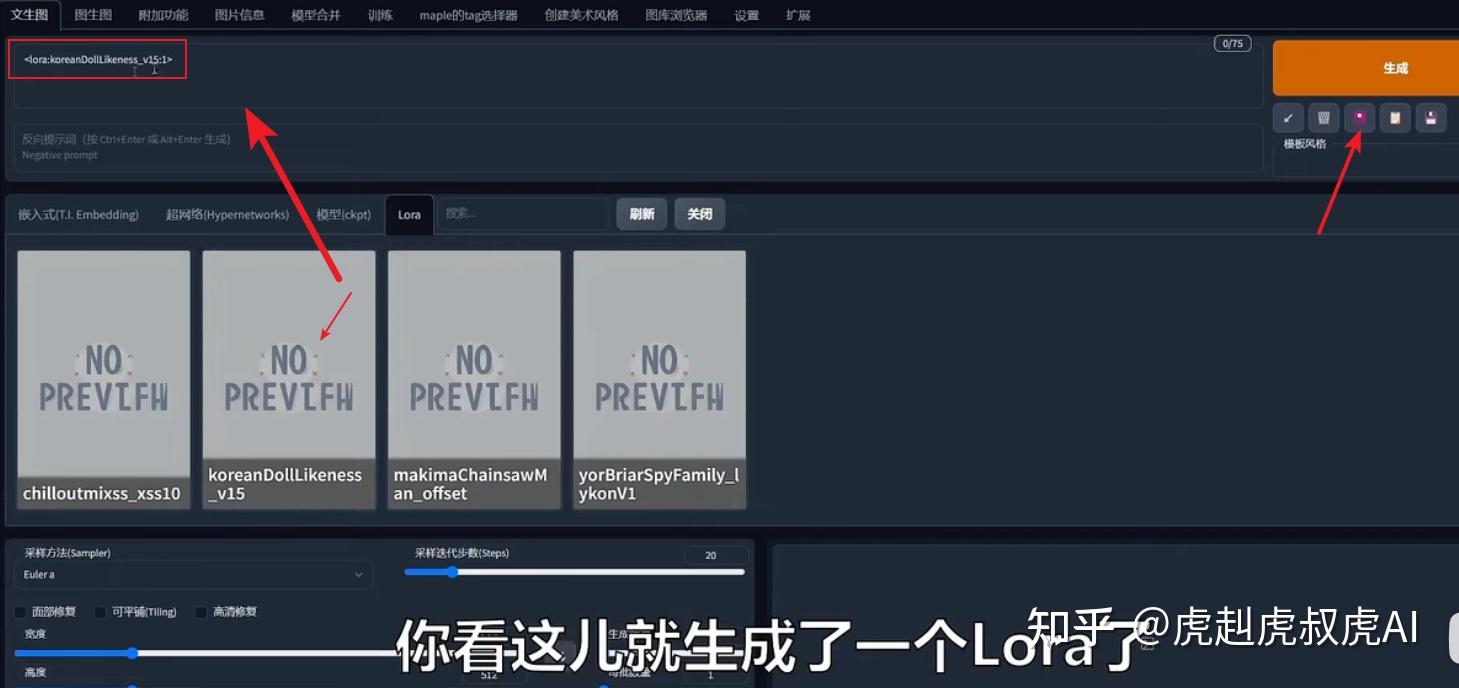
训练:
训练lora的教程B站上很多,也容易让大家看的迷糊,毕竟各有各的炼法,也因为每个人的理解和硬件不同,会有不同操作方式。
这方面的个人心得,也会放在稍后的05期分享中跟大家探讨。
【3】VAE美化模型
VAE,全名Variational autoenconder,中文叫变分自编码器。作用是:滤镜+微调。
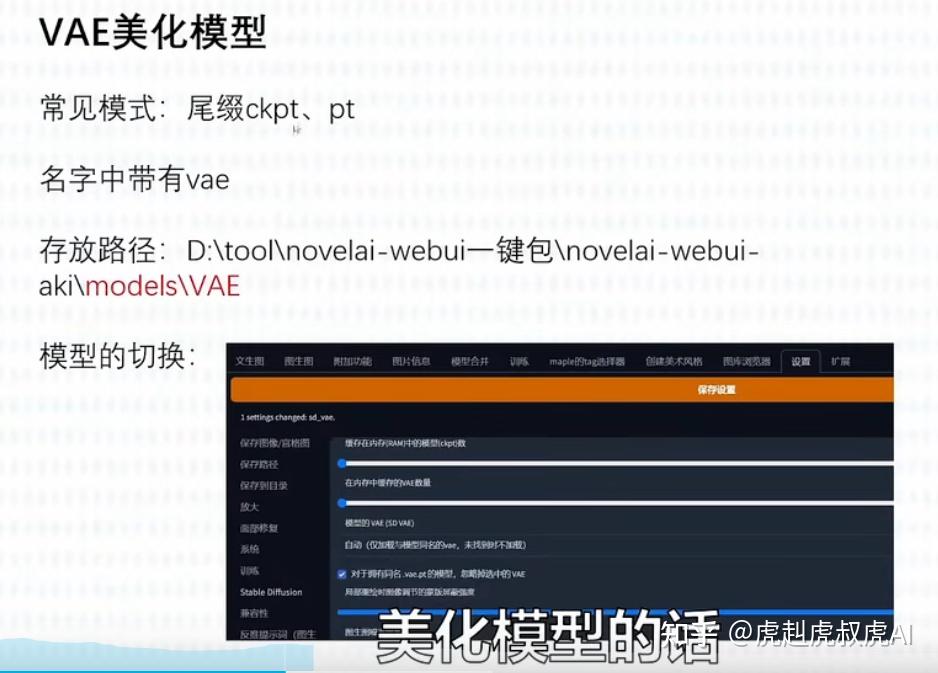
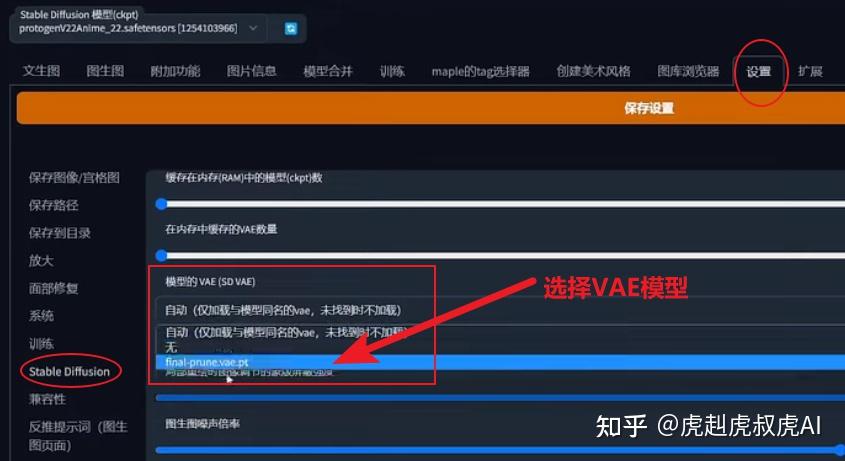

有的大模型是会自带VAE的,比如我们常用的Chilloutmix。如果再加VAE则可能画面效果会适得其反。
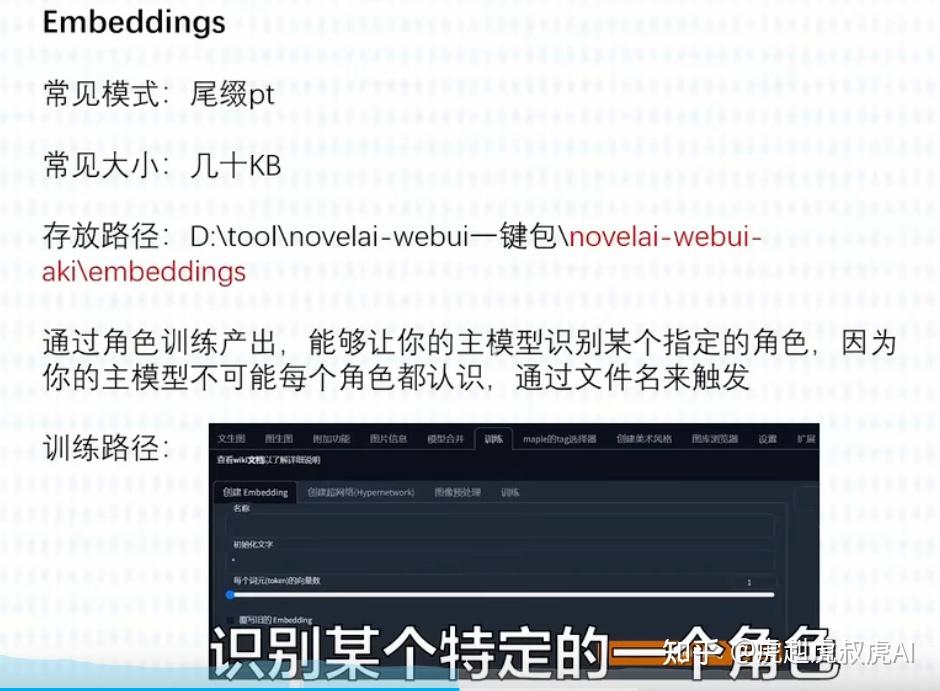
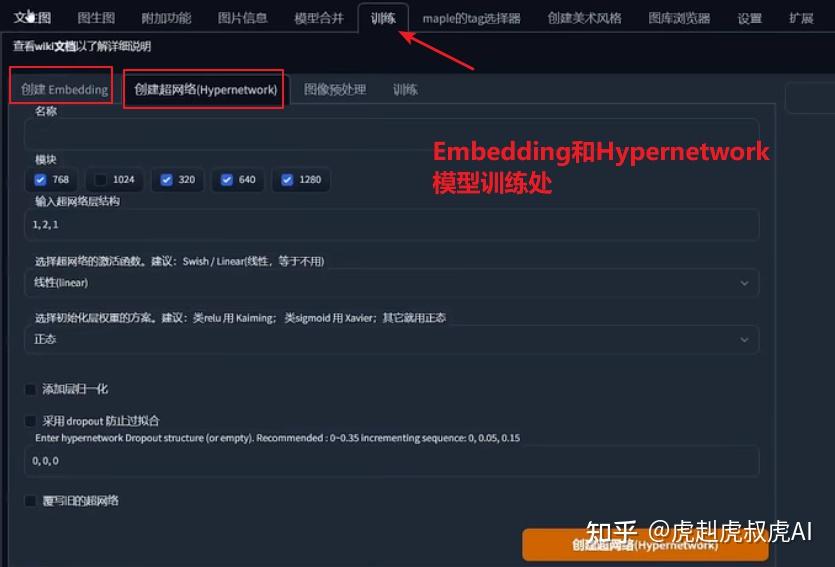
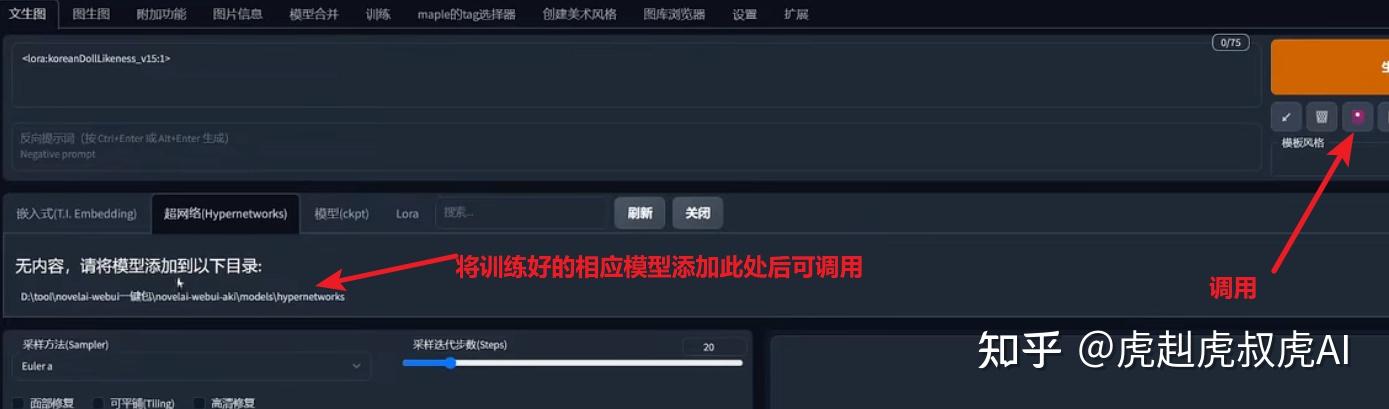
【4】Embeddings和Hypernetworks个性化模型
Embeddings-也是属于微调模型,Hypernetworks则不太用了。
Embeddings叫文本反转,通过仅使用的几张图像,就可以向模型教授新的概念。用于个性化图像生成。与lora模型一样,Embeddings也必须配合基础模型使用。

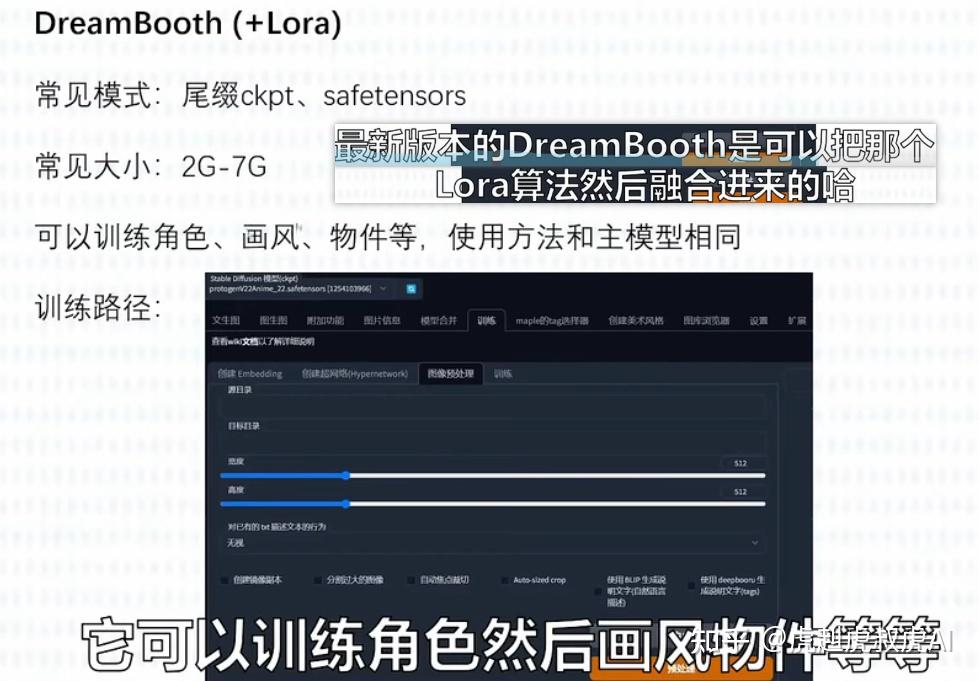
【5】DreamBooth模型
DreamBooth,可用于训练预调模型用的。是使用指定主题的图像进行演算,训练后可以让模型产生更精细和个性化的输出图像。
【6】LyCORIS模型
介绍:
此类模型也可以归为Lora模型,也是属于微调模型的一种。一般文件大小在340M左右。不同的是训练方式与常见的lora不同,但效果似乎会更好不少。
其中本人较喜欢的“Miniature world style 微缩世界风格”就属于这类模型。
获得:
但要使用此类微调模型,需要先安装一个locon插件,直接将压缩包解压后放到StableDiffusion目录的extensions目录里。
使用:
使用时注意,除了要将lora调入,还要在正向tag开头添加触发词
例如:这个微缩世界风格的lyCORIS的调用,正向描述语如下
minittp, (8k, RAW photo, best quality, masterpiece:1.2), island, cinematic
lighting,UHD,miniature, landscape, Crystal ball,on rock,
lora:miniatureWorldStyle\_v10:0.8
训练:
模型下载处-C站
网址(需科学上网):https://civitai.com/
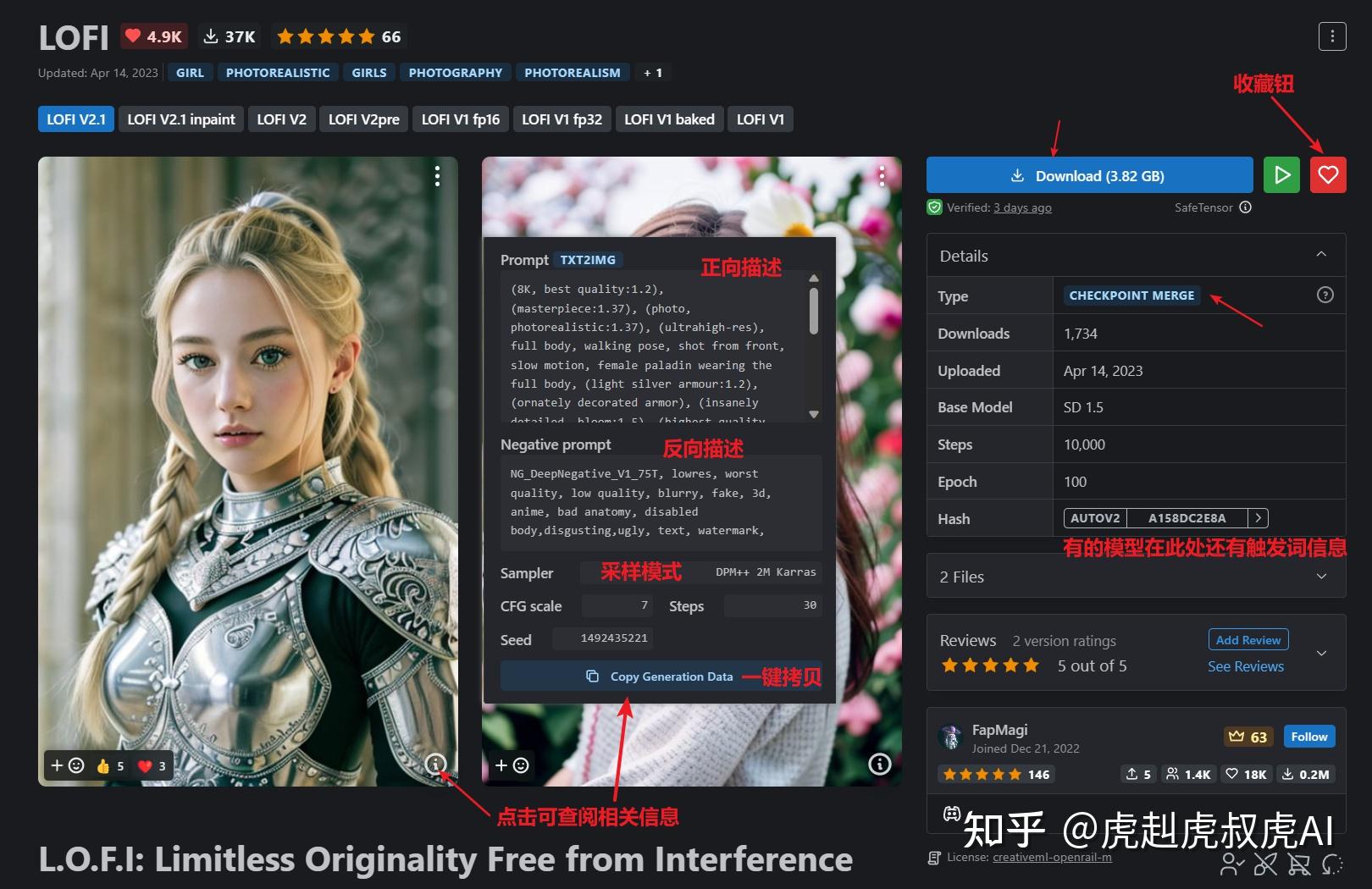
首页面下拉,可以看到此模型的其他作品作参考。
国内模型下载处-AI图站
https://aituzhan.com/
这个站点或许可以淘到不少C站下架了的模型,还是相当不错的。
介绍几个大模型
这里介绍几款基础模型给大家,在文字结尾有百度链接也可以下载到,或者自行到上面推荐的2个站点下载。
lofi_V2pre.safetensors
这是一款不输于chilloutmix_Ni.safetensors(最常用的用于绘制亚洲女性的基础模型)
写实风格,善于人物。

revAnimated_v121.safetensors
这款模型作图效果很好,还能搭配很多不同lora达到很强的表现效果。

v1-5-pruned-emaonly.safetensors
1.5版本官方模型
cuteRichstyle15_cuteRichstyle.ckpt
可爱人物像模型,这个模型不仅需要调用模型,在tag中还需要调用到触发词:cbzbb

Waifu-diffusion:
很出名的模型,用来生成Novel AI类似风格的图片。日漫风格的模型。
下载链接:https://huggingface.co/hakurei/waifu-
diffusion

提示词
Stable Diffusion 最强提示词手册
- Stable Diffusion介绍
- OpenArt介绍
- 提示词(Prompt) 工程介绍
- …
第一章、提示词格式
- 提问引导
- 示例
- 单词的顺序
- …

有需要的朋友,可以点击下方卡片免费领取!
第二章、修饰词(Modifiers)
- Photography/摄影
- Art Mediums/艺术媒介
- Artists/艺术家
- Illustration/插图
- Emotions/情感
- Aesthetics/美学
- …

第三章、 Magic words(咒语)
- Highly detailed/高细节
- Professional/专业
- Vivid Colors/鲜艳的颜色
- Bokeh/背景虚化
- Sketch vs Painting/素描 vs 绘画
- …

第四章、Stable Diffusion参数
- Resolution/分辨率
- CFC/提词相关性
- Step count/步数
- Seed/种子
- Sampler/采样
- 反向提示词(Prompt)

第5章 img2img(图生图),in/outpainting(扩展/重绘)
- 将草图转化为专业艺术作品
- 风格转换
- lmg2lmg 变体
- Img2lmg+多个AI问题
- lmg2lmg 低强度变体
- 重绘
- 扩展/裁剪
- …
第6章 重要提示
- 词语的顺序和词语本身一样重要
- 不要忘记常规工具
- 反向提示词(Prompt)
- …
第7章 OpenArt展示
- 提示词 (Prompt)
- 案例展示
- …
篇幅有限,这里就不一一展示了,有需要的朋友可以点击下方的卡片进行领取!

















 3046
3046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









