




 本文深入讲解了Hadoop作为开源分布式存储和计算平台的核心组件HDFS和MapReduce的运作原理,包括数据块存储、NameNode与DataNode的角色,以及MapReduce的处理流程。同时介绍了YARN的资源管理和调度机制。
本文深入讲解了Hadoop作为开源分布式存储和计算平台的核心组件HDFS和MapReduce的运作原理,包括数据块存储、NameNode与DataNode的角色,以及MapReduce的处理流程。同时介绍了YARN的资源管理和调度机制。
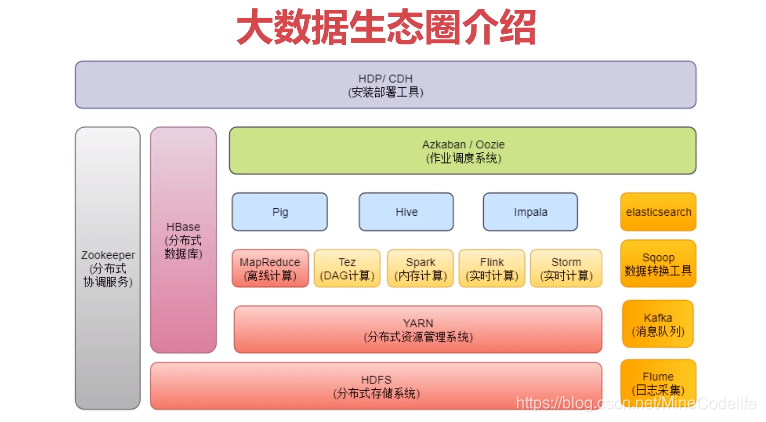
hadoop是一个开源的分布式存储和分布式计算平台。
- HDFS:分布式文件系统,存储海量的数据
- MapReduce:并处理框架,实现任务的分解和调度
HDFS
- BLOCK:HDFS的文件被分成快进行存储,默认大小64Mb。块是文件存储处理的逻辑单元。每个数据块3个副本,分布在两个机架内的三个节点。
- NameNode:是管理节点。存放文件元数据。二级NameNode定期同步元数据影像文件和修改日志,防止NameNode故障。
- 文件与数据块的映射表
- 数据块与数据节点的映射表
- 接受用户的操作请求
- DataNode:是HDFS的工作节点存放文件数据块。定期向NameNode发送心跳信息。
HDFS特点:
- 数据冗余,硬件容错
- 流式数据访问,大文件存储
- 适合一次写入多次读取,不支持多用户并发访问

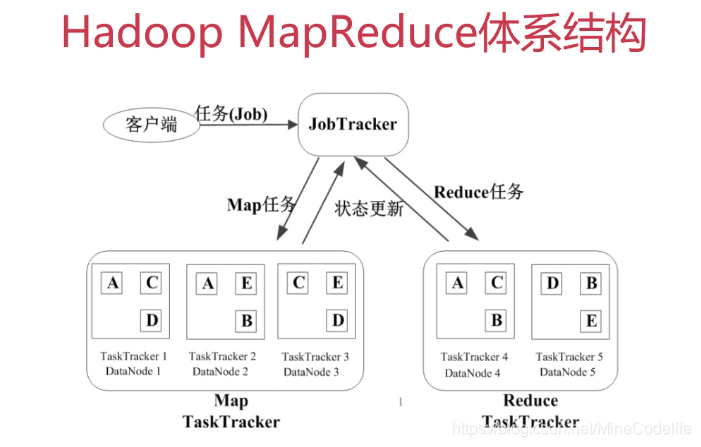
MapReduce
Map(映射)"和"Reduce(归约)",是它们的主要思想.
YARN
YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。
- ResourceManager:分配和调度资源,启动和监控ApplicationMaster,监控nodeManager
- ApplicationManager:为MR类型的程序申请资源并分配给内部任务,负责数据的切分
- NodeManager:管理每个节点的资源,处理来自RM和AM的命令
深入mapReduce的过程
节点map任务的个数可增大mapred.map.tasks,减少map任务的个数mapred.min.split.size。
数据经过map后经shuffle混冼进入reduce,在大数据的情况下可能造成网络的巨大开销,所以可以在本地按照key先进行一轮合并和排序,在进行网络混冼。这个过程就是combine。在多数情况下与reduce的逻辑是一致的。partition是在reduce输入之前发生,相同的key一定会进入同一个partitioner
一个mapReduce作业中,以下三者的数量总是相等的。
- partitioner
- Reduce任务
- 最终输出文件 (part-r-000x)
在一个reduce中,所有数据都会按照key升值排序,所以part输出文件中包含key值则这个文件一定是有序的。
分布式缓存
加载到内存发生在job执行之前,每个从节点各自都缓存一份相同的共享数据,如果共享数据太大,可以将共享数据分批缓存,重复执行作业。


















 5678
5678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









