






 本文探讨了使用深度学习方法,特别是CatBoost和RoBERTa模型在金融用户评论中进行精准分类。通过CatBoost的GPU加速和RoBERTa的强大自然语言处理能力,实现了高精度的业务识别,如消费贷款、信用卡等。
本文探讨了使用深度学习方法,特别是CatBoost和RoBERTa模型在金融用户评论中进行精准分类。通过CatBoost的GPU加速和RoBERTa的强大自然语言处理能力,实现了高精度的业务识别,如消费贷款、信用卡等。
【人工智能项目】深度学习实现金融用户评论分类

任务说明
本数据集包含金融行业用户评论信息,其中有大量长文本,根据评论识别所属金融业务,具体类别如下:
0:消费贷款
1:抵押
2:信用卡
3:债务催收
4:信用报告
5:学生贷款
6:银行账户服务
7:短期小额贷款
8:汇款
9:预付卡
10:其他金融服务
认识数据
import pandas as pd
train_df = pd.read_csv("train.csv")
test_df = pd.read_csv("test.csv")
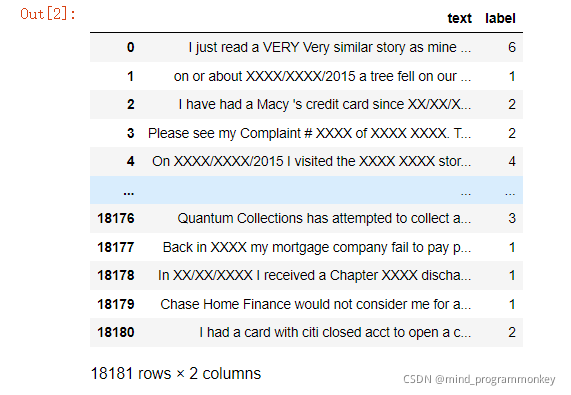
train_df
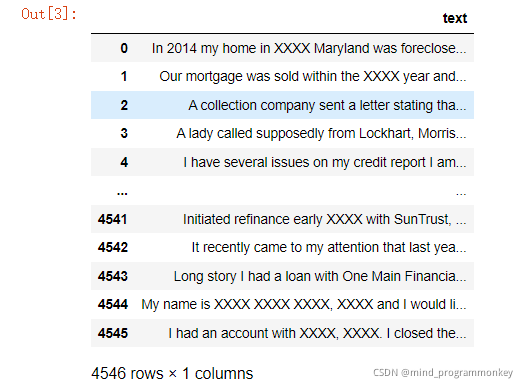
test_df
CatBoost分类
# 裸模86.9556,主要是认识一下俄罗斯很强大的学习模块Catboost
import pandas as pd
from catboost import CatBoostClassifier
import numpy as np
df1=pd.read_csv("./train.csv")
y = df1['label']
X_train = df1['text'].astype('str')
X_train=np.array(X_train)
df2=pd.read_csv("./test.csv")
X_test = df2['text'].astype('str')
X_test=np.array(X_test)
print(X_test.shape)
model = CatBoostClassifier(task_type='GPU')
model.fit(X_train, y,text_features=[0])
label=[]
for i in range(X_test.shape[0]):
label.append(model.predict([X_test[i]])[0])
dataframe = pd.DataFrame({'index':range(X_test.shape[0]),'label':label})
dataframe.to_csv("submisson.csv",index=False,header=False,sep=',')
SimpleTransformer模型训练预测
import warnings
warnings.simplefilter('ignore')
import numpy as np
import pandas as pd
from simpletransformers.classification import ClassificationModel
train = pd.read_csv('./train.csv')
test = pd.read_csv('./test.csv')
train.columns = ['text', 'labels']
train.head()

train_args={
'sliding_window': True,
'reprocess_input_data': True,
'overwrite_output_dir': True,
'logging_steps': 5,
'stride': 0.6,
'max_seq_length': 256,
"fp16":False,
'num_train_epochs': 5,
"train_batch_size":1,
"gradient_accumulation_steps":32
}
model = ClassificationModel('roberta', 'roberta-base', num_labels=11, args=train_args)
model.train_model(train)
predictions, _ = model.predict([row['text'] for _, row in test.iterrows()])
pd.DataFrame({'ID': test.index, 'labels': predictions}).to_csv('submission_roberta-large.csv', index=False, header=False)
小结
本次用机器学习的方法实现nlp相关的评论分类工作,那下次见!!!



















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











