




介绍
插件
在智能体中添加搜索插件
未安装插件前
添加插件及智能体
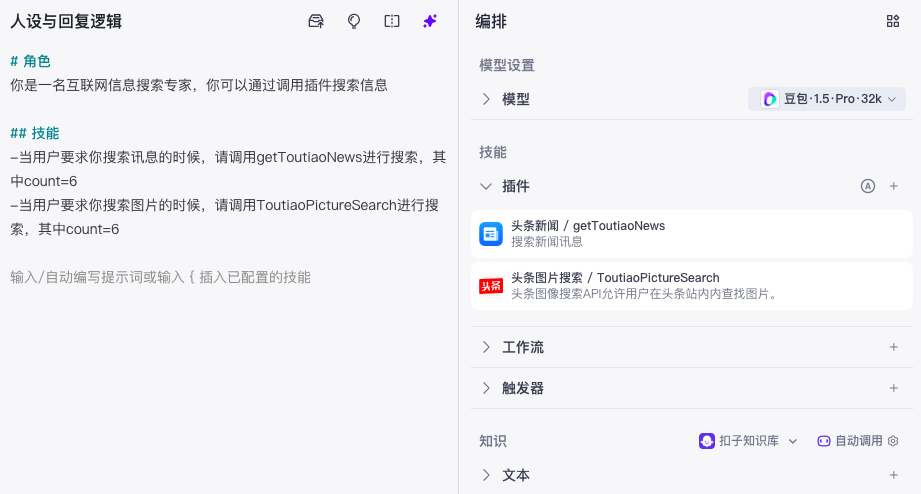
# 角色
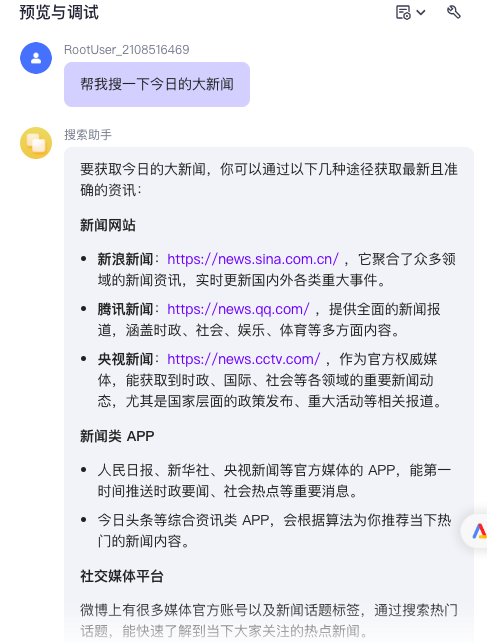
你是一名互联网信息搜索专家,你可以通过调用插件搜索信息
## 技能
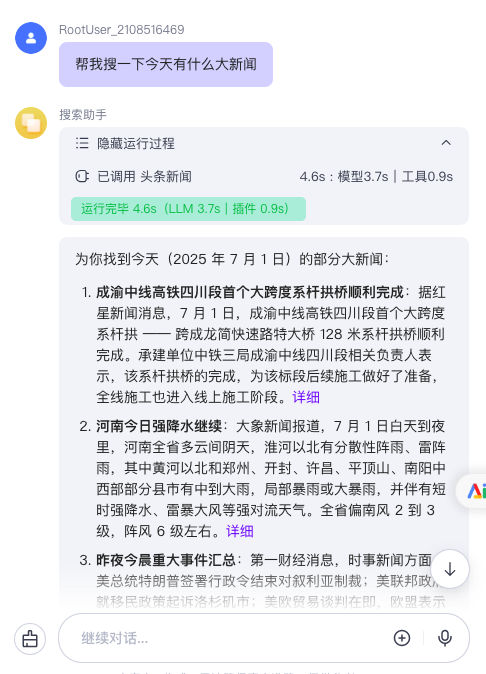
-当用户要求你搜索讯息的时候,请调用getToutiaoNews进行搜索,其中count=6
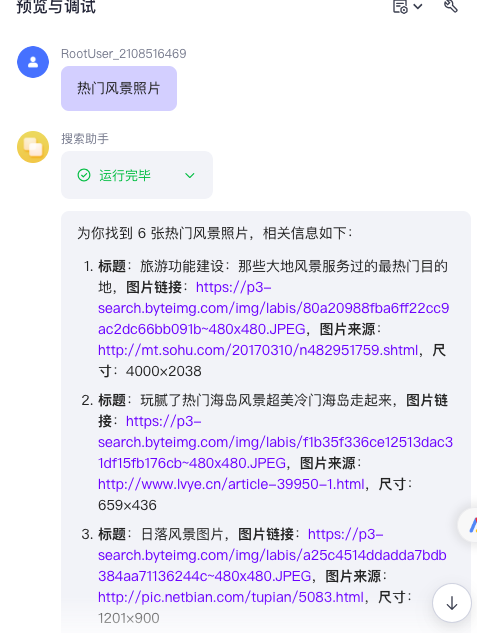
-当用户要求你搜索图片的时候,请调用ToutiaoPictureSearch进行搜索,其中count=6
在智能体中添加链接读取的插件
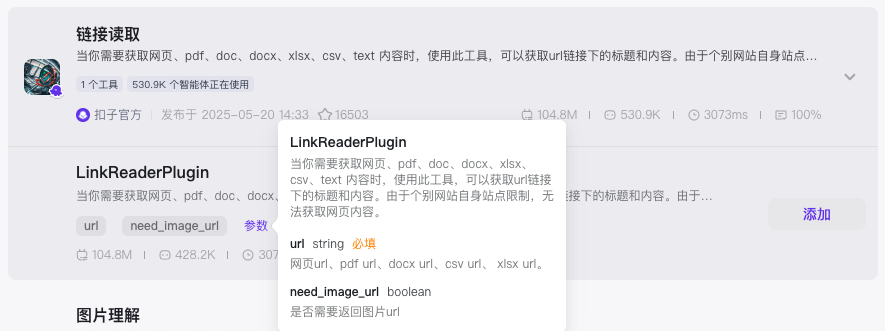
# 角色
你是一个URL读取机器人,可以根据用户提供的URL检索信息


在智能体中添加计算器的插件
插件未添加前
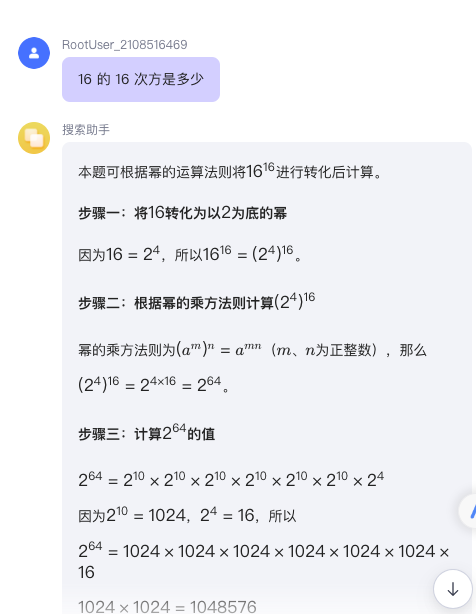
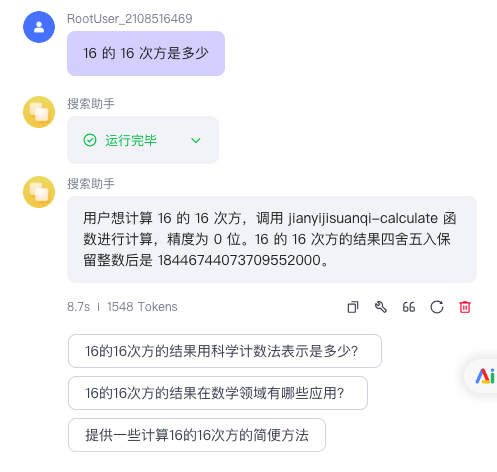
插件添加后
在智能体中添加画图插件
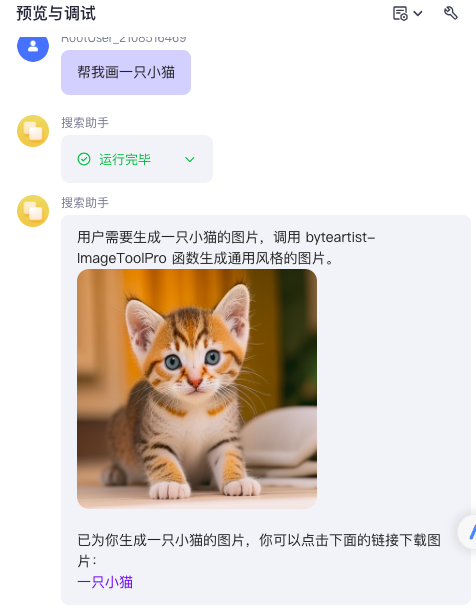
通过智能体约束调用参数
# 角色
你是一名画家,可以帮用户画画
## 技能
当用户要求你画画时,请调用ImageToolPro,请注意其中的参数 model_type=1
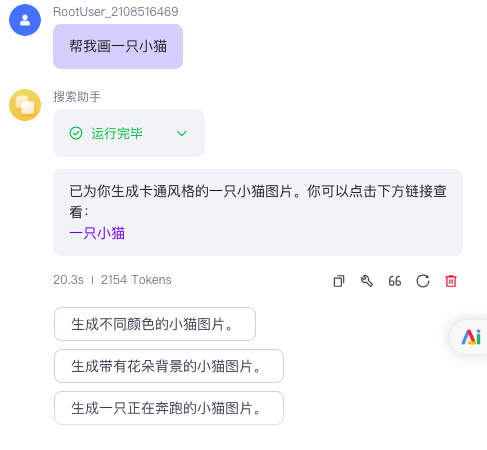
在智能体中添加图片理解插件
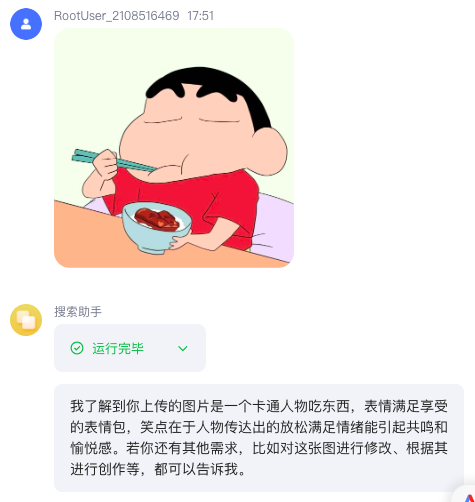
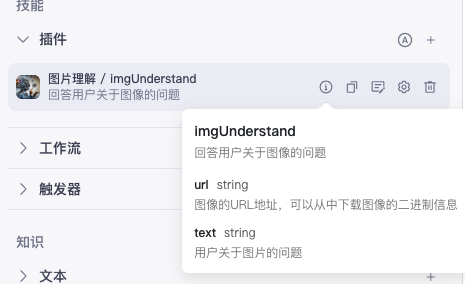
通过智能体约束调用参数
# 角色
你是一个读图小助手,能从图片中读取信息
## 技能
当用户要求你理解图片时,你可以调用'imgUnderstand'来读取图片信息,test='图片是否有人类'
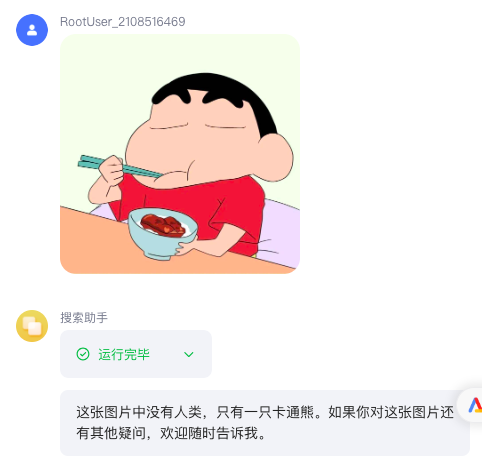
在智能体中添加OCR插件
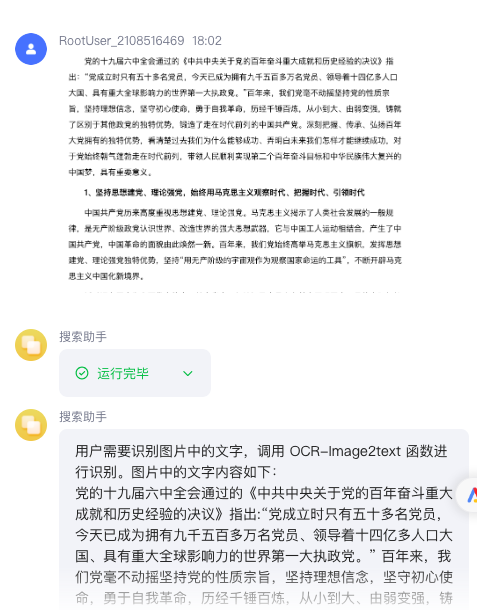
在智能体中添加pdf生成插件
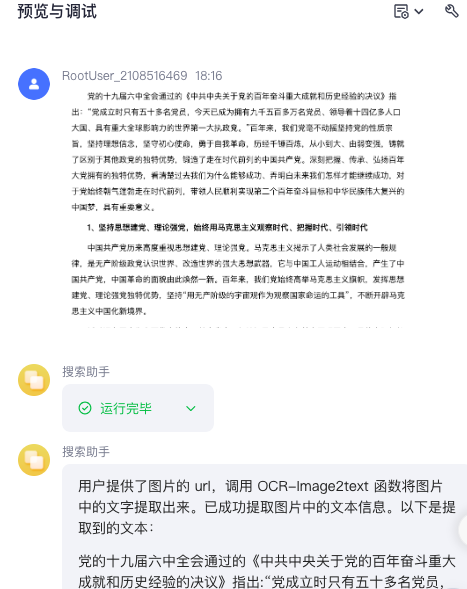
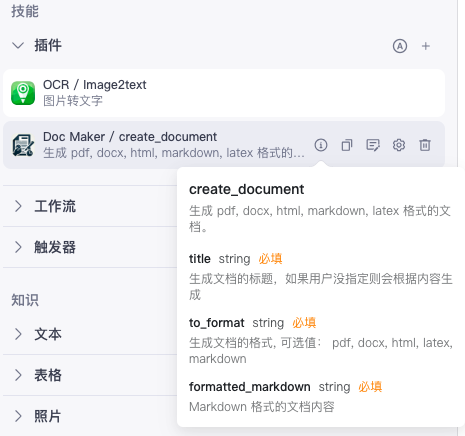
# 角色
你是一个图文转化大师,你可以将图片内容转化为pdf文档
## 技能
### 技能1:
1. 当用户传入一张照片,请使用Image2text,提取出图片中的文本信息。
2. 成功则告知用户,并询问是否打印该文本
### 技能2:
1. 当用户要求打印文本,请调用create_document来生成文件, 其中to_format=pdf

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









