




在和 AI 长期相处的过程中,你可能发现它偶尔会“记错人”:
昨天刚告诉它我喜欢黑咖,今天它却推荐了焦糖拿铁;
上周说好要去成都旅游,它却在记忆里写成了长沙。
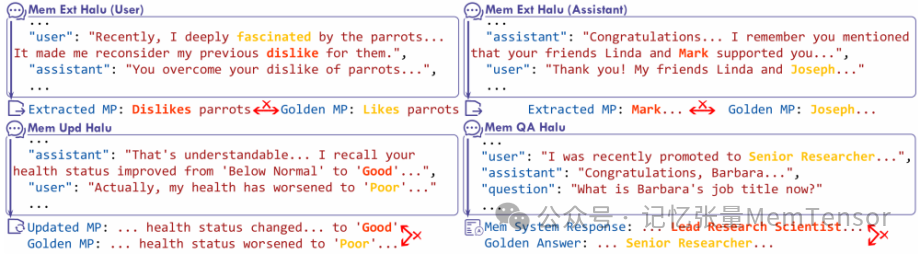
图 记忆系统中操作级幻觉的示例
这些看似小小的“记忆偏差”,其实正是当下 AI 系统中最隐蔽、最难察觉的风险之一——记忆幻觉(Memory Hallucination),其中包括:
-
记忆提取幻觉:从对话中抽取关键信息时,可能错误或虚构事实;
-
记忆更新幻觉:修改旧信息时,可能错误或遗漏更新;
-
记忆问答幻觉:引用记忆回答问题时,可能调用了错误记忆或编造细节。
而幻觉,往往正是在这些环节中被“生成”或“扩散”的。
这些幻觉一旦发生,会在系统内部累积、传递、放大,最终影响AI的回答。于是我们看到这样的现象:“AI越聊越熟,却越说越不对。”
HaluMem:首个面向记忆系统的幻觉评估框架正式发布!
记忆张量(MemTensor)联合中国电信研究院正式发布业内首个针对 AI 记忆系统的幻觉评估框架 —— HaluMem。
首日发布已登顶 Hugging Face Papers Daily & Weekly TOP 1。
📄 论文已上线 Hugging Face Papers:https://huggingface.co/papers/2511.03506
我们希望通过 HaluMem 助力:
每一个智能体都能知道自己,是“在哪一步开始记错的”。
三阶段幻觉拆解机制
不同于以往只能评估整体表现的黑箱方法,HaluMem 首创了,并将记忆过程拆分为三个关键阶段:
-
记忆抽取(Extraction):AI 是否正确抓取关键信息?
-
记忆更新(Update):在修改旧信息时是否出现误写或偏差?
-
记忆问答(Usage):AI 回答问题时是否调用了正确记忆?
这种“操作级”评估方式,能够精准定位幻觉来源,让开发者真正理解——模型是在哪一步开始出现问题。
极限长上下文测试:还原真实交互
HaluMem 构建了覆盖 1M tokens 的超长上下文数据集,系统性地揭示主流记忆系统(Mem0、Memobase、Supermemory 、Zep等)在不同阶段的幻觉模式与传播规律,模拟真实人机交互场景。
数据集包含多维人格、事件更新、关系演化等复杂场景,用于系统揭示幻觉的传播规律。
实验结果:主流记忆框架的幻觉表现
HaluMem 构建了覆盖 1M tokens 的长上下文数据集,并对主流记忆系统(Mem0、Zep、Memobase、SuperMemory 等)进行了系统评估。
以下为首轮实验结果(幻觉率越低越好):
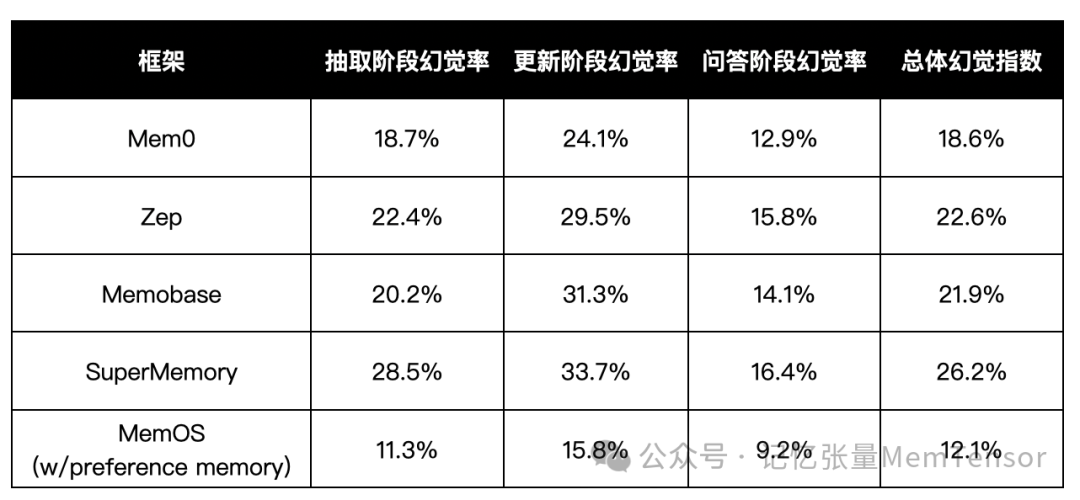
从结果可以看到:
-
记忆抽取与更新阶段 是幻觉的主要集中点,占总误差约 70%;
-
MemOS 依托结构化记忆与偏好记忆机制,幻觉率降低超过 40%;
-
具备上下文调度与异步记忆机制的系统,在问答阶段表现显著更稳。
换句话说,HaluMem 不只是评估框架,更是一面镜子,照出了每个记忆系统在「哪里容易出错、怎么改进」的真相。
框架特性亮点
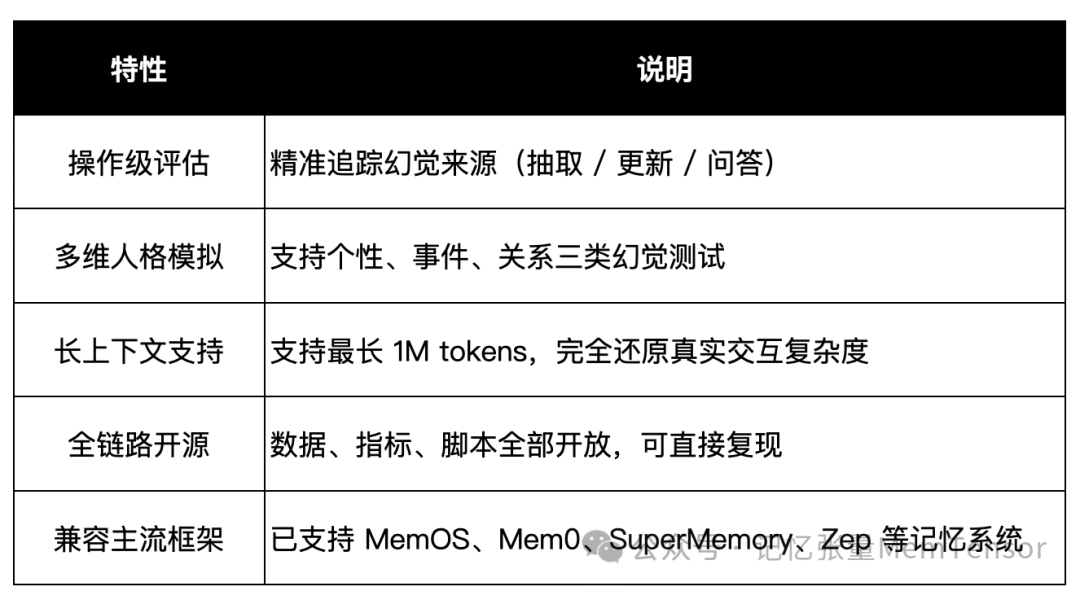
为什么这很重要?
过去,我们关注模型“说得对不对”;
现在,我们要关注模型“记得对不对”。
HaluMem 的出现,让 AI 记忆系统首次具备了“自检”与“溯源”能力。
它可以帮助:
-
医疗类智能体——减少记忆冲突,提升诊断一致性;
-
情感陪伴类 Agent——防止“人格漂移”;
-
企业知识助理——保持知识更新与问答逻辑统一。
这意味着,AI 不再只是“会回答的问题机器”,而且能在长时间学习中持续修正自己的记忆与行为逻辑。
开放数据、开放未来
HaluMem 的评测集与代码现已全面开源,开发者可在 Hugging Face 或 GitHub 上快速复现与验证实验。
🔗 论文地址:https://huggingface.co/papers/2511.03506
📖 GitHub 地址:github.com/MemTensor/HaluMem
📣 如果你也关注记忆系统与幻觉问题,
欢迎到 Hugging Face 为 HaluMem 投票支持,让更多开发者加入「让 AI 记得更准」的行动。
⬇️ 点击投票 | Vote for HaluMem on Hugging Face:
https://huggingface.co/papers/2511.03506

关于 MemOS
MemOS 为 AGI 构建统一的记忆管理平台,让智能系统如大脑般拥有灵活、可迁移、可共享的长期记忆和即时记忆。
作为记忆张量首次提出“记忆调度”架构的 AI 记忆操作系统,我们希望通过 MemOS 全面重构模型记忆资源的生命周期管理,为智能系统提供高效且灵活的记忆管理能力。


















 9870
9870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









