



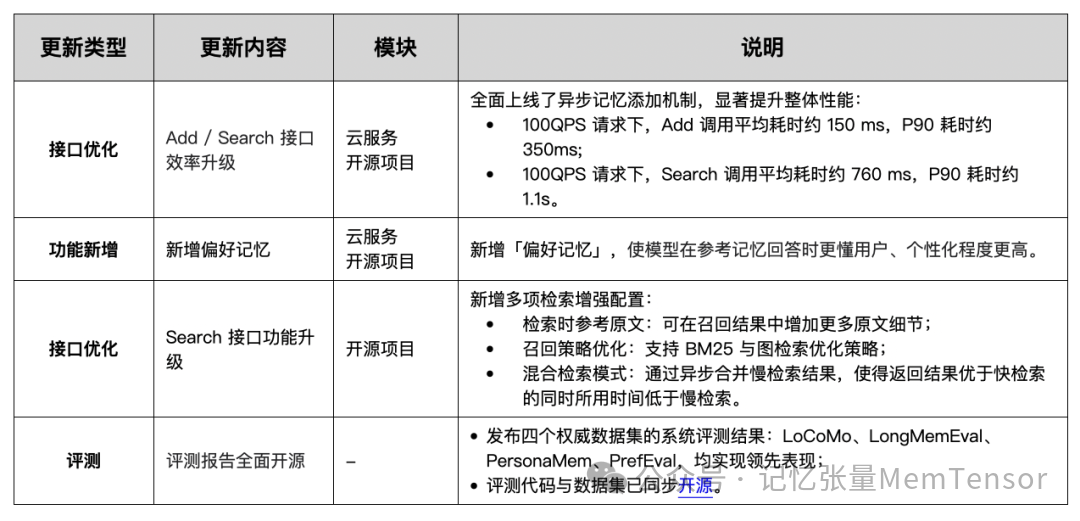
一、版本速览:性能与智能双跃升
本次更新,我们带来了 MemOS 全面的性能与智能升级。并围绕三个关键词进行优化:
-
更快 — 接口进入毫秒级响应,支持异步记忆添加;
-
更准 — 全面升级明文检索、BM25、图召回与混合检索策略;
-
更懂你 — 新增偏好记忆,让模型真正理解你的风格与选择。
与此同时,我们还首次发布了 LoCoMo、LongMemEval、PersonaMem、PrefEval 四项权威评测的完整结果与代码。
评测数据:
https://huggingface.co/datasets/MemTensor/MemOS_eval_result
脚本:
https://github.com/MemTensor/MemOS/tree/main/evaluation/scripts
现已全面开源,欢迎各位小伙伴查看与复现。🎉
🌟 本次发布亮点一览
二、接口加速:记忆写入与搜索全面提速
在本次更新中,我们引入异步机制与调度模块,让记忆写入和检索真正进入“毫秒时代”。
MemOS 利用 MemReader 组件增强对记忆的理解。在之前的版本中,ADD 接口需要耗时数秒才能处理完整个记忆添加流程。
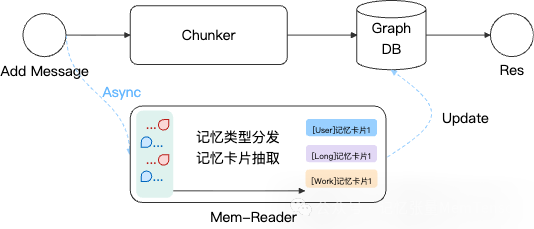
此次更新,我们先快速切片并入库用户添加的原始记忆,并在几百毫秒内返回成功,用户即添加、即消费,然后将整个 MemReader 的记忆处理过程依托于 MemSchedule 模块异步处理,实现用户的“无感精细处理”。
🧩 开源项目内快速配置异步添加记忆
# 开启异步添加模式 async: 异步添加 sync: 同步添加
ASYNC_MODE=async
# 打开记忆调度模块
MOS_ENABLE_SCHEDULER=true
☁️ 在云平台中使用异步添加记忆
当前,Add Message 接口已经新增了异步记忆添加机制,更新后用户上轮发送的消息能够即时被检索为记忆,保证对话中的上下文连续,解决了记忆添加延迟新记忆未能即时被检索的问题。
在云平台中,你的消息将即时被检索,无需等待同步延迟。
这意味着:刚说完的话,AI 立刻记得。
三、偏好记忆:让模型更懂你
在事实记忆之外,MemOS 新增了「偏好记忆(Preference Memory)」模块。
它能自动识别用户显式与隐式偏好,让模型在回答时更贴合个体语境。
📈 在 PrefEval 数据集中,偏好遵循正确率提升 20%+。
模型不止“记得你说过什么”,还能“理解你喜欢什么”。
🧩 开源项目内配置偏好记忆
# 配置Milvus向量数据库
MILVUS_URI=http://localhost:19530
MILVUS_USER_NAME=your milvus user name
MILVUS_PASSWORD=Your passward
# 开启偏好记忆
ENABLE_PREFERENCE_MEMORY=true
PREFERENCE_ADDER_MODE=fine # fast or fine
💡 TIPS:
1. PREFERENCE_ADDER_MODE 中,fast 更快,fine 重复率更低。
2. 开启偏好记忆不会增加 search 的耗时,会有少量 token 增加,具体取决于 pref_top_k。
☁️ 云平台中添加并检索偏好记忆
添加消息示例:
import os
import json
import requests
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
# headers 和 base URL
headers = {
"Authorization": f"Token {os.environ['MEMOS_API_KEY']}",
"Content-Type": "application/json"
}
BASE_URL = os.environ['MEMOS_BASE_URL']
# 示例历史对话数据
history_messages = [
{"role": "user", "content": "我暑假定好去广州旅游,住宿的话有哪些连锁酒店可选?"},
{"role": "assistant", "content": "您可以考虑【七天、全季、希尔顿】等等"},
{"role": "user", "content": "我选七天"},
{"role": "assistant", "content": "好的,有其他问题再问我。"}
]
def add_message(user_id, conversation_id, messages):
data = {
"user_id": user_id,
"conversation_id": conversation_id,
"messages": messages
}
res = requests.post(f"{BASE_URL}/add/message", headers=headers, data=json.dumps(data))
result = res.json()
if result.get('code') == 0:
print(f"✅ 添加成功")
else:
print(f"❌ 添加失败, {result.get('message')}")
# === 使用示例 ===
# 导入历史对话
add_message("memos_user_pref_test_777", "memos_conversation_pref_test777", history_messages)
检索记忆示例:
import os
import json
import requests
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
# headers 和 base URL
headers = {
"Authorization": f"Token {os.environ['MEMOS_API_KEY']}",
"Content-Type": "application/json"
}
BASE_URL = os.environ['MEMOS_BASE_URL']
# 用户当前query
query_text = "我国庆想出去玩,帮我推荐个没去过的城市,以及没住过的酒店品牌"
data = {
"user_id": "memos_user_pref_test_777",
"conversation_id": "memos_conversation_pref_test777",
"query": query_text,
}
# 调用 /search/memory 查询相关记忆
res = requests.post(f"{BASE_URL}/search/memory", headers=headers, data=json.dumps(data))
print(f"result: {res.json()}")
# 示例返回(为了方便理解此处做了简化,仅供参考)
# 偏好类型的记忆
# preference_detail_list [
# {
# "preference_type": "implicit_preference", #隐性偏好
# "preference": "用户可能偏好性价比较高的酒店选择。",
# "reasoning": "七天酒店通常以经济实惠著称,而用户选择七天酒店可能表明其在住宿方面倾向于选择性价比较高的选项。虽然用户没有明确提到预算限制或具体酒店偏好,但在提供的选项中选择七天可能反映了对价格和实用性的重视。",
# "conversation_id": "0610"
# }
# ]
# 事实类型的记忆
# memory_detail_list [
# {
# "memory_key": "暑假广州旅游计划",
# "memory_value": "用户计划在暑假期间前往广州旅游,并选择了七天连锁酒店作为住宿选项。",
# "conversation_id": "0610",
# "tags": [
# "旅游",
# "广州",
# "住宿",
# "酒店"
# ]
# }
# ]
通过示例代码,大家可以发现:模型自动记录了“七天酒店”作为显式偏好,同时推断出隐式偏好:“用户倾向于性价比高的住宿选项”。
未来,你的 AI 将能更好地优化推荐与响应。
四、检索增强:更准确的上下文理解
MemOS 在本次更新中引入了多层次的检索增强策略,让模型在长文本与复杂语境中表现更稳定。
-
原文检索:增加原始上下文细节,避免信息压缩导致的语义丢失;
-
图检索(Graph Search):结合 BM25 与图召回,实现语义级的相关性匹配;
-
混合检索(Mixture Mode):异步合并慢检索结果,保证结果质量优于快检索、耗时低于慢检索。
📈 在 LoCoMo 与 LongMemEval 中:
-
LoCoMo 指标提升约 +1pt;
-
LongMemEval 单轮任务表现提升显著。
🧩 开源项目内配置原文检索
#原始reranker配置
MOS_RERANKER_BACKEND=http_bge
MOS_RERANKER_URL=http://xxxxx:xxxx/v1/rerank
#开启reranker重排策略
MOS_RERANKER_BACKEND=http_bge_strategy
MOS_RERANKER_STRATEGY=single_turn
MOS_RERANKER_URL=http://xxxxx:xxxx/v1/rerank
💡 TIPS:
开启重排策略后会显著增加 context 长度,请根具自己需求进行配置开启
🧩 开源项目内配置图检索
# 添加启用则配置,不添加则不启用
FAST_GRAPH=true # 图检索
BM25_CALL=true # 关键词检索
💡 TIPS:
启用 graph 优化不增加耗时,启用 BM25 则耗时长。
🧩 在开源项目内配置混合检索
SEARCH_MODE=mixture
API_SEARCH_WINDOW_SIZE=5
API_SEARCH_HISTORY_TURNS=5
五、评测结果:领先四大权威数据集
MemOS 在四项公开基准中均取得领先表现,展现了系统在长程记忆、上下文保持与偏好理解方面的综合优势。
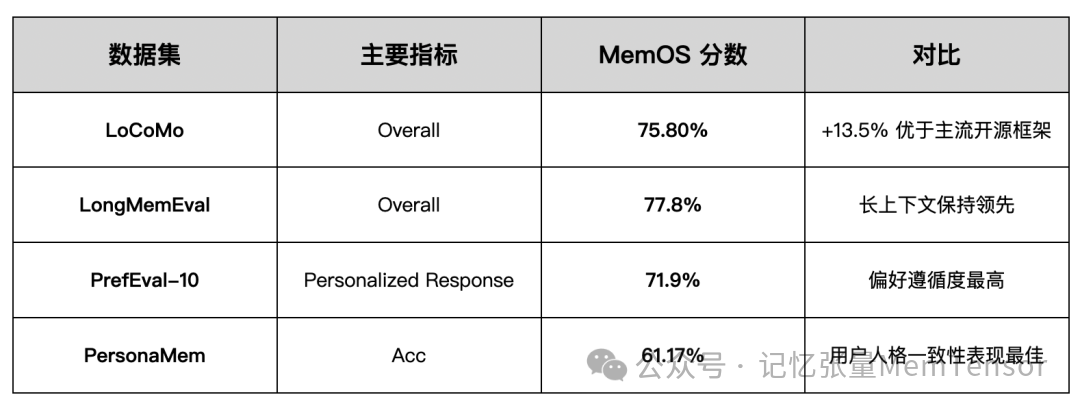
📘 评测代码与数据集已全面开源,详细结果已发布至 Hugging Face :
https://huggingface.co/datasets/MemTensor/MemOS_eval_result
六、开源更新:调度、检索、评测体系全面进化
New Features:
-
Async Add 支持明文与偏好记忆
-
Scheduler 模块化调度
-
Graph/BM25 混合检索
-
PrefEval 字段标准化
Improvements:
-
Redis ORM 优化
-
API 路由重构
-
上下文追踪增强
Fixes:
-
修复 PolarDB 边界问题 (#406/#445)
-
统一 Milvus 接口与日志链路
✨ 写在最后
从“记忆更快”,到“记忆更准”,再到“更懂你”,这不再只是让模型“记得”,而是让模型“理解记忆”——理解你的偏好、语境与风格,构建专属的长程智能体体验。
🚀 一键体验云平台
立即进入 MemOS 云平台,体验毫秒级记忆与偏好召回能力。
🔗 https://memos-dashboard.openmem.net/
💾 加入开源项目,共建记忆生态
欢迎访问我们的 GitHub:
🔗 https://github.com/MemTensor/MemOS
如果你喜欢我们的工作,请一键三连:
⭐️ Star 🍴 Fork 👀 Watch
并欢迎通过 Issue 提交你的使用反馈、优化建议或 Bug 报告。
🔗 https://github.com/MemTensor/MemOS/issues
关于 MemOS
MemOS 为 AGI 构建统一的记忆管理平台,让智能系统如大脑般拥有灵活、可迁移、可共享的长期记忆和即时记忆。
作为记忆张量首次提出“记忆调度”架构的 AI 记忆操作系统,我们希望通过 MemOS 全面重构模型记忆资源的生命周期管理,为智能系统提供高效且灵活的记忆管理能力。

















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









