



初识爬虫
学习爬虫之前,我们首先得了解什么是爬虫。
来自于百度百科的解释:
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
通俗来讲,假如你需要互联网上的信息,如商品价格,图片视频资源等,但你又不想或者不能自己一个一个自己去打开网页收集,这时候你便写了一个程序,让程序按照你指定好的规则去互联网上收集信息,这便是爬虫,我们熟知的百度,谷歌等搜索引擎背后其实也是一个巨大的爬虫。
爬虫合法吗?
可能很多小伙伴都会又这个疑问,首先爬虫是一门技术,技术应该是中立的,合不合法其实取决于你使用目的,是由爬虫背后的人来决定的,而不是爬虫来决定的。另外我们爬取信息的时候也可以稍微‘克制’一下,能拿到自己想要的信息就够了。
一般来说只要不影响人家网站的正常运转,也不是出于商业目的,人家一般也就只会封下的IP,账号之类的,不至于法律风险。
其实大部分网站都会有一个robots协议,在网站的根目录下会有个robots.txt的文件,里面写明了网站里面哪些内容可以抓取,哪些不允许。
以淘宝为例——https://www.taobao.com/robots.txt

robots协议本身也只是一个业内的约定,是不具有法律意义的,所以遵不遵守呢也只能取决于用户本身的底线了。
为什么使用Python?
很多人提到爬虫就会想到Python,其实除了Python,其他的语言诸如C,PHP,Java等等都可以写爬虫,而且一般来说这些语言的执行效率还要比Python要高,但为什么目前来说,Python渐渐成为了写很多人写爬虫的第一选择,我简单总结了以下几点:
- 开发效率高,代码简洁,一行代码就可完成请求,100行可以完成一个复杂的爬虫任务;
- 爬虫对于代码执行效率要求不高,网站IO才是最影响爬虫效率的。如一个网页请求可能需要100ms,数据处理10ms还是1ms影响不大;
- 非常多优秀的第三方库,如requests,beautifulsoup,selenium等等;
本文后续内容也将会以Python作为基础来进行讲解。
环境准备
- Python安装,这部分可以参考优快云内的文章会有很多教程,去官网下载对应的安装包,一路Next安装就行了;
- pip安装,pip是Python的包管理器,现在的Python安装包一般都会自带pip,不需要自己再去额外安装了;
- requests,beautifulsoup库的安装,通过以下语句来完成安装:
pip install requests
pip install beautifulsoup4
第三方库介绍
requests
requests应该是用Python写爬虫用到最多的库了,同时requests也是目前Github上Star最多的Python开源项目。
requests在爬虫中一般用于来处理网络请求,接下来会用通过简单的示例来展示requests的基本用法。
1.首先我们需要导入requests模块;
import requests2.接着我们尝试向baidu发起请求;
r = requests.get('https://www.baidu.com/')3.我们现在获得来命名为r的response对象,从这个对象中我们便可以获取到很多信息,如:
- 状态码,
200即为请求成功 - 页面HTML5代码
# 返回请求状态码,200即为请求成功
print(r.status_code)
# 返回页面代码
print(r.text)
# 对于特定类型请求,如Ajax请求返回的json数据
print(r.json())4.当然对于大部分网站都会需要你表明你的身份,我们一般正常访问网站都会附带一个请求头(headers)信息,里面包含了你的浏览器,编码等内容,网站会通过这部分信息来判断你的身份,所以我们一般写爬虫也加上一个headers;
#添加headers
headers = {'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit'}
r = requests.get('https://www.baidu.com/', headers=headers)5.针对post请求,也是一样简单;
#添加headers
headers = {'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit'}
#post请求
data = {'users': 'abc', 'password': '123'}
r = requests.post('https://www.weibo.com', data=data, headers=headers)6.很多时候等于需要登录的站点我们可能需要保持一个会话,不然每次请求都先登录一遍效率太低,在requests里面一样很简单;
#保持会话
#新建一个session对象
sess = requests.session()
#先完成登录
sess.post('maybe a login url', data=data, headers=headers)
#然后再在这个会话下去访问其他的网址
sess.get('other urls')beautifulsoup
当我们通过requests获取到整个页面的HTML5代码之后,我们还得进一步处理,因为我们需要的往往只是整个页面上的一小部分数据,所以我们需要对页面代码HTML5解析然后筛选提取出我们想要对数据,这时候beautifulsoup便派上用场了。
beautifulsoup之后通过标签+属性的方式来进行定位,比如说我们想要百度的logo,我们查看页面的HTML5代码,我们可以发现logo图片是在一个div的标签下,然后class=index-logo-srcnew这个属性下。
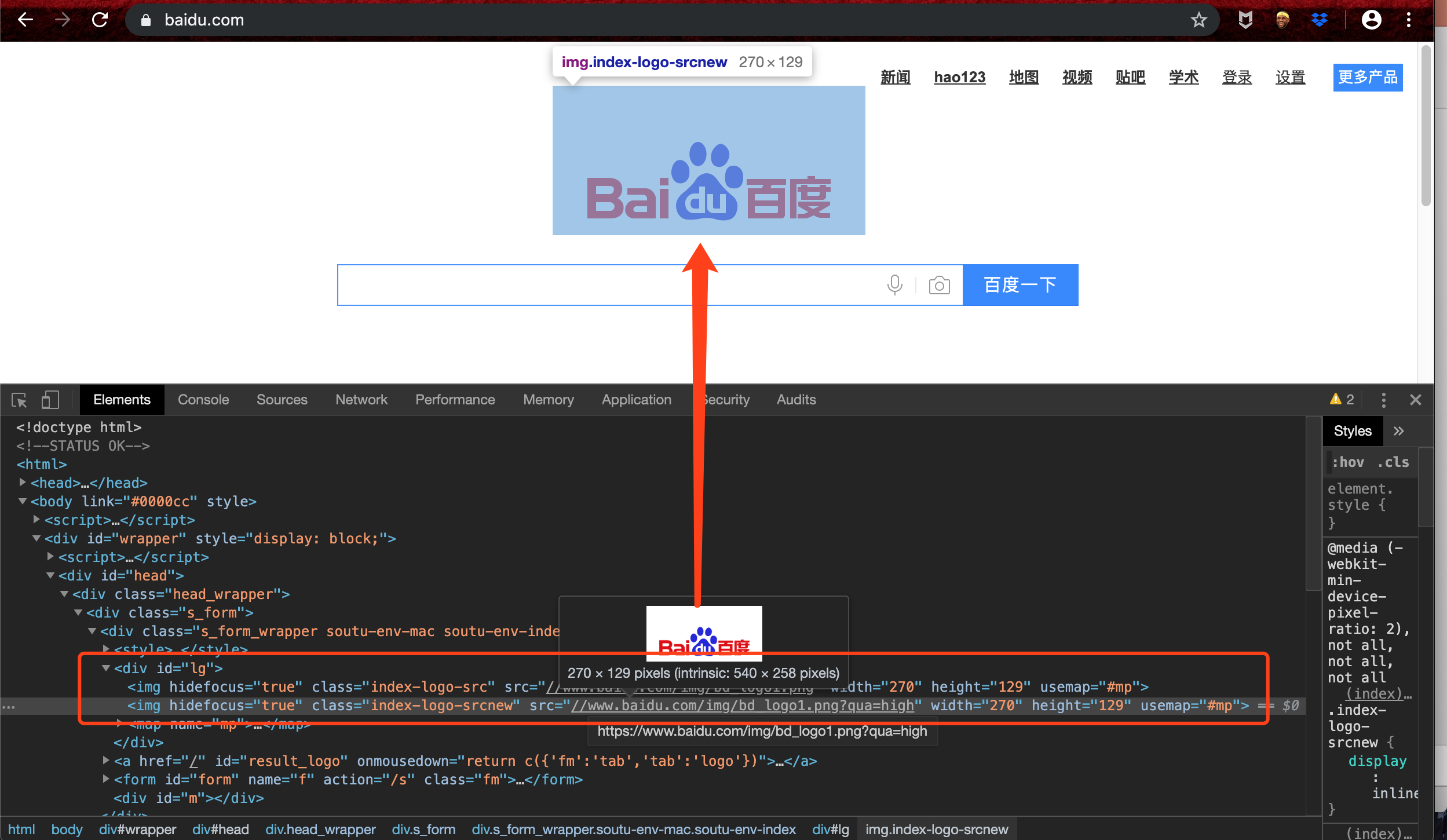 所以我们如果需要定位logo图片的话便可以通过
所以我们如果需要定位logo图片的话便可以通过div和class=index-logo-srcnew来进行定位。
下面也会提供一些简单的示例来说明beautifulsoup的基本用法:
1.导入beautifulsou模块;
from bs4 import BeautifulSoup2.对页面代码进行解析,这边选用对html代码是官方示例中使用的爱丽丝页面代码;
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# 选用lxml解析器来解析
soup = BeautifulSoup(html, 'lxml')3.我们现在获得一个命名为soup的Beautifulsoup对象,从这个对象中我们便能定位出我们想要的信息,如:
# 获取标题
print(soup.title)
# 获取文本
print(soup.title.text)
# 通过标签定位
print(soup.find_all('a'))
# 通过属性定位
print(soup.find_all(attrs={'id': 'link1'}))
# 标签 + 属性定位
print(soup.find_all('a', id='link1'))4.打印结果如下:
<title>The Dormouse's story</title>
The Dormouse's story
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]案例分享
获取17173新游频道下游戏名
具体步骤如下:
- F12打开控制台,选择element标签查看页面代码;
- 点击控制台左上角箭头,然后点击页面上我们需要的信息,我们可以看到控制台中页面代码直接跳转到对应的位置;
- 页面代码中一直向上选择标签直至囊括我们需要的所有信息;
- 记住此时的标签以及熟悉等信息,这将会用于后面解析筛选数据。

- 接下来便可以开始敲代码了,完整代码如下,对于每个步骤均有详细的注释:
from bs4 import BeautifulSoup
import requests
# 页面url地址
url = 'http://newgame.17173.com/game-list-0-0-0-0-0-0-0-0-0-0-1-2.html'
# 发送请求,r为页面响应
r = requests.get(url)
# r.text获取页面代码
# 使用lxml解析页面代码
soup = BeautifulSoup(r.text, 'lxml')
# 两次定位,先找到整个信息区域
info_list = soup.find_all(attrs={'class': 'ptlist ptlist-pc'})
# 在此区域内获取游戏名,find_all返回的是list
tit_list = info_list[0].find_all(attrs={'class': 'tit'})
# 遍历获取游戏名
# .text可获取文本内容,替换掉文章中的换行符
for title in tit_list:
print(title.text.replace('\n', ''))
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









