




 本文介绍如何使用Python爬虫抓取网络上的图片和文章。详细解释了爬虫的工作原理及requests库的具体应用,包括图片的下载与保存、网页内容的抓取与存储。
本文介绍如何使用Python爬虫抓取网络上的图片和文章。详细解释了爬虫的工作原理及requests库的具体应用,包括图片的下载与保存、网页内容的抓取与存储。
1.平时我们在网上浏览下载东西的时候通常有这几个步骤:
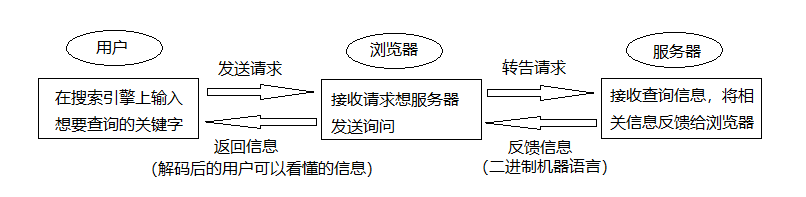
用户收到信息后:提取有用数据--->保存数据
- 那么爬虫在这里都做了什么工作呢?
A: 她代替了浏览器和服务器的工作,用户只要输入关键信息通过爬虫就可完成:浏览器与服务器的交互---->解码数据---->提取数据---->储存数据
2.使用爬虫在互联网上爬取图片和文章
- 首先需要一个自己的浏览器安装一个requests模板:打开dos命令输入(pip install requests)
若出现版本不对应问题需要更新的报错问题:可使用管理员权限打开dos输入pip install requests可解
①爬取图片
import requests
res = requests.get('http://b-ssl.duitang.com/uploads/item/201809/14/20180914140434_tyswq.jpg')
#requests.get()函数获取想要下载的图片地址
photo = res.content
#res.content()函数将获取到的图片数据转换成二进制
img = open('zyl.jpg','wb')
#将获取到的图片以‘zyl.jpg’这个名字保存,以‘wb’方式读写(打开文件)
img.write(photo)
#将photo得到的数据写入img(写文件)
img.close()
#关闭文件
②爬取文章
import requests
res = requests.get('https://www.qisuu.la/du/24/24704/9220420.html')
res.encoding='utf-8'
#解码方式自定义为utf-8
novel = res.text
book = open('白夜行.txt','a+')
#将文件命名为'白夜行.txt',保存方式‘a+’追加方式
book.write(text)
book.close()

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









