




 本文提出了一种名为M2S-Net的深度学习模型,用于解决文本相似度问题。M2S-Net基于多模态相似度度量学习,通过成对令牌匹配的深度卷积网络增强词汇层面上的相互依存关系。实验结果显示,该模型在TREC-QA数据集上取得了优于现有方法的性能。
本文提出了一种名为M2S-Net的深度学习模型,用于解决文本相似度问题。M2S-Net基于多模态相似度度量学习,通过成对令牌匹配的深度卷积网络增强词汇层面上的相互依存关系。实验结果显示,该模型在TREC-QA数据集上取得了优于现有方法的性能。
文章地址:https://arxiv.org/pdf/1604.05519v1.pdf
文章标题:Multi-Modal Similarity Metric Learning for Answer Selection(答案选择的多模态相似度度量学习)2018
Abstract
近年来,基于分布式词表示的人工神经网络的研究工作极大地提高了答案选择问题的性能。然而,以往的研究大多采用深度学习的方法(如LSTM-RNN、CNN等),主要是对每个句子单独进行语义表征,忽略了词汇层面上的相互依存关系。本文在成对令牌匹配的基础上直接构造了一个深度卷积网络,然后采用多模态相似度度量学习来丰富词汇模态匹配。该模型通过在答案选择基准(即,TREC-QA数据集),在MAP和MRR指标。
一、Introduction
受到卷积网络的成就的启发。在计算机视觉领域,越来越多的研究者构建了各种自然语言处理任务的ConvNets,如文本分类(Kim, 2014)、文本回归(Bitvai和Cohn, 2015)、短文本对重新排序(Severyn和Moschitti, 2015)和语义匹配(Hu等,2014)。
对于答案选择任务,即,给定一个问题和一组候选句子,选择包含准确答案的正确句子,并充分支持答案的选择。以往的方法大多是通过构造Siamese-like深度结构(如LSTM-RNN、CNN等)来学习每个句子的语义表示,然后利用余弦相似度或权值矩阵来计算成对表示的相似度(Wang and Nyberg, 2015)。同时,这些作品多采用浅层架构进行句子建模,因为更深的网并没有带来更好的性能。相反,我们坚信可以从深度学习策略中获益更多。
随着基于RNN的机器翻译注意机制的成功(Bahdanau et al., 2014),最近有一些研究尝试了句子对匹配问题的双向注意机制(Tan et al., 2015;桑托斯等人,2016;Yin等,2015)。这种软注意机制证明了从词汇级到语义级句子对之间相互作用的有效性,但同时也增加了计算量和模型复杂度。
前面的工作激励我们构建一个基于成对标记匹配的穷举匹配学习网络。然而,这种构成的一个重要问题是单词相似性度量。以表1中的Q和A为例,区分“begin”与“founded:set up”与“begin”与“found:discovered”之间的相似性很有意义。为了解决这一问题,我们构建了一个基于多模态相似度度量学习的成对令牌匹配的深度卷积神经网络。在回答选择任务的基准数据集上的实验结果表明,该模型能够从深度网络结构和多模态相似度度量学习中获得很大的好处,同时也证明了该模型优于各种强基线,达到了最新的水平。

表一:An example of QA-pair in TREC-QA(TREC-QA数据集中一个QA对的例子)
二、M2S-Net
在本文中,我们提出一个新颖的学习句子框架对匹配,首先计算成对的令牌相似矩阵,然后构造深层卷积网络来详细学习匹配表示,最后连接学习成对匹配表示和额外的简单句重叠特性,并为端到端微调加入point-wise rank loss(请参见图1)。
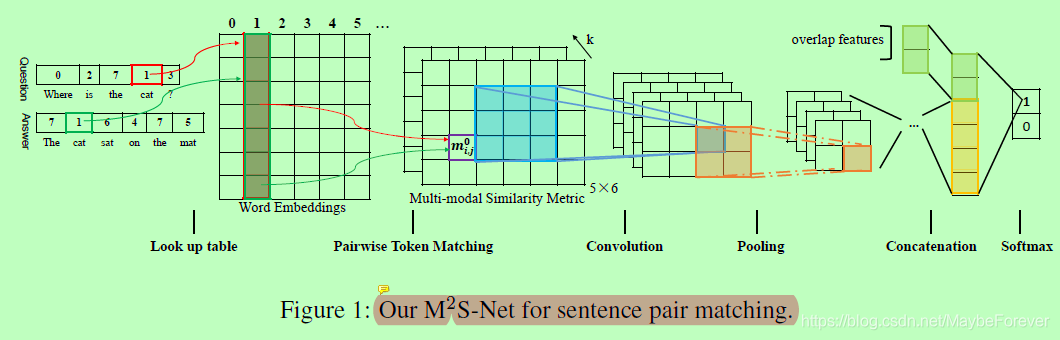
图一:我们的M2S-Net用于句子对匹配。
2.1 Multi-Modal Similarity Metric(多模式的相似性度量)
作为M2S-Net的基础组件,设计合适的相似度度量fmatch来进行成对的标记匹配至关重要。给定一个句子对S1和S2,其中l1和l2分别是是句子S1和S2的字数,wi1和wj2是来自于d维的词嵌入W(W经过词汇V的预训练),相似度矩阵M如下:
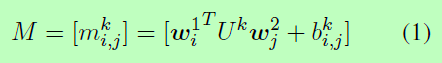
k代表可以被调整形态的数量,Uk表示表示可学习相似度度量的矩阵,它对应的偏置项为Bk。由于度量Uk的维数随嵌入维数的增加呈指数增长,因此提出了一些正则化方法(Shalit et al., 2010; Caoet al., 2013)为了防止过拟合而限制模型的复杂性。为了简化,这里采用了弗洛贝尼乌斯范数。为了更好的比较,我们还设计了余弦相似度和欧几里德相似度,公式如下:
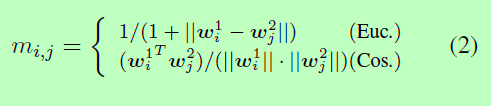
2.2 Convolution and Pooling
在我们的工作中卷积层由滤波器组F组成,与滤波器偏置b,其中w、h为滤波器的宽度和高度的数字,c表示来自底层的数据通道。更具体地说,对于第一个卷积层,c等于多模态参数k,这意味着对所有的相似模态进行卷积来学习特征。给定下层的输出Lt-1,计算与滤波器组F卷积的输出如下:
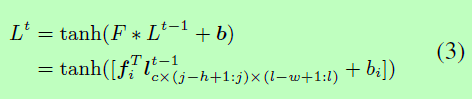
其中*被标记为卷积运算,i对滤波器的数量进行索引,j和l表示沿宽度和高度轴一步生成点的滑动运算。
一般来说,存在两种类型的卷积:宽卷积和窄卷积。尽管之前的工作(Kalchbrenner et al., 2014)已经指出使用宽类型的卷积可以获得更好的性能,但是为了方便,我们使用窄类型的卷积。最后,我们得到t层的输出Lt。
然后,来自卷积层(通过激活函数传递)的输出被送入池化层,池化层的目标是聚合信息并减少表示。从技术上讲,存在两种类型的池策略,即,平均池化和最大池化,这两种池方法都被广泛使用。但是,max pooling会导致训练数据过拟合性强,测试数据泛化性差,如(Zeiler and Fergus, 2013)。为了稳定和可再生产力,我们在工作中采用平均池化策略。
2.3 Pointwise Learning to Rank with Metric Regularization(点态学习与度量正则化排序)
我们采用简单的点态方法来模拟我们的答案选择任务,尽管两两配对和列表方式都声称能产生更好的性能。交叉熵损失函数在这里部署,以区别训练我们的框架如下:
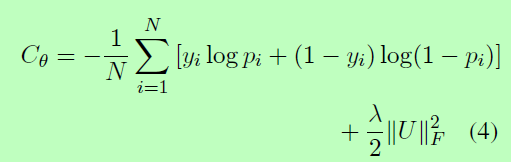
其中pi为通过网络的第i个样本的输出概率,yi是相应的ground truth,并且θ包含由网络优化的所有参数。采用弗洛贝尼乌斯范数对矩阵的参数U进行正则化,以防止过拟合。
我们使用随机梯度下降(SGD)来优化我们的网络,并使用AdaDelta (Zeiler, 2012)来自动调整训练过程中的学习率。为了获得更高的性能,在开发集上进行超参数选择,并在每个卷积层之后添加Batch Normalization (BN)层(Ioffe and Szegedy, 2015),以加速网络优化。此外,在第一个隐含层之后应用dropout进行正则化,并使用early stop防止过拟合,采用5个epoch。
三、Experiments
3.1 Dataset
在本节中,我们使用TREC-QA数据集来评估所提出的模型,该模型似乎是最广泛使用的答案句子选择基准之一。该数据集是由(Wang et al., 2007)基于文本检索会议(Text REtrieval Conference, TREC) QA track (8-13) data1创建的。每个事实性的问题都会自动检索候选答案。提供了两组训练数据,一组是小训练集,包含94道人工判断题,另一组是全训练集,即它包含了1229个问题,全部来自TREC 8-12系列,通过匹配答案键的正则表达式自动标记为ground truth。表2详细总结了答案选择数据集。在接下来的实验中,我们使用完整的训练集,因为它的规模比较大,即使存在自动模式匹配产生的噪声标签。
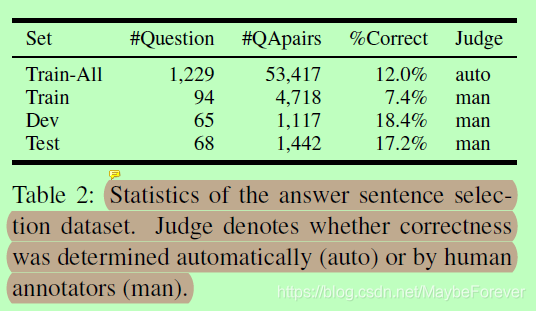
表二:答案句选择数据集的统计信息。Judge表示正确性是由自动(auto)还是由人工注释器(man)确定的。
原始的开发和测试数据集分别有82和100个问题。(Wang and Nyberg, 2015;桑托斯等人,2016;所有只有肯定或否定答案的问题都被删除。最后,我们有65个开发问题,1,117个问题-答案对,68个测试问题,1,442个问题-答案对。
3.2 Token Representation(令牌表示)
我们使用一个预先训练好的50维单词嵌入式表(Pennington et al., 2014)作为我们的初始单词查找表。这些词嵌入是根据维基百科的数据和第五个英语十亿词,总共有60亿个标记。这里需要提到的是,在模型的复杂性和性能之间进行权衡,我们没有使用300维的嵌入,这是在更多的数据上训练和更广泛地采用以前的工作(桑托斯等,2016;Tan等人,2015)。
3.3 Experimental Setting
根据之前的工作,我们还使用这两个度量来评估所提出的模型,即,平均平均精度(MAP)和平均倒数秩(MRR)。官方的trec_eval记分工具用于计算上述指标。
计算出每个问答对之间最简单的单词重叠特征,并将它们与我们学习到的匹配表示法连接起来进行最终的排序学习。这个特征向量只包含两个特征,即,单词重叠和IDF加权单词重叠。
我们的M2S-Net在三个预定义的相似性度量上的实验分别记为M2S-Net- euc、M2S-Net-cos和M2S-Net-metric。所有这些模型共享相同的网络配置。证明的事实,提出网络可以从深层结构获益更多,我们比较M2S-Net-Metric one-convolutional层网络,即M2S-Net-Shallow(我们发现更深层次结构的随机性可能带来危害的再现性的表现,所以我们使用two-convolutional层严格实验比较)。进一步,我们列出了k = 1,2,4时的M2S-Net-Metric的结果,分别表示为M2S-Net-Metric, M2S-Net-Metric-2和M2S-Net-Metric-4,以验证所提出的多模态相似度度量的有效性。这里提到的所有网络都是使用Caffe实现的(Jia et al., 2014),代码现在是开放的。
四、Results and Discussion
我们有动机使用多模态相似度度量来解决词的多义性,并构建句子对之间的完全匹配网络来进行端到端的问题回答建模。从图2可以看出,可以看出,onemodality比euclidean和余弦相似度度量稍微好一点。增加测量方式的数量将极大地提高7%的性能。通过对浅层和深层网络结构的比较,说明本文所提出的M2S-Net结构从深层网络结构中获益良多。表1中答案的秩为使用欧几里得和余弦相似度度量从前35名和前26名提升到使用我们的度量前3名。

图二:不同测量方法和网络结构下的M2S-Nets比较。
为了进行全面的比较,我们还在表3中列出了文献中关于这项任务的最新方法的结果。可以看出,该方法在MAP和MRR指标上都比最近发表的基于注意力的方法高出1%。
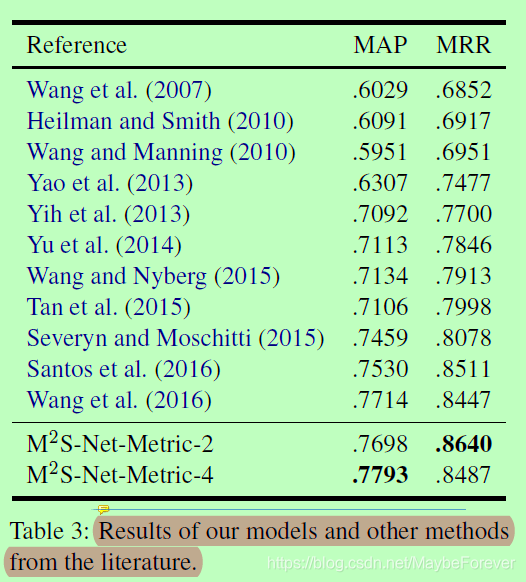
表三:我们的模型和其他文献方法的结果。
提出的方法可以进一步改进,通过升级正则化项来限制度量的秩,这已经被(Law et al., 2014;曹等,2013)证明。此外,将基于距离度量学习的相似性模型与本文所述的相似性模型相结合将是我们未来的工作。
五、Conclusion
提出了一种新的端到端学习框架(M2SNet),用于回答句子的选择。通过直接构造基于成对令牌匹配的深度卷积神经网络,进一步探讨了句子对在词法层面的相互依存关系。为了丰富词汇模态测量,我们采用了多模态相似度度量学习。所提出的架构被证明是有效的,并超越了以往最先进的系统的答案选择基准,即TREC-QA数据集,在MAP和MRR指标上。

















 423
423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









