




1 概述
Apache Spark 是一个为高效处理大规模数据而设计的分布式计算引擎。它采用分布式并行计算的方式,将数据拆分、计算、合并的任务分散到多台计算机上,从而实现了高效的数据处理和分析。
2 应用场景
大规模数据处理与分析
- Spark 能够处理海量数据,通过并行计算任务提高了处理效率。它广泛应用于金融、电信、医疗等领域的数据处理和分析。
流式数据处理
- Spark Streaming 允许实时处理数据流,将其转化为可供分析和存储的批处理数据。这在在线广告、网络安全等实时数据分析场景中非常有用。
机器学习
- Spark 提供了机器学习库(MLlib),支持多种机器学习算法和模型训练,用于推荐系统、图像识别等机器学习应用。
图计算
- Spark 的图计算库(GraphX)支持多种图计算算法,适用于社交网络分析、推荐系统等图分析场景。
本篇文档将介绍两种使用 Spark 计算引擎实现批量数据写入 MatrixOne 的示例。一种示例是从 MySQL 迁移数据至 MatrixOne,另一种是将 Hive 数据写入 MatrixOne。
3 前期准备
硬件环境
本次实践对于机器的硬件要求如下:

软件环境
本次实践需要安装部署以下软件环境:
- 已完成安装和启动 MatrixOne。
- 下载并安装 IntelliJ IDEA version 2022.2.1 及以上。
- 下载并安装 JDK 8+。
- 如需从 Hive 导入数据,需要安装 Hadoop 和 Hive。
- 下载并安装 MySQL Client 8.0.33。
4 示例一
从 MySQL 迁移数据至 MatrixOne
步骤一:初始化项目
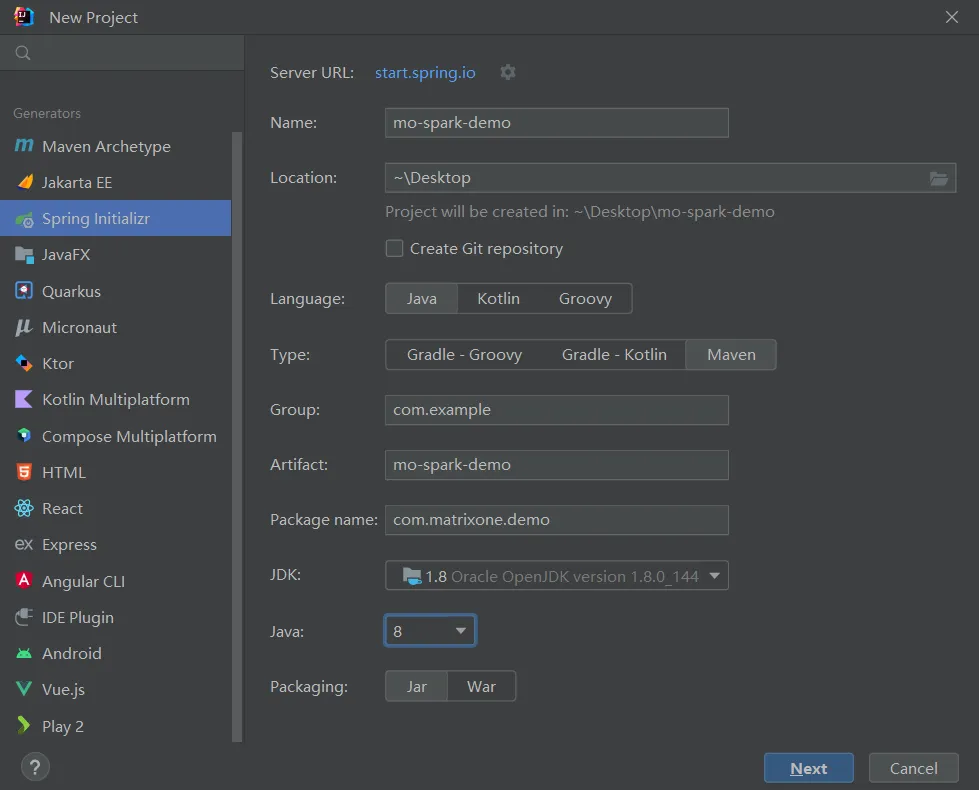
1. 启动 IDEA,点击 File > New > Project,选择 Spring Initializer,并填写以下配置参数:
- Name:mo-spark-demo
- Location:~\Desktop
- Language:Java
- Type:Maven
- Group:com.example
- Artiface:matrixone-spark-demo
- Package name:com.matrixone.demo
- JDK 1.8
2. 添加项目依赖,在项目根目录下的 pom.xml 内容编辑如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example.mo</groupId>
<artifactId>mo-spark-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<spark.version>3.2.1</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-catalyst_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<depe 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









