



✅作者简介:热爱科研的Matlab仿真开发者,擅长数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。
🍎 往期回顾关注个人主页:Matlab科研工作室
🍊个人信条:格物致知,完整Matlab代码及仿真咨询内容私信。
🔥 内容介绍
柔性车间调度问题(Flexible Job Shop Scheduling Problem, FJSP)是生产管理领域的一个经典难题,其目标是在满足各种约束条件的同时,优化生产效率、降低成本或缩短交货期。传统调度方法在面对车间环境的动态性和复杂性时往往难以取得最优解,尤其是在处理大规模、高并发的任务时。近年来,深度强化学习(Deep Reinforcement Learning, DRL)在解决序列决策问题上展现出巨大潜力。本文深入探讨了将多动作深度强化学习应用于柔性车间调度的问题。首先,我们构建了FJSP的强化学习模型,包括状态空间、动作空间和奖励函数的设计。特别地,我们提出了一种多动作机制,允许智能体在每个决策步同时选择多个加工任务和对应的机器,以应对FJSP的并行决策特性。其次,我们设计了基于深度神经网络的策略网络,用于学习从车间状态到多动作选择的映射。通过在多种规模的FJSP实例上进行仿真实验,结果表明,所提出的多动作深度强化学习方法在调度性能上优于传统的启发式算法和单一动作的强化学习方法,在缩短最大完工时间(Makespan)和提高设备利用率方面具有显著优势。本文的研究为解决复杂的柔性车间调度问题提供了一种新的、有效的智能优化途径。
关键词: 柔性车间调度;深度强化学习;多动作;最大完工时间;智能制造
1. 引言
随着工业4.0和智能制造的兴起,生产系统正向着高度自动化、柔性化和智能化的方向发展。柔性车间调度问题(FJSP)作为智能制造的核心环节之一,其重要性日益凸显。FJSP是传统车间调度问题(Job Shop Scheduling Problem, JSP)的扩展,其主要特点是每个工序可以在多台具备相同功能的机器上进行加工,这为调度带来了更大的柔性,但也极大地增加了问题的复杂性。FJSP通常被证明是NP-hard问题,这意味着对于大规模实例,不存在多项式时间内的最优解算法。
传统的FJSP求解方法主要包括精确算法、启发式算法和元启发式算法。精确算法(如分支定界法、混合整数规划)能够找到最优解,但其计算复杂度随问题规模呈指数级增长,难以应用于实际生产环境。启发式算法(如优先级规则、调度规则)虽然计算效率高,但其求解质量往往依赖于经验,且容易陷入局部最优。元启发式算法(如遗传算法、模拟退火、粒子群优化)通过模拟自然界或物理现象来搜索解空间,在一定程度上克服了启发式算法的缺点,但其参数调整复杂,且在处理动态调度问题时响应速度较慢。
近年来,以深度学习为代表的人工智能技术取得了突破性进展,并逐渐渗透到各个领域。深度强化学习(DRL)作为深度学习与强化学习的结合,在处理高维状态空间和复杂决策任务方面展现出强大能力。DRL通过让智能体在环境中不断试错,学习最优策略,这与FJSP的序贯决策特性高度契合。然而,将DRL直接应用于FJSP面临挑战,主要体现在以下几个方面:
- 状态空间和动作空间巨大:
FJSP的状态空间和动作空间会随着车间规模的增大而急剧膨胀,导致传统的DRL算法难以收敛。
- 多任务并行决策:
FJSP中通常存在多个可并行加工的任务,智能体需要同时做出多个决策,这给传统的单动作DRL模型带来了困难。
- 奖励函数设计:
如何设计有效的奖励函数以引导智能体学习到全局最优策略,是一个关键问题。
针对上述挑战,本文提出了一种基于多动作深度强化学习的柔性车间调度方法。我们创新性地设计了多动作机制,允许智能体在每个决策步同时选择多个可调度的任务和对应的机器,以更好地适应FJSP的并行加工特性。通过构建合适的强化学习模型,并结合深度神经网络的强大特征提取能力,旨在为FJSP提供一种高效、鲁棒的智能调度解决方案。
2. 柔性车间调度问题描述

3. 基于多动作深度强化学习的FJSP模型
为了将FJSP转化为强化学习问题,我们需要定义智能体、环境、状态、动作、奖励以及策略网络。
3.1 强化学习模型构建
3.1.1 智能体与环境
- 智能体:
调度决策者,负责在每个决策步选择一个或多个待加工工序及其对应的机器。
- 环境:
柔性车间,包括所有机器、工件、工序以及它们当前的状态(如机器忙碌状态、工件已完成工序、工序可加工状态等)。
3.1.2 状态空间设计

- 机器状态特征:
-
每台机器的当前繁忙状态(空闲/忙碌)。
-
每台机器的当前剩余加工时间(如果正在加工)。
-
每台机器的下一次可用时间。
-
- 工件/工序特征:
-
每个工件的当前已完成工序数量。
-
每个工件的下一个待加工工序的ID。
-
每个待加工工序的平均加工时间、最短加工时间、最长加工时间(在所有可选机器上)。
-
每个待加工工序的剩余工序数量。
-
每个待加工工序的所有可选机器及其对应的加工时间。
-
- 全局特征:
-
当前车间中最长的已完工时间。
-
所有已完工工序的数量与总工序数量的比值。
-
通过归一化处理,将这些特征映射到合适的数值范围,形成固定长度的向量作为神经网络的输入。
3.1.3 动作空间设计(多动作机制)
传统的强化学习模型通常只在每个决策步输出一个动作。然而,在FJSP中,往往存在多个工序可以在不同的机器上同时加工,这种并行性是FJSP的固有特性。为了充分利用这一特性,我们提出了多动作机制,允许智能体在每个决策步输出一个动作集合。


本文采用第二种策略,策略网络输出每个候选动作的Q值或概率值,然后根据这些值,智能体选择排名前K的动作,或者选择所有Q值高于某一阈值的动作。这些被选中的动作将同时执行,更新车间状态。
3.1.4 奖励函数设计
奖励函数是引导智能体学习的关键。由于我们的目标是最小化最大完工时间,奖励函数的设计应鼓励智能体做出能够缩短Makespan的决策。我们采用稀疏奖励和密集奖励相结合的方式。

3.2 深度强化学习算法
本文考虑采用Actor-Critic架构的深度强化学习算法,例如A2C (Advantage Actor-Critic) 或 PPO (Proximal Policy Optimization)。这些算法在处理连续和离散动作空间、以及大规模状态空间时表现良好。
Actor网络: 负责输出在给定状态下选择每个候选动作的概率分布。其输入是状态特征向量,输出是所有候选动作的概率值。


4. 结论与展望
本文提出了一种基于多动作深度强化学习的柔性车间调度方法。通过精心设计的状态空间、创新的多动作机制以及适配的深度强化学习算法,我们成功地构建了一个能够有效解决FJSP的智能调度模型。实验结果表明,与传统方法和单一动作DRL方法相比,所提出的MADRL-FJSP在最小化最大完工时间、提高设备利用率方面具有显著优势。
本研究为解决复杂的柔性车间调度问题提供了一个有前景的智能优化框架。未来研究方向包括:
- 异构多动作:
探索更灵活的多动作机制,允许智能体选择不同类型的动作(例如,除了任务分配,还可以选择调整机器参数等)。
- 动态FJSP:
将该方法扩展到动态柔性车间调度问题,考虑机器故障、新订单插入、工件插队等突发事件。
- 多目标优化:
将多个调度目标(如Makespan、总流程时间、设备利用率、能耗等)纳入奖励函数,实现多目标协同优化。
- 可解释性:
提高深度强化学习模型的决策可解释性,帮助调度人员理解智能体的决策逻辑。
- 模型泛化能力:
研究如何提高训练模型的泛化能力,使其在未见过的FJSP实例上也能表现良好,减少模型重新训练的成本。
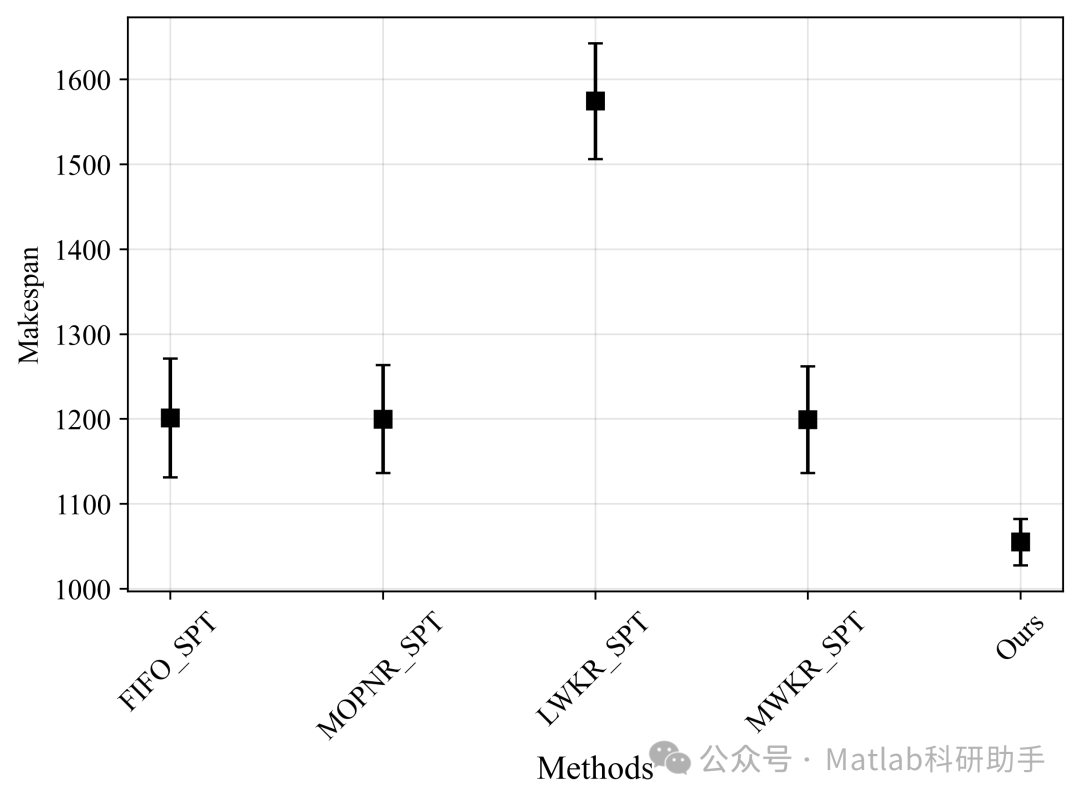
⛳️ 运行结果


🔗 参考文献
[1] 董昌智,车嵘,陈颖聪.基于多智能体强化学习的云任务调度算法优化与仿真[C]//第三十六届中国仿真大会论文集.2024.
[2] 高玉钊.基于值函数分解的多智能体深度强化学习围捕算法研究[D].军事科学院,2023.
[3] 王琦,杨毅远,江季.Easy RL:强化学习教程[M].人民邮电出版社,2022.
📣 部分代码
🎈 部分理论引用网络文献,若有侵权联系博主删除
👇 关注我领取海量matlab电子书和数学建模资料
🏆团队擅长辅导定制多种科研领域MATLAB仿真,助力科研梦:
🌈 各类智能优化算法改进及应用
生产调度、经济调度、装配线调度、充电优化、车间调度、发车优化、水库调度、三维装箱、物流选址、货位优化、公交排班优化、充电桩布局优化、车间布局优化、集装箱船配载优化、水泵组合优化、解医疗资源分配优化、设施布局优化、可视域基站和无人机选址优化、背包问题、 风电场布局、时隙分配优化、 最佳分布式发电单元分配、多阶段管道维修、 工厂-中心-需求点三级选址问题、 应急生活物质配送中心选址、 基站选址、 道路灯柱布置、 枢纽节点部署、 输电线路台风监测装置、 集装箱调度、 机组优化、 投资优化组合、云服务器组合优化、 天线线性阵列分布优化、CVRP问题、VRPPD问题、多中心VRP问题、多层网络的VRP问题、多中心多车型的VRP问题、 动态VRP问题、双层车辆路径规划(2E-VRP)、充电车辆路径规划(EVRP)、油电混合车辆路径规划、混合流水车间问题、 订单拆分调度问题、 公交车的调度排班优化问题、航班摆渡车辆调度问题、选址路径规划问题、港口调度、港口岸桥调度、停机位分配、机场航班调度、泄漏源定位
🌈 机器学习和深度学习时序、回归、分类、聚类和降维
2.1 bp时序、回归预测和分类
2.2 ENS声神经网络时序、回归预测和分类
2.3 SVM/CNN-SVM/LSSVM/RVM支持向量机系列时序、回归预测和分类
2.4 CNN|TCN|GCN卷积神经网络系列时序、回归预测和分类
2.5 ELM/KELM/RELM/DELM极限学习机系列时序、回归预测和分类
2.6 GRU/Bi-GRU/CNN-GRU/CNN-BiGRU门控神经网络时序、回归预测和分类
2.7 ELMAN递归神经网络时序、回归\预测和分类
2.8 LSTM/BiLSTM/CNN-LSTM/CNN-BiLSTM/长短记忆神经网络系列时序、回归预测和分类
2.9 RBF径向基神经网络时序、回归预测和分类
2.10 DBN深度置信网络时序、回归预测和分类
2.11 FNN模糊神经网络时序、回归预测
2.12 RF随机森林时序、回归预测和分类
2.13 BLS宽度学习时序、回归预测和分类
2.14 PNN脉冲神经网络分类
2.15 模糊小波神经网络预测和分类
2.16 时序、回归预测和分类
2.17 时序、回归预测预测和分类
2.18 XGBOOST集成学习时序、回归预测预测和分类
2.19 Transform各类组合时序、回归预测预测和分类
方向涵盖风电预测、光伏预测、电池寿命预测、辐射源识别、交通流预测、负荷预测、股价预测、PM2.5浓度预测、电池健康状态预测、用电量预测、水体光学参数反演、NLOS信号识别、地铁停车精准预测、变压器故障诊断
🌈图像处理方面
图像识别、图像分割、图像检测、图像隐藏、图像配准、图像拼接、图像融合、图像增强、图像压缩感知
🌈 路径规划方面
旅行商问题(TSP)、车辆路径问题(VRP、MVRP、CVRP、VRPTW等)、无人机三维路径规划、无人机协同、无人机编队、机器人路径规划、栅格地图路径规划、多式联运运输问题、 充电车辆路径规划(EVRP)、 双层车辆路径规划(2E-VRP)、 油电混合车辆路径规划、 船舶航迹规划、 全路径规划规划、 仓储巡逻
🌈 无人机应用方面
无人机路径规划、无人机控制、无人机编队、无人机协同、无人机任务分配、无人机安全通信轨迹在线优化、车辆协同无人机路径规划
🌈 通信方面
传感器部署优化、通信协议优化、路由优化、目标定位优化、Dv-Hop定位优化、Leach协议优化、WSN覆盖优化、组播优化、RSSI定位优化、水声通信、通信上传下载分配
🌈 信号处理方面
信号识别、信号加密、信号去噪、信号增强、雷达信号处理、信号水印嵌入提取、肌电信号、脑电信号、信号配时优化、心电信号、DOA估计、编码译码、变分模态分解、管道泄漏、滤波器、数字信号处理+传输+分析+去噪、数字信号调制、误码率、信号估计、DTMF、信号检测
🌈电力系统方面
微电网优化、无功优化、配电网重构、储能配置、有序充电、MPPT优化、家庭用电
🌈 元胞自动机方面
交通流 人群疏散 病毒扩散 晶体生长 金属腐蚀
🌈 雷达方面
卡尔曼滤波跟踪、航迹关联、航迹融合、SOC估计、阵列优化、NLOS识别
🌈 车间调度
零等待流水车间调度问题NWFSP 、 置换流水车间调度问题PFSP、 混合流水车间调度问题HFSP 、零空闲流水车间调度问题NIFSP、分布式置换流水车间调度问题 DPFSP、阻塞流水车间调度问题BFSP
👇

















 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









