



Scala第十章节
章节目标
- 掌握数组, 元组相关知识点
- 掌握列表, 集, 映射相关知识点
- 了解迭代器的用法
- 掌握函数式编程相关知识点
- 掌握学生成绩单案例
1. 数组
1.1 概述
数组就是用来存储多个同类型元素的容器, 每个元素都有编号(也叫: 下标, 脚标, 索引), 且编号都是从0开始数的. Scala中, 有两种数组,一种是定长数组,另一种是变长数组.
1.2 定长数组
1.2.1 特点
- 数组的长度不允许改变.
- 数组的内容是可变的.
1.2.2 语法
- 格式一: 通过指定长度定义数组
val/var 变量名 = new Array[元素类型](数组长度)
- 格式二: 通过指定元素定义数组
val/var 变量名 = Array(元素1, 元素2, 元素3...)
注意:
- 在scala中,数组的泛型使用 [] 来指定.
- 使用 数组名(索引) 来获取数组中的元素.
- 数组元素是有默认值的, Int:0, Double:0.0, String: null
- 通过 数组名.length 或者 数组名.size 来获取数组的长度.
1.2.3 示例
需求
- 定义一个长度为10的整型数组, 设置第1个元素为11, 并打印第1个元素.
- 定义一个包含"java", “scala”, "python"这三个元素的数组, 并打印数组长度.
参考代码
//案例: 演示定长数组
object ClassDemo01 {
def main(args: Array[String]): Unit = {
//1. 定义一个长度为10的整型数组, 设置第1个元素为11, 并打印第1个元素. val arr1 = new Array[Int](10)
arr1(0) = 11
println(arr1(0)) //打印数组的第1个元素.
println("-" * 15) //分割线
//2. 定义一个包含"java", "scala", "python"这三个元素的数组, 并打印数组长度. val arr2 = Array("java", "scala", "python")
println(arr2.length) //打印数组的长度
}
}
1.3 变长数组
1.3.1 特点
- 数组的长度和内容都是可变的,可以往数组中添加、删除元素.
1.3.2 语法
- 创建变长数组,需要先导入ArrayBuffer类.
import scala.collection.mutable.ArrayBuffer
- 定义格式一: 创建空的ArrayBuffer变长数组
val/var 变量名 = ArrayBuffer[元素类型]()
- 定义格式二: 创建带有初始元素的ArrayBuffer变长数组
val/var 变量名 = ArrayBuffer(元素1,元素2,元素3....)
1.3.3 示例一: 定义变长数组
- 定义一个长度为0的整型变长数组.
- 定义一个包含"hadoop", “storm”, "spark"这三个元素的变长数组.
- 打印结果.
参考代码
//1. 导包.
import scala.collection.mutable.ArrayBuffer
//案例: 演示变长数组
object ClassDemo02 {
def main(args: Array[String]): Unit = {
//2. 定义一个长度为0的整型变长数组.
val arr1 = new ArrayBuffer[Int]()
println("arr1:" + arr1)
//3. 定义一个包含"hadoop", "storm", "spark"这三个元素的变长数组.
val arr2 = ArrayBuffer("hadoop", "storm", "spark")
println("arr2:" + arr2)
}
}
1.3.4 示例二: 增删改元素
针对Scala中的变长数组, 可通过下述方式来修改数组中的内容.
格式
- 使用 += 添加单个元素
- 使用 -= 删除单个元素
- 使用 ++= 追加一个数组到变长数组中
- 使用 --= 移除变长数组中的指定多个元素
示例
- 定义一个变长数组,包含以下元素: “hadoop”, “spark”, “flink”
- 往该变长数组中添加一个"flume"元素
- 从该变长数组中删除"hadoop"元素
- 将一个包含"hive", "sqoop"元素的数组, 追加到变长数组中.
- 从该变长数组中删除"sqoop", "spark"这两个元素.
- 打印数组, 查看结果.
参考代码
//导包
import scala.collection.mutable.ArrayBuffer
//案例: 修改变长数组中的内容.
object ClassDemo03 {
def main(args: Array[String]): Unit = {
//1. 定义一个变长数组,包含以下元素: "hadoop", "spark", "flink"
val arr = ArrayBuffer("hadoop", "spark", "flink")
//2. 往该变长数组中添加一个"flume"元素
arr += "flume"
//3. 从该变长数组中删除"hadoop"元素
arr -= "hadoop"
//4. 将一个包含"hive", "sqoop"元素的数组, 追加到变长数组中.
arr ++= Array("hive", "sqoop")
//5. 从该变长数组中删除"sqoop", "spark"这两个元素.
arr --= Array("sqoop", "spark")
//6. 打印数组, 查看结果.
println(s"arr: ${arr}")
}
}
1.4 遍历数组
概述
在Scala中, 可以使用以下两种方式来遍历数组:
- 使用 索引 遍历数组中的元素
- 使用 for表达式 直接遍历数组中的元素
示例
- 定义一个数组,包含以下元素1,2,3,4,5
- 通过两种遍历方式遍历数组,并打印数组中的元素
参考代码
//案例: 遍历数组
object ClassDemo04 {
def main(args: Array[String]): Unit = {
//1. 定义一个数组,包含以下元素1,2,3,4,5
val arr = Array(1, 2, 3, 4, 5)
//2. 通过两种遍历方式遍历数组,并打印数组中的元素.
//方式一: 遍历索引的形式实现.
for(i <- 0 to arr.length -1)
println(arr(i))
println("-" * 15) //分割线
for(i <- 0 until arr.length) println(arr(i))
println("-" * 15) //分割线
//方式二: 直接遍历数组元素.
for(i <- arr) println(i)
}
}
注意:
0 until n 获取0~n之间的所有整数, 包含0, 不包含n.
0 to n 获取0~n之间的所有整数, 包含0, 也包含n.
1.5 数组常用算法
概述
Scala中的数组封装了一些常用的计算操作,将来在对数据处理的时候,不需要我们自己再重新实现, 而是可以直接 拿来用。以下为常用的几个算法:
- sum()方法: 求和
- max()方法: 求最大值
- min()方法: 求最小值
- sorted()方法: 排序, 返回一个新的数组.
- reverse()方法: 反转, 返回一个新的数组.
需求
- 定义一个数组, 包含4, 1, 6, 5, 2, 3这些元素.
- 在main方法中, 测试上述的常用算法.
参考代码
//案例: 数组的常用算法
object ClassDemo05 {
def main(args: Array[String]): Unit = {
//1. 定义一个数组, 包含4, 1, 6, 5, 2, 3这些元素.
val arr = Array(4, 1, 6, 5, 2, 3)
//2. 在main方法中, 测试上述的常用算法.
//测试sum
println(s"sum: ${arr.sum}")
//测试max
println(s"max: ${arr.max}")
//测试min
println(s"min: ${arr.min}")
//测试sorted
val arr2 = arr.sorted
//测试reverse
val arr3 = arr.sorted.reverse
//即: arr3的内容为: 6, 5, 4, 3, 2, 1
//3. 打印数组.
for(i <- arr) println(i)
println("-" * 15)
for(i <- arr2) println(i)
println("-" * 15)
for(i <- arr3) println(i)
}
}
2. 元组
元组一般用来存储多个不同类型的值。例如同时存储姓名,年龄,性别,出生年月这些数据, 就要用到元组来存储
了。并且元组的长度和元素都是不可变的。
2.1 格式
-
格式一: 通过小括号实现
val/var 元组 = (元素1, 元素2, 元素3....) -
格式二: 通过箭头来实现
val/var 元组 = 元素1->元素2注意: 上述这种方式, 只适用于元组中只有两个元素的情况.
2.2 示例
需求
- 定义一个元组,包含学生的姓名和年龄.
- 分别使用小括号以及箭头的方式来定义元组.
参考代码
//案例: 演示元组的定义格式
object ClassDemo06 {
def main(args: Array[String]): Unit = {
//1. 定义一个元组,包含学生的姓名和年龄.
//2. 分别使用小括号以及箭头的方式来定义元组.
val tuple1 = ("张三", 23)
val tuple2 = "张三" -> 23 println(tuple1)
println(tuple2)
}
}
2.3 访问元组中的元素
在Scala中, 可以通过 元组名._编号 的形式来访问元组中的元素,_1表示访问第一个元素,依次类推. 也可以通过 元组名.productIterator 的方式, 来获取该元组的迭代器, 从而实现遍历元组.
格式
-
格式一: 访问元组中的单个元组.
println(元组名._1) //打印元组的第二个元组. println(元组名._2) //打印元组的第二个元组. ... -
格式二: 遍历元组
val tuple1 = (1,2,3,4,5) //可以有多个值 val it = tuple1.productIterator //获取当前元组的迭代器对象 for(i <- it) println(i) //打印元组中的所有内容.
示例
- 定义一个元组,包含一个学生的姓名和性别,“zhangsan”, “male”
- 分别获取该学生的姓名和性别, 并将结果打印到控制台上.
参考代码
//案例: 获取元组中的元组.
object ClassDemo07 {
def main(args: Array[String]): Unit = {
//1. 定义一个元组,包含一个学生的姓名和性别,"zhangsan", "male"
val tuple1 = "zhangsan" -> "male"
//2. 分别获取该学生的姓名和性别
//方式一: 通过 _编号 的形式实现.
println(s"姓名: ${tuple1._1}, 性别: ${tuple1._2}")
//方式二: 通过迭代器遍历的方式实现.
//获取元组对应的迭代器对象.
val it = tuple1.productIterator
//遍历元组.
for(i <- it) println(i)
}
}
3.列表
列表(List)是Scala中最重要的, 也是最常用的一种数据结构。它存储的数据, 特点是: 有序, 可重复. 在Scala中,列表分为两种, 即: 不可变列表和可变列表.
解释:
- 有序 的意思并不是排序, 而是指 元素的存入顺序和取出顺序是一致的 .
- 可重复 的意思是 列表中可以添加重复元素
3.1 不可变列表
3.1.1 特点
不可变列表指的是: 列表的元素、长度都是不可变的。
3.1.2 语法
-
格式一: 通过 小括号 直接初始化.
val/var 变量名 = List(元素1, 元素2, 元素3...) -
格式二: 通过 Nil 创建一个空列表.
val/var 变量名 = Nil -
格式三: 使用 :: 方法实现.
val/var 变量名 = 元素1 :: 元素2 :: Nil
注意:
使用::拼接方式来创建列表,必须在最后添加一个Nil
3.2.2 示例
需求
- 创建一个不可变列表,存放以下几个元素(1,2,3,4)
- 使用 Nil 创建一个不可变的空列表
- 使用 :: 方法创建列表,包含-2、-1两个元素
参考代码
//案例: 演示不可变列表.
object ClassDemo08 {
def main(args: Array[String]): Unit = {
//1. 创建一个不可变列表,存放以下几个元素(1,2,3,4) val list1 = List(1, 2, 3, 4)
//2. 使用`Nil`创建一个不可变的空列表
val list2 = Nil
//3. 使用`::`方法创建列表,包含-2、-1两个元素
val list3 = -2 :: -1 :: Nil
//4. 打印结果.
println(s"list1: ${list1}")
println(s"list2: ${list2}")
println(s"list3: ${list3}")
}
}
3.2 可变列表
3.2.1 特点
可变列表指的是列表的元素、长度都是可变的.
3.2.2 语法
-
要使用可变列表, 必须先导包.
import scala.collection.mutable.ListBuffer小技巧: 可变集合都在 mutable 包中, 不可变集合都在 immutable 包中(默认导入).
-
格式一: 创建空的可变列表.
val/var 变量名 = ListBuffer[数据类型]() -
格式二: 通过 小括号 直接初始化.
val/var 变量名 = ListBuffer(元素1,元素2,元素3...)
3.2.3 示例
需求
- 创建空的整形可变列表.
- 创建一个可变列表,包含以下元素:1,2,3,4
参考代码
//1. 导包
import scala.collection.mutable.ListBuffer
//案例: 演示可变列表.
object ClassDemo09 {
def main(args: Array[String]): Unit = {
//2. 创建空的整形可变列表.
val list1 = new ListBuffer[Int]()
//3. 创建一个可变列表,包含以下元素:1,2,3,4 val
list2 = ListBuffer(1, 2, 3, 4)
println(s"list1: ${list1}")
println(s"list2: ${list2}")
}
}
3.2.4 可变列表的常用操作
关于可变列表的常见操作如下:
| 格式 | 功能 |
|---|---|
| 列表名(索引) | 根据索引(索引从0开始), 获取列表中的指定元素. |
| 列表名(索引) = 值 | 修改元素值 |
| += | 往列表中添加单个元素 |
| ++= | 往列表中追加一个列表 |
| -= | 删除列表中的某个指定元素 |
| - - = | 以列表的形式, 删除列表中的多个元素. |
| toList | 将可变列表(ListBuffer)转换为不可变列表(List) |
| toArray | 将可变列表(ListBuffer)转换为数组 |
示例
- 定义一个可变列表包含以下元素:1,2,3
- 获取第一个元素, 并打印结果到控制台.
- 添加一个新的元素:4
- 追加一个列表,该列表包含以下元素:5,6,7
- 删除元素7
- 删除元素3, 4
- 将可变列表转换为不可变列表
- 将可变列表转换为数组
- 打印结果.
参考代码
//案例: 演示可变列表的常见操作.
object ClassDemo10 {
def main(args: Array[String]): Unit = {
//1. 定义一个可变列表包含以下元素:1,2,3
val list1 = ListBuffer(1, 2, 3)
//2. 获取第一个元素, 并打印结果到控制台.
println(list1(0))
//3. 添加一个新的元素:4
list1 += 4
//4. 追加一个列表,该列表包含以下元素:5,6,7
list1 ++= List(5, 6, 7)
//5. 删除元素7
list1 -= 7
//6. 删除元素3, 4
list1 --= List(3, 4)
//7. 将可变列表转换为不可变列表
val list2 = list1.toList
//8. 将可变列表转换为数组
val arr = list1.toArray
//9. 打印结果.
println(s"list1: ${list1}")
println(s"list2: ${list2}")
println(s"arr: ${arr}")
}
}
3.3 列表的常用操作
3.3.1 格式详解
在实际开发中, 我们经常要操作列表, 以下列举的是列表的常用的操作:
| 格式 | 功能 |
|---|---|
| isEmpty | 判断列表是否为空 |
| ++ | 拼接两个列表, 返回一个新的列表 |
| head | 获取列表的首个元素 |
| tail | 获取列表中除首个元素之外, 其他所有的元素 |
| reverse | 对列表进行反转, 返回一个新的列表 |
| take | 获取列表中的前缀元素(具体个数可以自定义) |
| drop | 获取列表中的后缀元素(具体个数可以自定义) |
| flatten | 对列表进行扁平化操作, 返回一个新的列表 |
| zip | 对列表进行拉链操作, 即: 将两个列表合并成一个列表 |
| unzip | 对列表进行拉开操作, 即: 将一个列表拆解成两个列表 |
| toString | 将列表转换成其对应的默认字符串形式 |
| mkString | 将列表转换成其对应的指定字符串形式 |
| union | 获取两个列表的并集元素, 并返回一个新的列表 |
| intersect | 获取两个列表的交集元素, 并返回一个新的列表 |
| diff | 获取两个列表的差集元素, 并返回一个新的列表 |
3.3.2 示例一: 基础操作
需求
- 定义一个列表list1,包含以下元素:1,2,3,4
- 使用isEmpty方法判断列表是否为空, 并打印结果.
- 再定义一个列表list2,包含以下元素: 4,5,6
- 使用 ++ 将两个列表拼接起来, 并打印结果.
- 使用head方法,获取列表的首个元素, 并打印结果.
- 使用tail方法,获取列表中除首个元素之外, 其他所有的元素, 并打印结果.
- 使用reverse方法将列表的元素反转, 并打印反转后的结果.
- 使用take方法获取列表的前缀元素, 并打印结果.
- 使用drop方法获取列表的后缀元素, 并打印结果.
参考代码
//案例: 演示列表的基础操作.
object ClassDemo11 {
def main(args: Array[String]): Unit = {
//1. 定义一个列表list1,包含以下元素:1,2,3,4
val list1 = List(1, 2, 3, 4)
//2. 使用isEmpty方法判断列表是否为空, 并打印结果.
println(s"isEmpty: ${list1.isEmpty}")
//3. 再定义一个列表list2,包含以下元素: 4,5,6 val
list2 = List(4, 5, 6)
//4. 使用`++`将两个列表拼接起来, 并打印结果.
val list3 = list1 ++ list2 println(s"list3: ${list3}")
//5. 使用head方法,获取列表的首个元素, 并打印结果.
println(s"head: ${list3.head}")
//6. 使用tail方法,获取列表中除首个元素之外, 其他所有的元素, 并打印结果.
println(s"tail: ${list3.tail}")
//7. 使用reverse方法将列表的元素反转, 并打印反转后的结果.
val list4 = list3.reverse
println(s"list4: ${list4}")
//8. 使用take方法获取列表的前缀元素(前三个元素), 并打印结果.
println(s"take: ${list3.take(3)}")
//9. 使用drop方法获取列表的后缀元素(除前三个以外的元素), 并打印结果.
println(s"drop: ${list3.drop(3)}")
}
}
3.3.3 示例二: 扁平化(压平)
概述
扁平化表示将嵌套列表中的所有具体元素单独的放到一个新列表中. 如下图:
>注意: 如果某个列表中的所有元素都是列表, 那么这样的列表就称之为: 嵌套列表.

需求
- 定义一个列表, 该列表有三个元素, 分别为:List(1,2)、List(3)、List(4,5)
- 使用flatten将这个列表转换为List(1,2,3,4,5)
- 打印结果.
参考代码
//案例: 演示扁平化操作.
object ClassDemo12 {
def main(args: Array[String]): Unit = {
//1. 定义一个列表, 该列表有三个元素, 分别为:List(1,2)、List(3)、List(4,5)
val list1 = List(List(1,2), List(3), List(4, 5))
//2. 使用flatten将这个列表转换为List(1,2,3,4,5)
val list2 = list1.flatten
//3. 打印结果
println(list2)
}
}
3.3.4 示例三: 拉链与拉开
概述
-
拉链:将两个列表,组合成一个元素为元组的列表
解释: 将列表List(“张三”, “李四”), List(23, 24)组合成列表List((张三,23), (李四,24))
-
拉开:将一个包含元组的列表,拆解成包含两个列表的元组
解释: 将列表List((张三,23), (李四,24))拆解成元组(List(张三, 李四),List(23, 24))
需求
- 定义列表names, 保存三个学生的姓名,分别为:张三、李四、王五
- 定义列表ages, 保存三个学生的年龄,分别为:23, 24, 25
- 使用zip将列表names和ages, 组合成一个元素为元组的列表list1
- 使用unzip将列表list1拆解成包含两个列表的元组tuple1
- 打印结果
参考代码
//案例: 演示拉链与拉开
object ClassDemo13 {
def main(args: Array[String]): Unit = {
//1. 定义列表names, 保存三个学生的姓名,分别为:张三、李四、王五
val names = List("张三", "李四", "王五")
//2. 定义列表ages, 保存三个学生的年龄,分别为:23, 24, 25
val ages = List(23, 24, 25)
//3. 使用zip将列表names和ages, 组合成一个元素为元组的列表list1.
val list1 = names.zip(ages)
//4. 使用unzip将列表list1拆解成包含两个列表的元组tuple1
val tuple1 = list1.unzip
//5. 打印结果
println("拉链: "+ list1)
println("拉开: " + tuple1)
}
}
3.3.5 示例四: 列表转字符串
概述
将列表转换成其对应的字符串形式, 可以通过 toString方法或者mkString方法 实现, 其中
- toString方法: 可以返回List中的所有元素
- mkString方法: 可以将元素以指定分隔符拼接起来。
注意: 默认没有分隔符.
需求
- 定义一个列表,包含元素:1,2,3,4
- 使用toString方法输出该列表的元素
- 使用mkString方法, 用冒号将元素都拼接起来, 并打印结果.
参考代码
//案例: 演示将列表转成其对应的字符串形式.
object ClassDemo14 {
def main(args: Array[String]): Unit = {
//1. 定义一个列表,包含元素:1,2,3,4
val list1 = List(1, 2, 3, 4)
//2. 使用toString方法输出该列表的元素
println(list1.toString)
//简写形式, 因为: 输出语句打印对象, 默认调用了该对象的toString()方法
println(list1)
println("-" * 15)
//3. 使用mkString方法, 用冒号将元素都拼接起来, 并打印结果.
println(list1.mkString(":"))
}
}
3.3.6 示例五: 并集, 交集, 差集
概述 操作数据时, 我们可能会遇到求并集, 交集, 差集的需求, 这是时候就要用到union, intersect, diff这些方法了, 其
中
-
union: 表示对两个列表取并集,而且不去重
例如: list1.union(list2), 表示获取list1和list2中所有的元素(元素不去重). 如果想要去除重复元素, 则可以通过 distinct 实现.
-
intersect: 表示对两个列表取交集
例如: list1.intersect(list2), 表示获取list1, list2中都有的元素.
-
diff: 表示对两个列表取差集.
例如:list1.diff(list2),表示获取list1中有, 但是list2中没有的元素.
需求
- 定义列表list1,包含以下元素:1,2,3,4
- 定义列表list2,包含以下元素:3,4,5,6
- 使用union获取这两个列表的并集
- 在第三步的基础上, 使用distinct去除重复的元素
- 使用intersect获取列表list1和list2的交集
- 使用diff获取列表list1和list2的差集
- 打印结果
参考代码
//案例: 演示获取并集, 交集, 差集.
object ClassDemo15 {
def main(args: Array[String]): Unit = {
//1. 定义列表list1,包含以下元素:1,2,3,4
val list1 = List(1, 2, 3, 4)
//2. 定义列表list2,包含以下元素:3,4,5,6
val list2 = List(3, 4, 5, 6)
//3. 使用union获取这两个列表的并集
val unionList = list1.union(list2)
//4. 在第三步的基础上, 使用distinct去除重复的元素
val distinctList = unionList distinct
//5. 使用intersect获取列表list1和list2的交集
val intersectList = list1.intersect(list2)
//6. 使用diff获取列表list1和list2的差集
val diffList = list1.diff(list2)
//7. 打印结果
println("并集, 不去重: " + unionList)
println("并集, 去重: " + distinctList)
println("交集: " + intersectList)
println("差集: " + diffList)
}
}
4.集
4.1 概述
Set(也叫: 集)代表没有重复元素的集合。特点是: 唯一, 无序
Scala中的集分为两种,一种是不可变集,另一种是可变集。
解释:
1. 唯一 的意思是 Set中的元素具有唯一性, 没有重复元素
2. 无序 的意思是 Set集中的元素, 添加顺序和取出顺序不一致
4.2 不可变集
不可变集指的是元素, 集的长度都不可变.
4.2.1 语法
-
格式一: 创建一个空的不可变集
val/var 变量名 = Set[类型]() -
格式二: 给定元素来创建一个不可变集
val/var 变量名 = Set(元素1, 元素2, 元素3...)
4.2.2 示例一: 创建不可变集 需求
- 定义一个空的整型不可变集.
- 定义一个不可变集,保存以下元素:1,1,3,2,4,8.
- 打印结果.
参考代码
//案例: 演示不可变集.
object ClassDemo16 {
def main(args: Array[String]): Unit = {
//1. 定义一个空的整型不可变集.
val set1 = Set[Int]()
//2. 定义一个不可变集,保存以下元素:1,1,3,2,4,8. val
set2 = Set(1, 1, 3, 2, 4, 8)
//3. 打印结果.
println(s"set1: ${set1}")
println(s"set2: ${set2}")
}
}
4.2.3 示例二: 不可变集的常见操作
格式
- 获取集的大小( size )
- 遍历集( 和遍历数组一致 )
- 添加一个元素,生成一个新的Set( + )
- 拼接两个集,生成一个新的Set( ++ )
- 拼接集和列表,生成一个新的Set( ++ )
注意:
1. -(减号) 表示删除一个元素, 生成一个新的Set
2. – 表示批量删除某个集中的元素, 从而生成一个新的Set
需求
- 创建一个集,包含以下元素:1,1,2,3,4,5
- 获取集的大小, 并打印结果.
- 遍历集,打印每个元素.
- 删除元素1,生成新的集, 并打印.
- 拼接另一个集Set(6, 7, 8), 生成新的集, 并打印.
- 拼接一个列表List(6,7,8, 9), 生成新的集, 并打印.
参考代码
//案例: 演示不可变集的常用操作.
object ClassDemo17 {
def main(args: Array[String]): Unit = {
//1. 创建一个集,包含以下元素:1,1,2,3,4,5
val set1 = Set(1, 1, 2, 3, 4, 5)
//2. 获取集的大小
println("set1的长度为: " + set1.size)
//3. 遍历集,打印每个元素 println("set1集中的元素为: ")
for(i <- set1) println(i)
println("-" * 15)
//4. 删除元素1,生成新的集
val set2 = set1 - 1
println("set2: " + set2)
//5. 拼接另一个集(6, 7, 8)
val set3 = set1 ++ Set(6, 7, 8)
println("set3: " + set3)
//6. 拼接一个列表(6,7,8, 9)
val set4 = set1 ++ List(6, 7, 8, 9)
println("set4: " + set4)
}
}
4.3 可变集
4.3.1 概述
可变集指的是元素, 集的长度都可变, 它的创建方式和不可变集的创建方式一致,只不过需要先导入可变集类。
手动导入:
import scala.collection.mutable.Set
4.3.2 示例 需求
- 定义一个可变集,包含以下元素: 1,2,3, 4
- 添加元素5到可变集中
- 添加元素6, 7, 8到可变集中
- 从可变集中移除元素1
- 从可变集中移除元素3, 5, 7
- 打印结果.
参考代码
//案例: 演示可变集.
object ClassDemo18 {
def main(args: Array[String]): Unit = {
//1. 定义一个可变集,包含以下元素: 1,2,3, 4
val set1 = Set(1, 2, 3, 4)
//2. 添加元素5到可变集中
set1 += 5
//3. 添加元素6, 7, 8到可变集中
//set1 ++= Set(6, 7, 8) //两种写法均可.
set1 ++= List(6, 7, 8)
//4. 从可变集中移除元素1
set1 -= 1
//5. 从可变集中移除元素3, 5, 7
//set1 --= Set(3, 5, 7) //两种写法均可.
set1 --= List(3, 5, 7)
//6. 打印结果.
println(set1)
}
}
5. 映射
映射指的就是Map。它是由键值对(key, value)组成的集合。特点是: 键具有唯一性, 但是值可以重复. 在Scala中,Map也分为不可变Map和可变Map。
注意: 如果添加重复元素(即: 两组元素的键相同), 则 会用新值覆盖旧值 .
5.1 不可变Map
不可变Map指的是元素, 长度都不可变.
语法
-
方式一: 通过 箭头 的方式实现.
val/var map = Map(键->值, 键->值, 键->值...) // 推荐,可读性更好 -
方式二: 通过 小括号 的方式实现.
val/var map = Map((键, 值), (键, 值), (键, 值), (键, 值)...)
需求
- 定义一个映射,包含以下学生姓名和年龄数据: 张三 -> 23, 李四 -> 24, 李四 -> 40
- 打印结果.
参考代码
//案例: 演示不可变Map
object ClassDemo19 {
def main(args: Array[String]): Unit = {
//1. 定义一个映射,包含以下学生姓名和年龄数据.
val map1 = Map("张三" -> 23, "李四" -> 24, "李四" -> 40)
val map2 = Map(("张三", 23),("李四", 24), ("李四" -> 40))
//2. 打印结果.
println(s"map1: ${map1}")
println(s"map2: ${map2}")
}
}
5.2 可变Map
特点
可变Map指的是元素, 长度都可变. 定义语法与不可变Map一致, 只不过需要先手动导包:
import scala.collection.mutable.Map
需求
- 定义一个映射,包含以下学生姓名和年龄数据: 张三 -> 23, 李四 -> 24
- 修改张三的年龄为30
- 打印结果
参考代码
import scala.collection.mutable.Map
//案例: 演示可变Map.
object ClassDemo20 {
def main(args: Array[String]): Unit = {
//1. 定义一个映射,包含以下学生姓名和年龄数据.
val map1 = Map("张三" -> 23, "李四" -> 24)
val map2 = Map(("张三", 23),("李四", 24))
//2. 修改张三的年龄为30
map1("张三") = 30
//3. 打印结果
println(s"map1: ${map1}")
println(s"map2: ${map2}")
}
}
5.3 Map基本操作
格式
1. map(key) : 根据键获取其对应的值, 键不存在返回None.
2. map.keys : 获取所有的键.
3. map.values : 获取所有的值.
4. 遍历map集合: 可以通过普通for实现.
5. getOrElse: 根据键获取其对应的值, 如果键不存在, 则返回指定的默认值.
6. +号 : 增加键值对, 并生成一个新的Map.
>注意: 如果是可变Map, 则可以通过 +=或者++= 直接往该可变Map中添加键值对元素.
7. -号 : 根据键删除其对应的键值对元素, 并生成一个新的Map.
>注意: 如果是可变Map, 则可以通过 -=或者--= 直接从该可变Map中删除键值对元素.
示例
- 定义一个映射,包含以下学生姓名和年龄数据: 张三 -> 23, 李四 -> 24
- 获取张三的年龄, 并打印.
- 获取所有的学生姓名, 并打印.
- 获取所有的学生年龄, 并打印.
- 打印所有的学生姓名和年龄.
- 获取 王五 的年龄,如果 王五 不存在,则返回-1, 并打印.
- 新增一个学生:王五, 25, 并打印结果.
- 将 李四 从可变映射中移除, 并打印.
参考代码
import scala.collection.mutable.Map
//案例: 演示Map的常见操作.
object ClassDemo21 {
def main(args: Array[String]): Unit = {
//1. 定义一个映射,包含以下学生姓名和年龄数据: 张三 -> 23, 李四 -> 24
val map1 = Map("张三" -> 23, "李四" -> 24)
//2. 获取张三的年龄, 并打印.
println(map1.get("张三"))
//3. 获取所有的学生姓名, 并打印.
println(map1.keys)
//4. 获取所有的学生年龄, 并打印.
println(map1.values)
//5. 打印所有的学生姓名和年龄.
for((k, v) <- map1) println(s"键:${k}, 值:${v}")
println("-" * 15)
//6. 获取`王五`的年龄,如果`王五`不存在,则返回-1, 并打印.
println(map1.getOrElse("王五", -1))
println("-" * 15)
//7. 新增一个学生:王五, 25, 并打印结果.
/*//不可变Map
val map2 = map1 + ("王五" -> 25)
println(s"map1: ${map1}")
println(s"map2: ${map2}")*/
map1 += ("王五" -> 25)
//8. 将`李四`从可变映射中移除, 并打印.
map1 -= "李四"
println(s"map1: ${map1}")
}
}
6. 迭代器(iterator)
6.1 概述
Scala针对每一类集合都提供了一个迭代器(iterator), 用来迭代访问集合.
6.2 注意事项
- 使用 iterator 方法可以从集合获取一个迭代器.
迭代器中有两个方法:
- hasNext方法: 查询容器中是否有下一个元素
- next方法: 返回迭代器的下一个元素,如果没有,抛出NoSuchElementException - 每一个迭代器都是有状态的.
即: 迭代完后保留在最后一个元素的位置. 再次使用则抛出NoSuchElementException
- 可以使用while或者for来逐个获取元素.
6.3 示例
需求
- 定义一个列表,包含以下元素:1,2,3,4,5
- 使用while循环和迭代器,遍历打印该列表.
参考代码
//案例: 演示迭代器
object ClassDemo22 {
def main(args: Array[String]): Unit = {
//1. 定义一个列表,包含以下元素:1,2,3,4,5
val list1 = List(1, 2, 3, 4, 5)
//2. 使用while循环和迭代器,遍历打印该列表.
//2.1 根据列表获取其对应的迭代器对象.
val it = list1.iterator
//2.2 判断迭代器中是否有下一个元素.
while(it.hasNext){
//2.3 如果有, 则获取下一个元素, 并打印.
println(it.next)
}
//分割线.
println("-" * 15)
//迭代完后, 再次使用该迭代器获取元素, 则抛异常: NoSuchElementException
println(it.next)
}
}
7. 函数式编程
- 所谓的函数式编程指定就是 方法的参数列表可以接收函数对象 .
- 例如: add(10, 20)就不是函数式编程, 而 add(函数对象) 这种格式就叫函数式编程.
- 我们将来编写Spark/Flink的大量业务代码时, 都会使用到函数式编程。下面的这些操作是学习的重点。
| 函数名 | 功能 |
|---|---|
| foreach | 用来遍历集合的 |
| map | 用来对集合进行转换的 |
| flatmap | 用来对集合进行映射扁平化操作 |
| filter | 用来过滤出指定的元素 |
| sorted | 用来对集合元素进行默认排序 |
| sortBy | 用来对集合按照指定字段排序 |
| sortWith | 用来对集合进行自定义排序 |
| groupBy | 用来对集合元素按照指定条件分组 |
| reduce | 用来对集合元素进行聚合计算 |
| fold | 用来对集合元素进行折叠计算 |
####7.1 示例一: 遍历(foreach)
采用 foreach 来遍历集合, 可以让代码看起来更简洁, 更优雅.
格式
def foreach(f:(A) => Unit): Unit
//简写形式
def foreach(函数)
说明
| foreach | API | 说明 |
|---|---|---|
| 参数 | f: (A) ⇒ Unit | 接收一个函数对象, 函数的参数为集合的元素,返回值为空 |
| 返回值 | Unit | 表示foreach函数的返回值为: 空 |
执行过程

需求
有一个列表,包含以下元素1,2,3,4,请使用foreach方法遍历打印每个元素
参考代码
//案例: 演示foreach函数
object ClassDemo23 {
def main(args: Array[String]): Unit = {
//1. 定义一个列表, 包含1, 2, 3, 4
val list1 = List(1, 2, 3, 4)
//2. 通过foreach函数遍历上述的列表.
//x:表示集合中的每个元素 函数体表示输出集合中的每个元素.
list1.foreach((x:Int) =>println(x))
}
}
7.2 示例二: 简化函数定义
概述
上述案例函数定义有点啰嗦,我们有更简洁的写法。可以通过如下两种方式来简化函数定义:
- 方式一: 通过 类型推断 来简化函数定义.
解释:
因为使用foreach来迭代列表,而列表中的每个元素类型是确定的, 所以我们可以通过 类型推断 让Scala 程序来自动推断出来集合中每个元素参数的类型, 即: 在我们创建函数时,可以省略其参数列表的类型. - 方式二: 通过 下划线 来简化函数定义.
解释:
当函数参数,只在函数体中出现一次,而且函数体没有嵌套调用时,可以使用下划线来简化函数定义.
示例
- 有一个列表,包含元素1,2,3,4,请使用foreach方法遍历打印每个元素.
- 使用类型推断来简化函数定义.
- 使用下划线来简化函数定义
参考代码
//案例: 演示简化函数定义. object ClassDemo24 {
def main(args: Array[String]): Unit = {
//1. 有一个列表,包含元素1,2,3,4,请使用foreach方法遍历打印每个元素.
val list1 = List(1, 2, 3, 4)
list1.foreach((x:Int) => println(x))
println("-" * 15)
//2. 使用类型推断来简化函数定义.
list1.foreach(x => println(x))
println("-" * 15)
//3. 使用下划线来简化函数定义
list1.foreach(println(_))
}
}
7.3 实例三: 映射(map)
集合的映射操作是指 将一种数据类型转换为另外一种数据类型的过程
Spark/Flink程序时用得最多的操作,也是我们必须要掌握的.
例如: 把List[Int]转换成List[String].
格式
def map[B](f: (A) ⇒ B): TraversableOnce[B]
//简写形式:
def map(函数对象)
说明
| map方法 | API | 说明 |
|---|---|---|
| 泛型 | [B] | 指定map方法最终返回的集合泛型, 可省略不写. |
| 参数 | f: (A) ⇒ B | 函数对象, 参数列表为类型A(要转换的列表元素),返回值为类型B |
| 返回值 | TraversableOnce[B] | B类型的集合, 可省略不写. |
执行过程
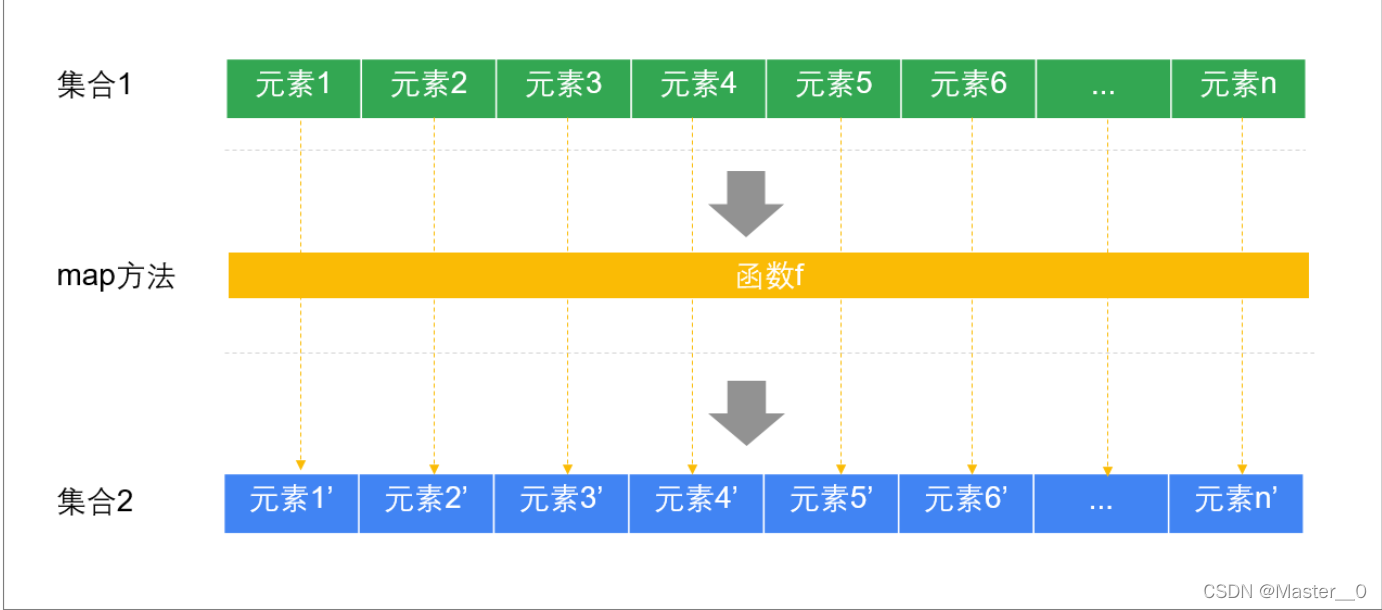
需求
- 创建一个列表,包含元素1,2,3,4
- 将上述的数字转换成对应个数的 * , 即: 1变为*, 2变为**, 以此类推.
参考代码
//案例: 演示map函数(映射)
object ClassDemo25 {
def main(args: Array[String]): Unit = {
//1. 创建一个列表,包含元素1,2,3,4
val list1 = List(1, 2, 3, 4)
//2. 将上述的数字转换成对应个数的`*`, 即: 1变为*, 2变为**, 以此类推. //方式一: 普通写法
val list2 = list1.map((x:Int) => "*" * x)
println(s"list2: ${list2}")
//方式二: 通过类型推断实现.
val list3 = list1.map(x => "*" * x)
println(s"list3: ${list3}")
//方式三: 通过下划线实现.
val list4 = list1.map("*" * _)
println(s"list4: ${list4}")
}
}
7.4 示例四: 扁平化映射(flatMap)
扁平化映射可以理解为先map,然后再flatten, 它也是将来用得非常多的操作,也是必须要掌握的, 如图:
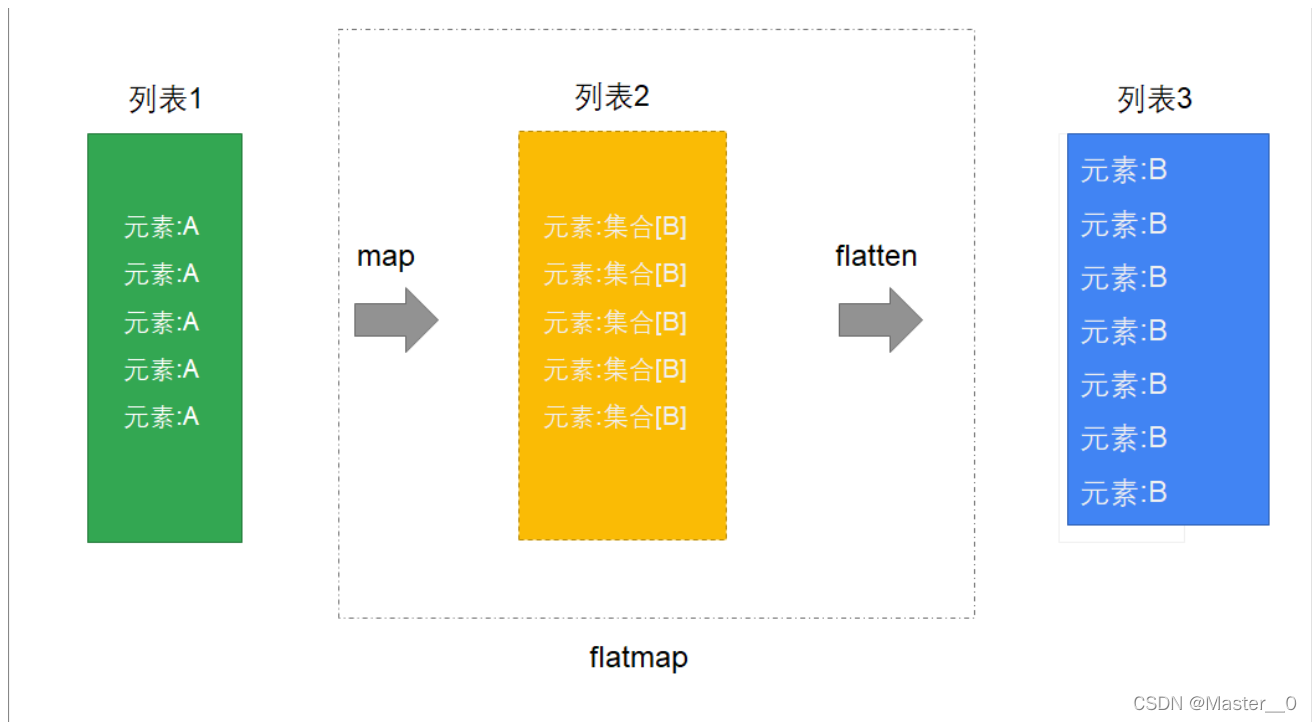
解释:
1. map是将列表中的元素转换为一个List
2. flatten再将整个列表进行扁平化
格式
def flatMap[B](f:(A) => GenTraversableOnce[B]): TraversableOnce[B]
//简写形式:
def flatMap(f:(A) => 要将元素A转换成的集合B的列表)
说明
| flatmap方法 | API | 说明 |
|---|---|---|
| 泛型 | [B] | 最终要返回的集合元素类型, 可省略不写. |
| 参数 | f: (A) ⇒ GenTraversableOnce[B] | 传入一个函数对象 函数的参数是集合的元素 函数的返回值是一个集合 |
| 返回值 | TraversableOnce[B] | B类型的集合 |
示例
需求
- 有一个包含了若干个文本行的列表:“hadoop hive spark flink flume”, “kudu hbase sqoop storm”
- 获取到文本行中的每一个单词,并将每一个单词都放到列表中.
思路分析
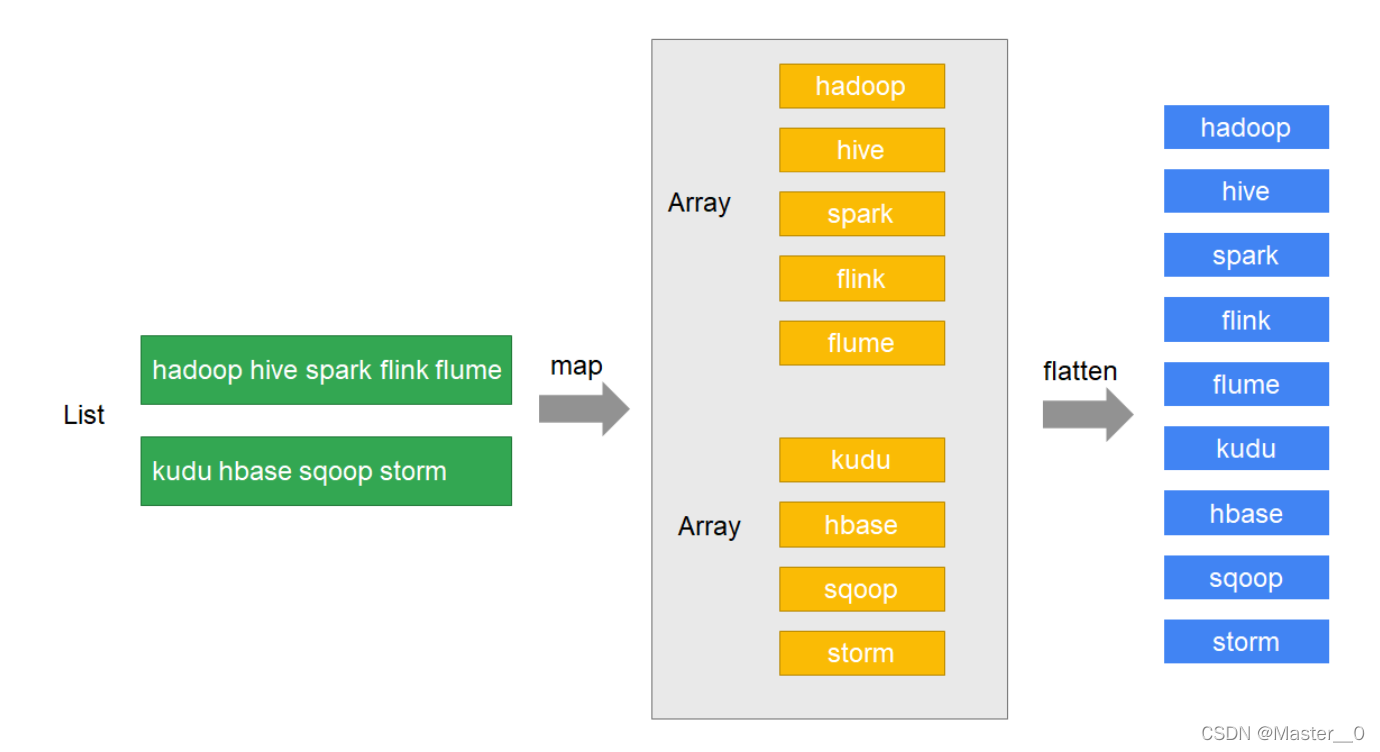
参考代码
//案例: 演示映射扁平化(flatMap)
object ClassDemo26 {
def main(args: Array[String]): Unit = {
//1. 有一个包含了若干个文本行的列表:"hadoop hive spark flink flume", "kudu hbase sqoop storm"
val list1 = List("hadoop hive spark flink flume", "kudu hbase sqoop storm") //2. 获取到文本行中的每一个单词,并将每一个单词都放到列表中.
//方式一: 通过map, flatten实现.
val list2 = list1.map(_.split(" "))
val list3 = list2.flatten
println(s"list3: ${list3}")
//方式二: 通过flatMap实现.
val list4 = list1.flatMap(_.split(" "))
println(s"list4: ${list4}")
}
}
7.5 示例五: 过滤(filter)
过滤指的是 过滤出(筛选出)符合一定条件的元素 .
格式
def filter(f:(A) => Boolean): TraversableOnce[A]
//简写形式:
def filter(f:(A) => 筛选条件)
说明
| filter方法 | API | 说明 |
|---|---|---|
| 参数 | f: (A) ⇒ Boolean | 传入一个函数对象 接收一个集合类型的参数 返回布尔类型,满足条件返回true, 不满足返回false |
| 返回值 | TraversableOnce[A] | 符合条件的元素列表 |
执行过程
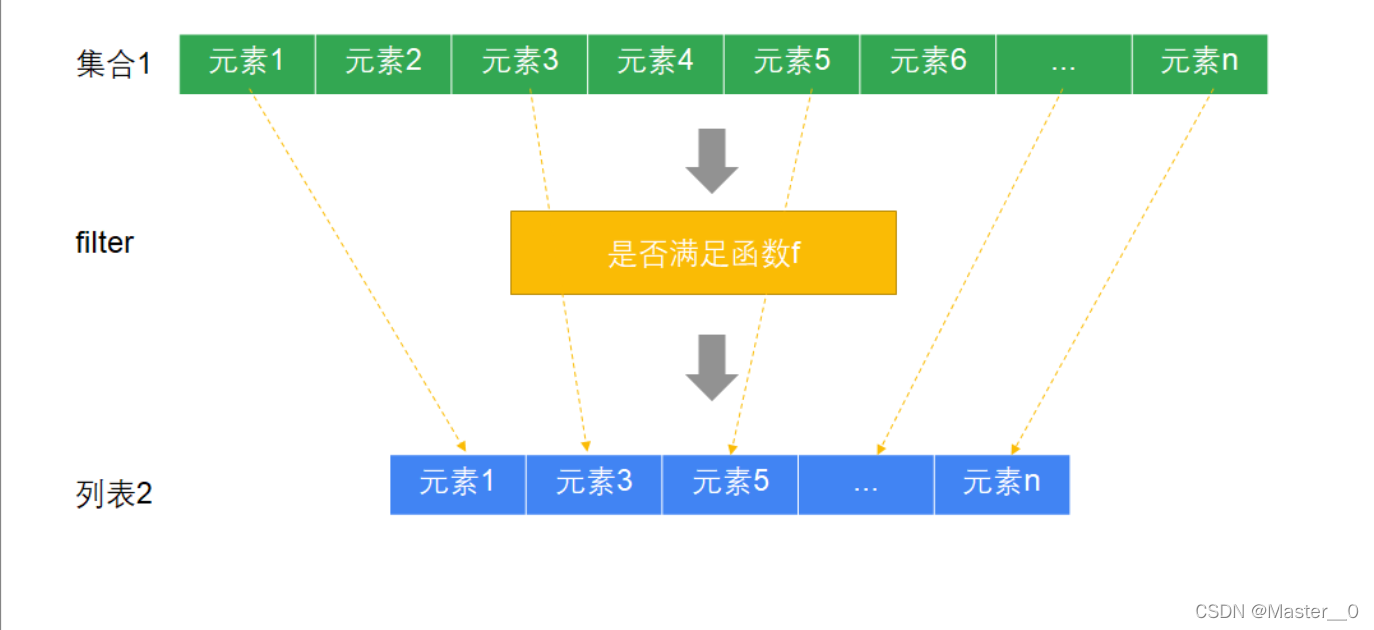
案例
- 有一个数字列表,元素为:1,2,3,4,5,6,7,8,9
- 请过滤出所有的偶数
参考代码
//案例: 演示过滤(filter)
object ClassDemo27 {
def main(args: Array[String]): Unit = {
//1. 有一个数字列表,元素为:1,2,3,4,5,6,7,8,9
val list1 = (1 to 9).toList
//2. 请过滤出所有的偶数
val list2 = list1.filter(_ % 2 == 0)
println(s"list2: ${list2}")
}
}
7.6 示例六: 排序
在scala集合中,可以使用以下三种方式来进行排序:
| 函数名 | 功能 |
|---|---|
| sorted | 用来对集合元素进行默认排序 |
| sortBy | 用来对集合按照指定字段排序 |
| sortWith | 用来对集合进行自定义排序 |
7.6.1 默认排序(sorted)
所谓的默认排序指的是 对列表元素按照升序进行排列 . 如果需要降序排列, 则升序后, 再通过 reverse 实现.
需求
- 定义一个列表,包含以下元素: 3, 1, 2, 9, 7 2. 对列表进行升序排序
- 对列表进行降序排列.
参考代码
//案例: 演示默认排序(sorted)
object ClassDemo28 {
def main(args: Array[String]): Unit = {
//1. 定义一个列表,包含以下元素: 3, 1, 2, 9, 7
val list1 = List(3, 1, 2, 9, 7)
//2. 对列表进行升序排序
val list2 = list1.sorted
println(s"list2: ${list2}")
//3. 对列表进行降序排列.
val list3 = list2.reverse
println(s"list3: ${list3}")
}
}
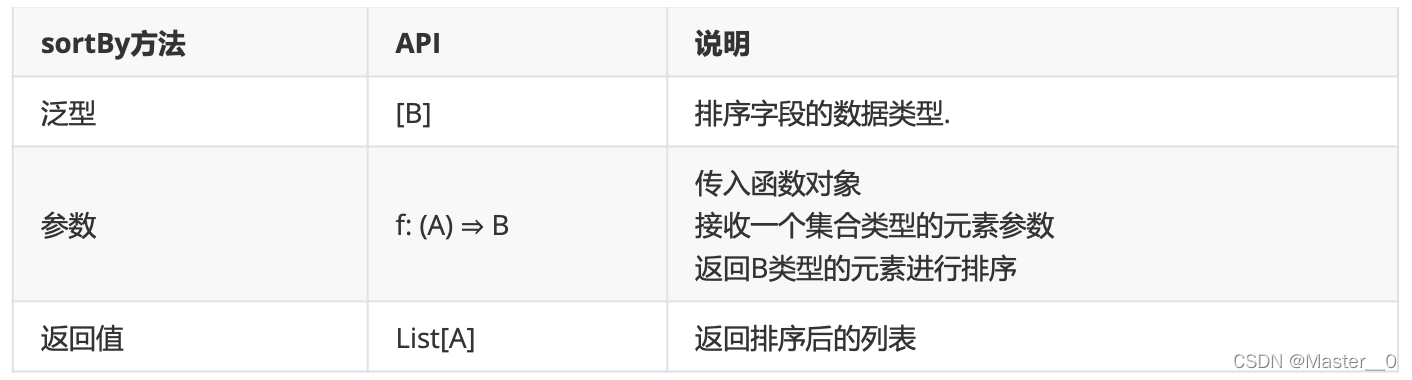
7.6.2 指定字段排序(sortBy)
所谓的指定字段排序是指 对列表元素根据传入的函数转换后,再进行排序 .
例如: 根据列表List(“01 hadoop”, “02 flume”)的 字母进行排序.
格式
def sortBy[B](f:(A) => B): List[A]
//简写形式:
def sortBy(函数对象)
说明
示例
- 有一个列表,分别包含几下文本行:“01 hadoop”, “02 flume”, “03 hive”, “04 spark”
- 请按照单词字母进行排序
参考代码
//案例: 演示根据指定字段排序(sortBy)
object ClassDemo29 {
def main(args: Array[String]): Unit = {
//1. 有一个列表,分别包含几下文本行:"01 hadoop", "02 flume", "03 hive", "04 spark"
val list1 = List("01 hadoop", "02 flume", "03 hive", "04 spark")
//2. 请按照单词字母进行排序
//val list2 = list1.sortBy(x => x.split(" ")(1))
//简写形式:
val list2 = list1.sortBy(_.split(" ")(1))
println(s"list2: ${list2}")
}
}
7.6.3 自定义排序(sortWith)
所谓的自定义排序指的是 根据一个自定义的函数(规则)来进行排序 .
格式
def sortWith(f: (A, A) => Boolean): List[A]
//简写形式:
def sortWith(函数对象: 表示自定义的比较规则)
说明

示例
- 有一个列表,包含以下元素:2,3,1,6,4,5
- 使用sortWith对列表进行降序排序
参考代码
//案例: 演示自定义排序(sortWith)
object ClassDemo30 {
def main(args: Array[String]): Unit = {
//1. 有一个列表,包含以下元素:2,3,1,6,4,5
val list1 = List(2,3,1,6,4,5)
//2. 使用sortWith对列表进行降序排序
//val list2 = list1.sortWith((x, y)=> x > y) //降序
//简写形式:
val list2 = list1.sortWith(_ > _) //降序
println(s"list2: ${list2}")
}
}
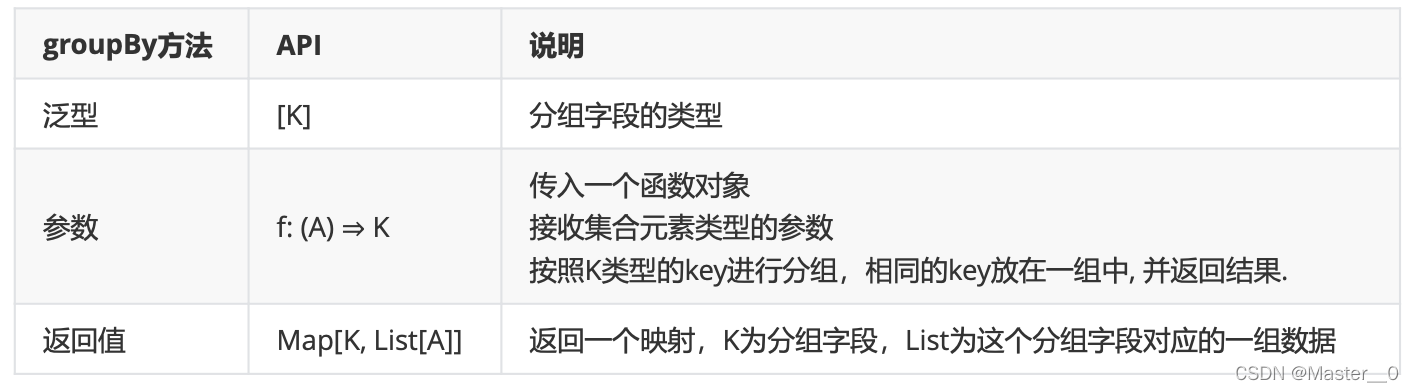
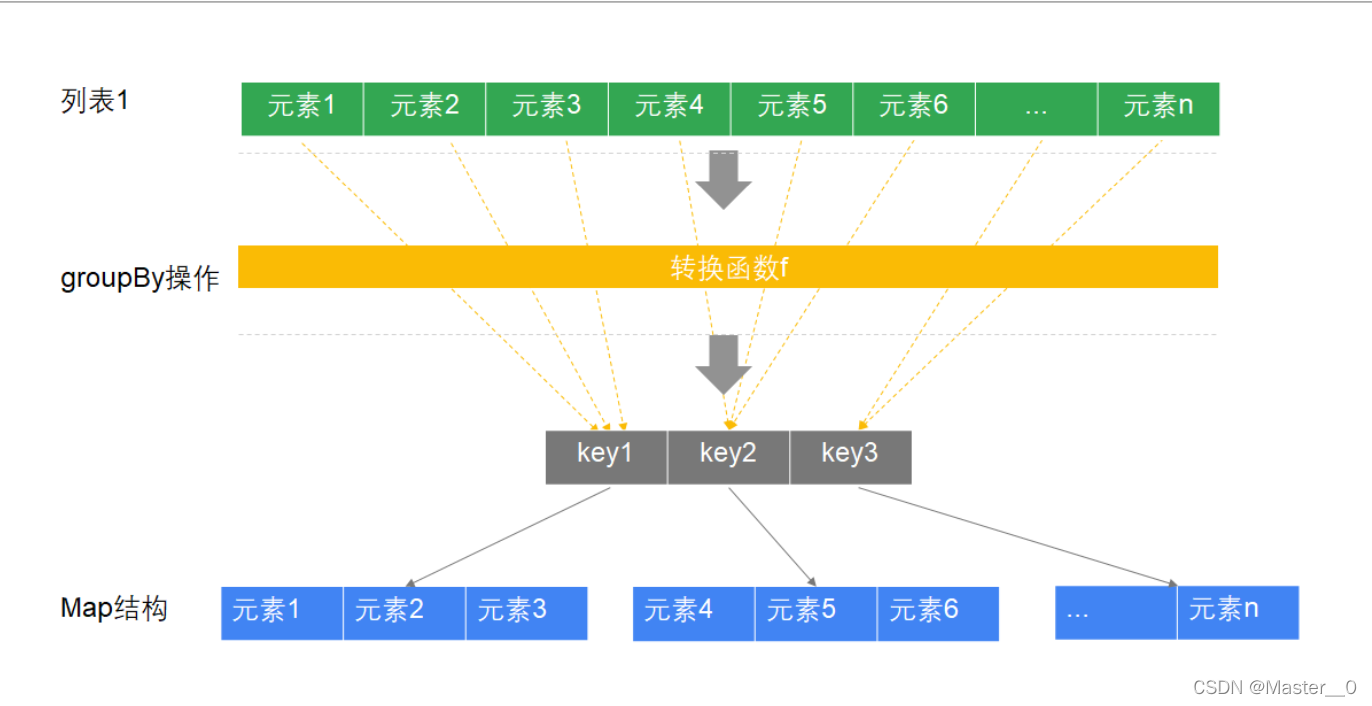
7.7 示例七: 分组(groupBy)
分组指的是 将数据按照指定条件进行分组 , 从而方便我们对数据进行统计分析.
格式
def groupBy[K](f:(A) => K): Map[K, List[A]]
//简写形式:
def groupBy(f:(A) => 具体的分组代码)
说明
执行过程
需求
- 有一个列表,包含了学生的姓名和性别: “刘德华” -> “男”, “刘亦菲” -> “女”, “胡歌” -> “男”
- 请按照性别进行分组.
- 统计不同性别的学生人数.
参考代码
//案例: 演示分组函数(groupBy) object ClassDemo31 {
def main(args: Array[String]): Unit = {
//1. 有一个列表,包含了学生的姓名和性别: "刘德华" -> "男", "刘亦菲" -> "女", "胡歌" -> "男"
val list1 = List("刘德华" -> "男", "刘亦菲" -> "女", "胡歌" -> "男")
//2. 请按照性别进行分组.
//val list2 = list1.groupBy(x => x._2)
//简写形式
val list2 = list1.groupBy(_._2)
//println(s"list2: ${list2}")
//3. 统计不同性别的学生人数.
val list3 = list2.map(x => x._1 -> x._2.size)
println(s"list3: ${list3}")
}
}
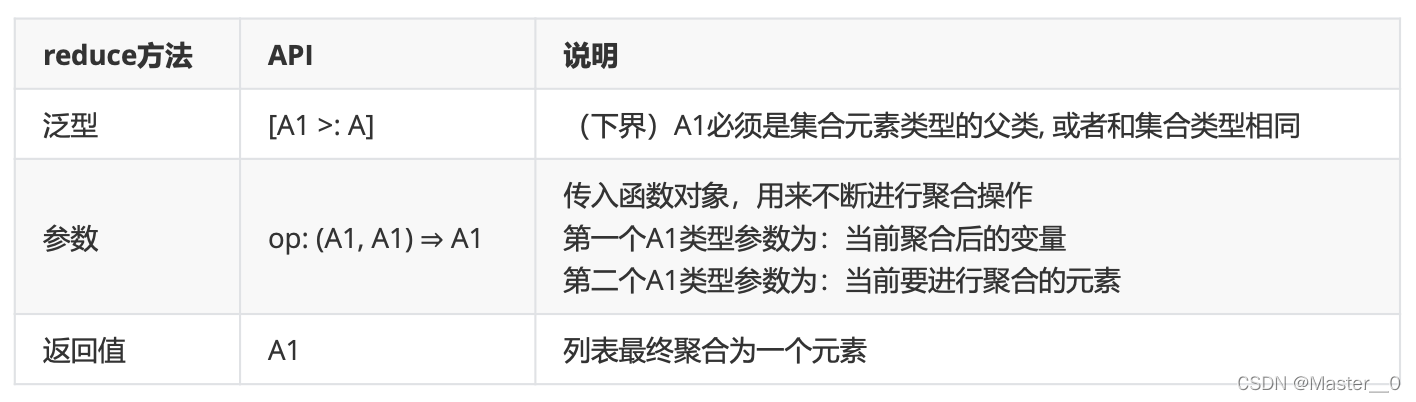
7.8 示例八: 聚合操作
所谓的聚合操作指的是 将一个列表中的数据合并为一个 . 这种操作经常用来统计分析中. 常用的聚合操作主要有两个:
- reduce: 用来对集合元素进行聚合计算
- fold: 用来对集合元素进行折叠计算
7.8.1 聚合(reduce)
reduce表示将列表传入一个函数进行聚合计算.
格式
def reduce[A1 >: A](op:(A1, A1) ⇒ A1): A1
//简写形式:
def reduce(op:(A1, A1) ⇒ A1)
说明
执行过程
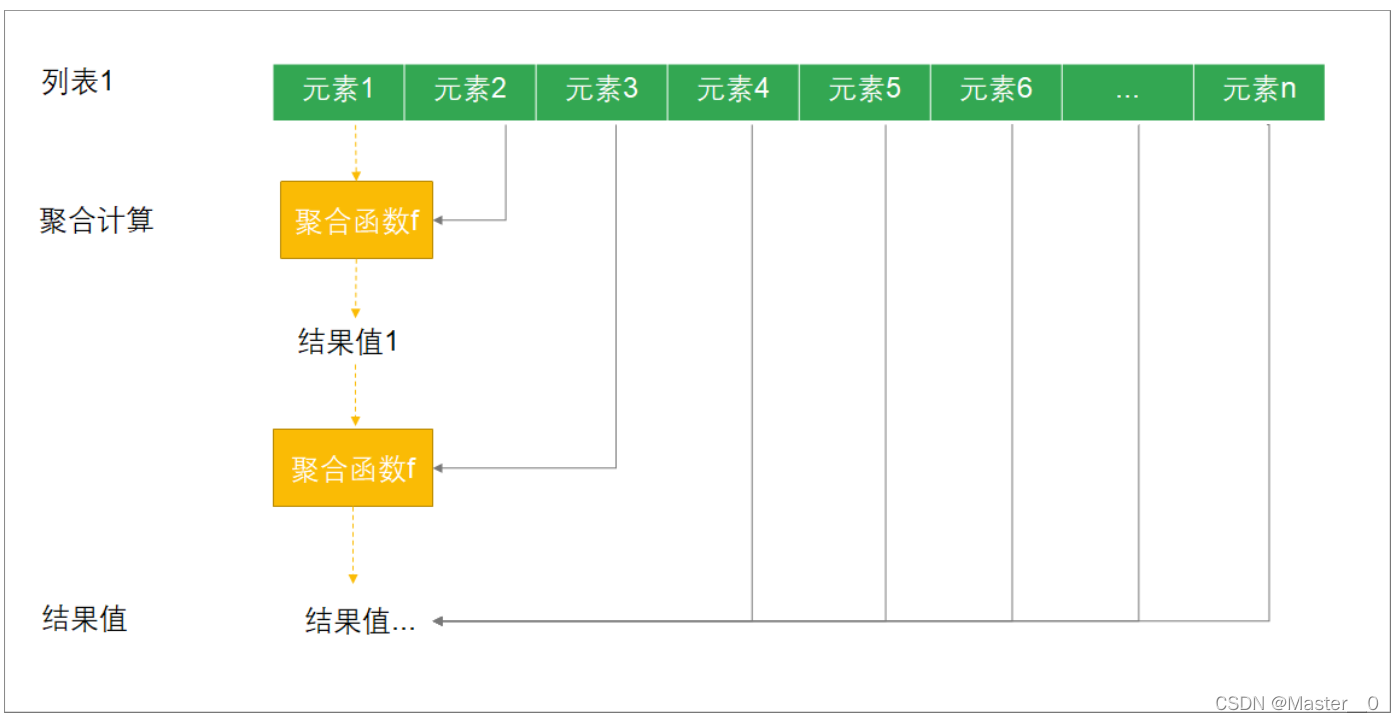
注意:
- reduce和reduceLeft效果一致,表示从左到右计算
- reduceRight表示从右到左计算
需求
- 定义一个列表,包含以下元素:1,2,3,4,5,6,7,8,9,10
- 使用reduce计算所有元素的和
参考代码
//案例: 演示聚合计算(reduce)
object ClassDemo32 {
def main(args: Array[String]): Unit = {
//1. 定义一个列表,包含以下元素:1,2,3,4,5,6,7,8,9,10
val list1 = (1 to 10).toList
//2. 使用reduce计算所有元素的和
//val list2 = list1.reduce((x, y) => x + y)
//简写形式:
val list2 = list1.reduce(_ + _)
val list3 = list1.reduceLeft(_ + _)
val list4 = list1.reduceRight(_ + _)
println(s"list2: ${list2}")
println(s"list3: ${list3}")
println(s"list4: ${list4}")
}
}
7.8.2 折叠(fold)
fold与reduce很像,只不过多了一个指定初始值参数.
格式
def fold[A1 >: A](z: A1)(op:(A1, A1) => A1): A1
//简写形式:
def fold(初始值)(op:(A1, A1) => A
说明
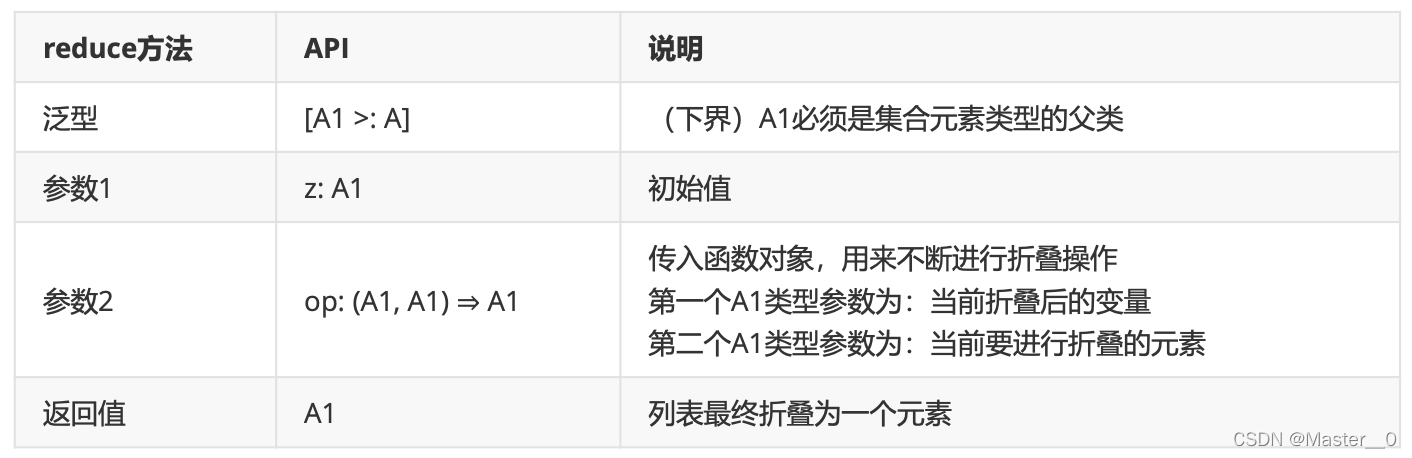
注意事项:
- fold和foldLet效果一致,表示从左往右计算
- foldRight表示从右往左计算
需求
- 定义一个列表,包含以下元素:1,2,3,4,5,6,7,8,9,10
- 假设初始化值是100, 使用fold方法计算所有元素的和.
参考代码
//案例: 演示折叠计算(fold)
object ClassDemo33 {
def main(args: Array[String]): Unit = {
//1. 定义一个列表,包含以下元素:1,2,3,4,5,6,7,8,9,10
val list1 = (1 to 10).toList
//2. 假设初始化值是100, 使用fold计算所有元素的和
//val list2 = list1.fold(100)((x, y) => x + y) //简写形式:
val list2 = list1.fold(100)(_ + _)
val list3 = list1.foldLeft(100)(_ + _)
val list4 = list1.foldRight(100)(_ + _)
println(s"list2: ${list2}")
println(s"list3: ${list3}")
println(s"list4: ${list4}")
}
}
8. 案例: 学生成绩单
8.1 需求
- 定义列表, 记录学生的成绩, 格式为: 姓名, 语文成绩, 数学成绩, 英语成绩, 学生信息如下: (“张三”,37,90,100), (“李四”,90,73,81), (“王五”,60,90,76), (“赵六”,59,21,72), (“田七”,100,100,100)
- 获取所有语文成绩在60分(含)及以上的同学信息.
- 获取所有学生的总成绩.
- 按照总成绩降序排列.
- 打印结果.
8.2 目的
考察 列表及函数式编程 相关知识点.
8.3 参考代码
//案例: 演示折叠计算(fold) object ClassDemo33 {
def main(args: Array[String]): Unit = {
//1. 定义一个列表,包含以下元素:1,2,3,4,5,6,7,8,9,10 val list1 = (1 to 10).toList
//2. 假设初始化值是100, 使用fold计算所有元素的和
//val list2 = list1.fold(100)((x, y) => x + y) //简写形式:
val list2 = list1.fold(100)(_ + )
val list3 = list1.foldLeft(100)( + )
val list4 = list1.foldRight(100)( + _) println(s"list2: ${list2}")
println(s"list3: ${list3}")
println(s"list4: ${list4}")
} }
//案例: 学生成绩单.
object ClassDemo34 {
def main(args: Array[String]): Unit = {
//1. 定义列表, 记录学生的成绩, 格式为: 姓名, 语文成绩, 数学成绩, 英语成绩
val stuList = List(("张三",37,90,100), ("李四",90,73,81), ("王五",60,90,76), ("赵
六",59,21,72), ("田七",100,100,100))
//2. 获取所有语文成绩在60分(含)及以上的同学信息.
val chineseList = stuList.filter(_._2 >= 60)
//3. 获取所有学生的总成绩.
val countList = stuList.map(x => x._1 -> (x._2 + x._3 + x._4))
//4. 按照总成绩降序排列.
val sortList1 = countList.sortBy(_._2).reverse
//也可以通过sortWith实现.
val sortList2 = countList.sortWith((x, y) => x._2 > y._2)
//5. 打印结果.
println(s"语文成绩及格的学生信息: ${chineseList}")
println(s"所有学生及其总成绩: ${countList}")
println(s"总成绩降序排列: ${sortList1}")
println(s"总成绩降序排列: ${sortList2}")
}
}
Scala第十一章节 章节目标
- 掌握模式匹配相关内容
- 掌握option类型及偏函数的用法 3. 掌握异常处理的用法
- 理解正则表达式的运用
- 理解提取器的用法
- 掌握随机职业案例
1. 模式匹配
Scala中有一个非常强大的模式匹配机制,应用也非常广泛, 例如:
- 判断固定值
- 类型查询
- 快速获取数据
1.1 简单模式匹配
一个模式匹配包含了一系列备选项,每个备选项都开始于关键字 case。且每个备选项都包含了一个模式及一到多个表达式。箭头符号 => 隔开了模式和表达式。
格式
变量 match {
case "常量1" => 表达式1
case "常量2" => 表达式2
case "常量3" => 表达式3
case _ => 表达式4 // 默认匹配项
}
执行流程
- 先执行第一个case, 看 变量值 和 该case对应的常量值 是否一致.
- 如果一致, 则执行该case对应的表达式.
- 如果不一致, 则往后执行下一个case, 看 变量值 和 该case对应的常量值 是否一致.
- 以此类推, 如果所有的case都不匹配, 则执行 case _ 对应的表达式.
需求
- 提示用户录入一个单词并接收.
- 判断该单词是否能够匹配以下单词,如果能匹配,返回一句话
- 打印结果.
单词 返回 hadoop 大数据分布式存储和计算框架 zookeeper 大数据分布式协调服务框架 spark 大数据分布式内存计算框架 匹配 未匹配
参考代码
import scala.io.StdIn
//案例: 模式匹配之简单匹配
object ClassDemo01 {
def main(args: Array[String]): Unit = {
//1. 提示用户录入字符串并接收.
println("请录入一个字符串: ")
var str = StdIn.readLine()
//2. 判断字符串是否是指定的内容, 并接收结果.
val result = str match {
case "hadoop" => "大数据分布式存储和计算框架"
case "zookeeper" => "大数据分布式协调服务框架"
case "spark" => "大数据分布式内存计算框架"
case _ => "未匹配"
}
//3. 打印结果.
println(result)
println("-" * 15) //分割线.
//简写形式
str match {
case "hadoop" => println("大数据分布式存储和计算框架")
case "zookeeper" => println("大数据分布式协调服务框架")
case "spark" => println("大数据分布式内存计算框架")
case _ => println("未匹配")
}
}
}
1.2 匹配类型
除了匹配数据之外, match表达式还可以进行类型匹配。如果我们要根据不同的数据类型,来执行不同的逻辑,也
可以使用match表达式来实现。
格式
对象名 match {
case 变量名1: 类型1 => 表达式1
case 变量名2: 类型2 => 表达式2
case 变量名3: 类型3 => 表达式3
...
需求
- 定义一个变量为Any类型,然后分别给其赋值为"hadoop"、1、1.0
- 定义模式匹配,然后分别打印类型的名称
参考代码
//案例: 模式匹配之匹配类型
object ClassDemo02 {
def main(args: Array[String]): Unit = {
//1. 定义一个变量为Any类型,然后分别给其赋值为"hadoop"、1、1.0
val a:Any = 1.0
//2. 定义模式匹配,然后分别打印类型的名称
val result = a match {
case x:String => s"${x} 是String类型的数据"
case x:Double => s"${x} 是Double类型的数据"
case x:Int => s"${x} 是Int类型的数据"
case _ => "未匹配"
}
//3. 打印结果
println(result)
//4. 优化版, 如果在case校验的时候, 变量没有被使用, 则可以用_替代.
val result2 = a match {
case _:String => "String"
case _:Double => "Double"
case _:Int => "Int"
case _ => "未匹配"
}
//打印结果
println(result2)
}
}
1.3 守卫
所谓的守卫指的是 在case语句中添加if条件判断 , 这样可以让我们的代码更简洁, 更优雅.
格式
变量 match {
case 变量名 if条件1 => 表达式1
case 变量名 if条件2 => 表达式2
case 变量名 if条件3 => 表达式3 ...
case _ => 表达式4
}
需求
- 从控制台读入一个数字a(使用StdIn.readInt)
- 如果 a >= 0 而且 a <= 3,打印[0-3]
- 如果 a >= 4 而且 a <= 8,打印[4,8]
- 否则,打印未匹配
参考代码
//案例: 模式匹配之守卫
object ClassDemo03 {
def main(args: Array[String]): Unit = {
//1. 从控制台读入一个数字a(使用StdIn.readInt)
println("请录入一个整数: ")
var num = StdIn.readInt()
//2. 模式匹配
num match {
//2.1 如果 a >= 0 而且 a <= 3,打印[0-3]
case a if a >= 0 && a <= 3 => println("[0-3]")
//2.2 如果 a >= 4 而且 a <= 8,打印[4,8]
case a if a >= 4 && a <= 8 => println("[4-8]") //2.3 否则,打印未匹配
case _ => println("未匹配")
}
}
}
1.4 匹配样例类
Scala中可以使用模式匹配来匹配样例类,从而实现可以快速获取样例类中的成员数据。后续,我们在开发Akka案例时,还会经常用到。
格式
对象名 match {
case 样例类型1(字段1, 字段2, 字段n) => 表达式1
case 样例类型2(字段1, 字段2, 字段n) => 表达式2
case 样例类型3(字段1, 字段2, 字段n) => 表达式3
...
case _ => 表达式4
}
注意:
1. 样例类型后的小括号中, 编写的字段个数要和该样例类的字段个数保持一致.
2. 通过match进行模式匹配的时候, 要匹配的对象必须声明为: Any类型.
需求
- 创建两个样例类Customer(包含姓名, 年龄字段), Order(包含id字段)
- 分别定义两个样例类的对象,并指定为Any类型
- 使用模式匹配这两个对象,并分别打印它们的成员变量值
参考代码
//案例: 模式匹配之匹配样例类
object ClassDemo04 {
//1. 创建两个样例类Customer、Order
//1.1 Customer包含姓名、年龄字段
case class Customer(var name: String, var age: Int)
//1.2 Order包含id字段
case class Order(id: Int)
def main(args: Array[String]): Unit = {
//2. 分别定义两个案例类的对象,并指定为Any类型
val c: Any = Customer("糖糖", 73)
val o: Any = Order(123)
val arr: Any = Array(0, 1)
//3. 使用模式匹配这两个对象,并分别打印它们的成员变量值
c match {
case Customer(a, b) => println(s"Customer类型的对象, name=${a}, age=${b}")
case Order(c) => println(s"Order类型, id=${c}")
case _ => println("未匹配")
}
}
}
1.5 匹配集合
除了上述功能之外, Scala中的模式匹配,还能用来匹配数组, 元组, 集合(列表, 集, 映射)等。
1.5.1 示例一: 匹配数组
需求
-
依次修改代码定义以下三个数组
Array(1,x,y) // 以1开头,后续的两个元素不固定 Array(0) // 只匹配一个0元素的元素 Array(0, ...) // 可以任意数量,但是以0开头 -
使用模式匹配, 匹配上述数组.
参考代码
//案例: 模式匹配之匹配数组
object ClassDemo05 {
def main(args: Array[String]): Unit = { //1. 定义三个数组.
val arr1 = Array(1, 2, 3)
val arr2 = Array(0)
val arr3 = Array(1, 2, 3, 4, 5)
//2. 通过模式匹配, 找到指定的数组.
arr2 match {
//匹配: 长度为3, 首元素为1, 后两个元素无所谓.
case Array(1, x, y) => println(s"匹配长度为3, 首元素为1, 后两个元素是: ${x}, ${y}")
//匹配: 只有一个0元素的数组
case Array(0) => println("匹配: 只有一个0元素的数组")
//匹配: 第一个元素是1, 后边元素无所谓的数组.
case Array(1, _*) => println("匹配: 第一个元素是1, 后边元素无所谓的数组")
//其他校验项
case _ => println("未匹配")
}
}
}
1.5.2 示例二: 匹配列表
需求
-
依次修改代码定义以下三个列表
List(0) // 只保存0一个元素的列表 List(0,...) // 以0开头的列表,数量不固定 List(x,y) // 只包含两个元素的列表 -
使用模式匹配, 匹配上述列表.
参考代码
//案例: 模式匹配之匹配列表
object ClassDemo06 {
def main(args: Array[String]): Unit = {
//1. 定义列表.
var list1 = List(0)
var list2 = List(0, 1, 2, 3, 4, 5)
var list3 = List(1, 2)
//2. 通过match进行模式匹配
//思路一: 通过List()来实现.
list1 match {
case List(0) => println("匹配: 只有一个0元素的列表")
case List(0, _*) => println("匹配: 0开头, 后边元素无所谓的列表")
case List(x, y) => println(s"匹配: 只有两个元素的列表, 元素为: ${x}, ${y}")
case _ => println("未匹配")
}
//思路二: 采用关键字优化 Nil,
tail list1 match {
case 0 :: Nil => println("匹配: 只有一个0元素的列表")
case 0 :: tail => println("匹配: 0开头, 后边元素无所谓的列表")
case x :: y :: Nil => println(s"匹配: 只有两个元素的列表, 元素为: ${x}, ${y}") case _ => println("未匹配")
}
}
}
1.5.3 案例三: 匹配元组
需求
-
依次修改代码定义以下两个元组
(1, x, y) // 以1开头的、一共三个元素的元组 (x, y, 5) // 一共有三个元素,最后一个元素为5的元组 -
使用模式匹配, 匹配上述元组.
参考代码
//案例: 模式匹配之匹配元组
object ClassDemo07 {
def main(args: Array[String]): Unit = {
//1. 定义两个元组.
val a = (1, 2, 3)
val b = (3, 4, 5)
val c = (3, 4)
//2. 通过模式匹配, 匹配指定的元素
a match {
case (1, x, y) => println(s"匹配: 长度为3, 以1开头, 后两个元素无所谓的元组, 这里后两个元素 是: ${x}, ${y}")
case (x, y, 5) => println(s"匹配: 长度为3, 以5结尾, 前两个元素无所谓的元素, 这里前两个元素 是: ${x}, ${y}")
case _ => println("未匹配") }
}
}
1.6 变量声明中的模式匹配
在定义变量时,可以使用模式匹配快速获取数据. 例如: 快速从数组,列表中获取数据 .
需求
- 生成包含0-10数字的数组,使用模式匹配分别获取第二个、第三个、第四个元素
- 生成包含0-10数字的列表,使用模式匹配分别获取第一个、第二个元素
参考代码
//案例: 演示变量声明中的模式匹配.
object ClassDemo08 {
def main(args: Array[String]): Unit = {
//1. 生成包含0-10数字的数组,使用模式匹配分别获取第二个、第三个、第四个元素
//1.1 生成包含0-10数字的数组
val arr = (0 to 10).toArray
//1.2 使用模式匹配分别获取第二个、第三个、第四个元素
val Array(_, x, y, z, _*) = arr;
//1.3 打印结果.
println(x, y, z)
println("-" * 15)
//2. 生成包含0-10数字的列表,使用模式匹配分别获取第一个、第二个元素
//2.1 生成包含0-10数字的列表,
val list = (0 to 10).toList
//2.2 使用模式匹配分别获取第一个、第二个元素
//思路一: List() 实现
val List(a, b, _*) = list
//思路二: ::, tail 实现.
val c :: d :: tail = list
//2.3 打印结果.
println(a, b)
println(c, d)
}
}
1.7 匹配for表达式
Scala中还可以使用模式匹配来匹配for表达式,从而实现快速获取指定数据, 让我们的代码看起来更简洁, 更优雅.
需求
- 定义变量记录学生的姓名和年龄, 例如: “张三” -> 23, “李四” -> 24, “王五” -> 23, “赵六” -> 26
- 获取所有年龄为23的学生信息, 并打印结果.
参考代码
//案例: 模式匹配之匹配for表达式.
object ClassDemo09 {
def main(args: Array[String]): Unit = {
//1. 定义变量记录学生的姓名和年龄.
val map1 = Map("张三" -> 23, "李四" -> 24, "王五" -> 23, "赵六" -> 26)
//2. 获取所有年龄为23的学生信息.
//2.1 格式一: 通过if语句实现.
for((k,v) <- map1 if v == 23) println(s"${k} = ${v}")
//分割线.
println("-" * 15)
//2.2 格式二: 通过固定值实现.
for((k, 23) <- map1) println(k + " = 23")
}
}
2. Option类型
2.1 概述
实际开发中, 在返回一些数据时, 难免会遇到空指针异常(NullPointerException), 遇到一次就处理一次相对来讲还是 比较繁琐的. 在Scala中, 我们返回某些数据时,可以返回一个ption类型的对象来封装具体的数据,从而实现有效 的避免空指针异常。
2.2 格式
Scala中,Option类型表示可选值。这种类型的数据有两种形式:
-
Some(x):表示实际的值

-
None:表示没有值

注意: 使用getOrElse方法,当值为None时可以指定一个默认值.
2.3 示例
需求
- 定义一个两个数相除的方法,使用Option类型来封装结果
- 打印结果
- 不是除零,打印结果
- 除零, 则打印异常错误
参考代码
//案例: 演示Option类型
object ClassDemo10 {
//1. 定义一个两个数相除的方法,使用Option类型来封装结果
def div(a:Int, b:Int) = {
if (b == 0) {
None //除数为0, 没有结果.
} else {
Some(a / b) //除数不为0, 返回具体的结果.
}
}
def main(args: Array[String]): Unit = {
//2. 然后使用模式匹配来打印结果
val result = div(10 , 0)
//思路一: 通过模式匹配来打印结果.
result match {
//不是除零,打印结果
case Some(x) => println(x) //除零打印异常错误
case None => println("除数不能为0")
}
println("-" * 15)
//思路二: 采用getOrElse()方法实现.
println(result.getOrElse(0))
}
}
3. 偏函数
3.1 定义
偏函数提供了更简洁的语法,可以简化函数的定义。配合集合的函数式编程,可以让代码更加优雅。
所谓的偏函数是指 被包在花括号内没有match的一组case语句 , 偏函数是PartialFunction[A, B]类型的的一个实例对象, 其中A代表输入参数类型, B代表返回结果类型.
3.2 格式
val 对象名 = {
//这对大括号及其内部的一组case语句, 就组成了一个偏函数.
case 值1 => 表达式1
case 值2 => 表达式2
case 值3 => 表达式3
...
}
3.3 示例一: 入门案例
需求 定义一个偏函数,根据以下方式返回
| 输入 | 返回值 |
|---|---|
| 1 | 一 |
| 2 | 二 |
| 3 | 三 |
| 其他 |
参考代码
//案例: 演示偏函数
object ClassDemo11 {
def main(args: Array[String]): Unit = {
//1. 定义一个偏函数, 根据指定格式返回
val pf:PartialFunction[Int,String] = {
case 1 => "一"
case 2 => "二"
case 3 => "三"
case _ => "其他"
}
//2. 调用方法
println(pf(1))
println(pf(2))
println(pf(3))
println(pf(4))
}
}
3.4 示例二: 结合map函数使用
需求
- 定义一个列表,包含1-10的数字
- 请将1-3的数字都转换为[1-3]
- 请将4-8的数字都转换为[4-8]
- 将其他的数字转换为(8-*]
- 打印结果.
参考代码
//案例: 偏函数使用, 结合map函数
object ClassDemo12{
def main(args: Array[String]): Unit = {
//1. 定义一个列表,包含1-10的数字
val list1 = (1 to 10).toList
//核心: 通过偏函数结合map使用, 来进行模式匹配
val list2 = list1.map {
//2 请将1-3的数字都转换为[1-3]
case x if x >= 1 && x <= 3 => "[1-3]"
//3 请将4-8的数字都转换为[4-8]
case x if x >= 4 && x <= 8 => "[4-8]" //4 将其他的数字转换为(8-*]
case _ => "(8-*]"
}
//5. 打印结果.
println(list2)
}
}
4. 正则表达式
4.1 概述
所谓的正则表达式指的是 正确的, 符合特定规则的式子 , 它是一门独立的语言, 并且能被兼容到绝大多数的编程语言 中. 在scala中, 可以很方便地使用正则表达式来匹配数据。具体如下:
- Scala中提供了 Regex类 来定义正则表达式.
- 要构造一个Regex对象,直接使用 String类的r方法 即可.
- 建议使用三个双引号来表示正则表达式,不然就得对正则中的反斜杠进行转义.
4.2 格式
val 正则对象名 = """具体的正则表达式""".r
注意: 使用findAllMatchIn方法可以获取到所有正则匹配到的数据(字符串).
4.3 示例一: 校验邮箱是否合法
需求
- 定义一个字符串, 表示邮箱.
- 定义一个正则表达式,来匹配邮箱是否合法.
- 合法邮箱测试:qq12344@163.com
- 不合法邮箱测试:qq12344@.com
- 打印结果.
参考代码
//案例: 校验邮箱是否合法.
object ClassDemo13 {
def main(args: Array[String]): Unit = {
//需求: 定义一个正则表达式,来匹配邮箱是否合法
//1. 定义一个字符串, 表示邮箱.
val email = "qq12344@163.com"
//2. 定义一个正则表达式, 用来校验邮箱.
/*
. 表示任意字符
+ 数量词, 表示前边的字符出现至少1次, 至多无所谓.
@ 表示必须是@符号, 无特殊含义.
\. 因为.在正则中有特殊的含义, 所以要转移一下, 使它变成普通的. */
val regex = """.+@.+\..+""".r
//3. 打印结果.
if(regex.findAllMatchIn(email).size != 0) {
//合法邮箱
println(s"${email} 是一个合法的邮箱!") }
else {
println(s"${email} 是一个非法的邮箱!")
}
}
}
4.4 示例二: 过滤所有不合法邮箱
需求
- 找出以下列表中的所有不合法的邮箱.
- “38123845@qq.com”,“a1da88123f@gmail.com”, “zhansan@163.com”, “123afadff.com”
参考代码
//案例: 过滤所有不合法的邮箱.
object ClassDemo14 {
def main(args: Array[String]): Unit = {
//1. 定义列表, 记录邮箱.
val emlList = List("38123845@qq.com", "a1da88123f@gmail.com", "zhansan@163.com",
"123afadff.com")
//2. 定义正则表达式.
val regex = """.+@.+\..+""".r
//3. 通过 过滤器 获取所有的不合法的邮箱.
val list = emlList.filter(x => regex.findAllMatchIn(x).size == 0)
//4. 打印结果.
println(list)
}
}
4.5 示例三: 获取邮箱运营商
需求
-
定义列表, 记录以下邮箱:
"38123845@qq.com", "a1da88123f@gmail.com", "zhansan@163.com", "123afadff.com" -
使用正则表达式进行模式匹配,匹配出来邮箱运营商的名字。
例如: 邮箱zhansan@163.com,需要将163(运营商的名字)匹配出来. 提示: 1. 使用括号来匹配分组. 2. 打印匹配到的邮箱以及运营商.
参考代码
//案例: 获取邮箱运营商.
object ClassDemo15 {
def main(args: Array[String]): Unit = {
//1. 定义列表, 记录邮箱.
val emlList = List("38123845@qq.com", "a1da88123f@gmail.com", "zhansan@163.com",
"123afadff.com")
//2. 定义正则表达式.
val regex = """.+@(.+)\..+""".r
//3. 根据 模式匹配 匹配出所有合法的邮箱及其对应的运营商.
val result = emlList.map {
//email就是emlList这个列表中的每一个元素.
//company表示: 正则表达式中你用()括起来的内容, 也就是分组的数据.
case email @ regex(company) => email -> s"${company}"
case email => email -> "未匹配"
}
//4. 打印结果
println(result)
}
}
5. 异常处理
5.1 概述
来看看下面这一段代码:
def main(args: Array[String]): Unit = {
val i = 10 / 0
println("你好!")
}
Exception in thread "main" java.lang.ArithmeticException: / by zero
at ForDemo$.main(ForDemo.scala:3)
at ForDemo.main(ForDemo.scala)
执行程序,可以看到scala抛出
了异常,而且没有打印出来"你好! "。说明程序出现错误后就终止了。 那怎么解决该问题呢?
在Scala中,可以使用异常处理来解决这个问题. 而异常处理又分为两种方式:
- 方式一: 捕获异常.
注意: 该方式处理完异常后, 程序会继续执行.
- 方式二: 抛出异常.
注意: 该方式处理完异常后, 程序会终止执行.
5.2 捕获异常
格式
try {
//可能会出现问题的代码
}
catch{
case ex:异常类型1 => //代码
case ex:异常类型2 => //代码
}
finally {
//代码
}
解释:
1. try中的代码是我们编写的业务处理代码.
2. 在catch中表示当出现某个异常时,需要执行的代码.
3. 在finally中,写的是不管是否出现异常都会执行的代码.
5.3 抛出异常
我们也可以在一个方法中,抛出异常。格式如下:
格式
throw new Exception("这里写异常的描述信息")
5.4 示例
需求
- 通过try.catch来处理 除数为零异常.
- 在main方法中抛出一个异常.
参考代码
//案例: 演示异常处理.
object ClassDemo16 {
def main(args: Array[String]): Unit = {
//1. 通过try.catch来处理 除数为零异常.
try {
//可能出问题的代码
val i = 10 / 0
} catch {
//出现问题后的解决方案.
//case ex:Exception => println("代码出问题了!")
case ex:Exception => ex.printStackTrace()
}
println("你好!")
println("-" * 15) //我是分割线.
//2. 抛出一个异常对象.
throw new Exception("我是一个Bug!")
println("Hello, Scala!") //这行代码并不会被执行.
}
}
6. 提取器(Extractor)
6.1 概述
我们之前已经使用过Scala中非常强大的模式匹配功能了,通过模式匹配,我们可以快速获取样例类对象中的成员 变量值。例如:
// 1. 创建两个样例类
case class Person(name:String, age:Int)
case class Order(id:String)
def main(args: Array[String]): Unit = {
// 2. 创建样例类对象,并赋值为Any类型
val zhangsan:Any = Person("张三", 20)
val order1:Any = Order("001")
// 3. 使用match...case表达式来进行模式匹配
// 获取样例类中成员变量
order1 match {
} }
那是不是所有的类都可以进行这样的模式匹配呢?
答案是:
不是 。一个类要想支持模式匹配,则必须要实现一个提取器。
注意:
1. 提取器指的就是 unapply()方法 .
2. 样例类自动实现了apply()、unapply()方法, 无需我们手动定义.
6.2 格式
要实现一个类的提取器,只需要在该类的伴生对象中实现一个unapply方法即可。
语法格式
def unapply(stu:Student):Option[(类型1, 类型2, 类型3...)] = {
if(stu != null) {
Some((变量1, 变量2, 变量3...))
}
else {
None
}
}
图解
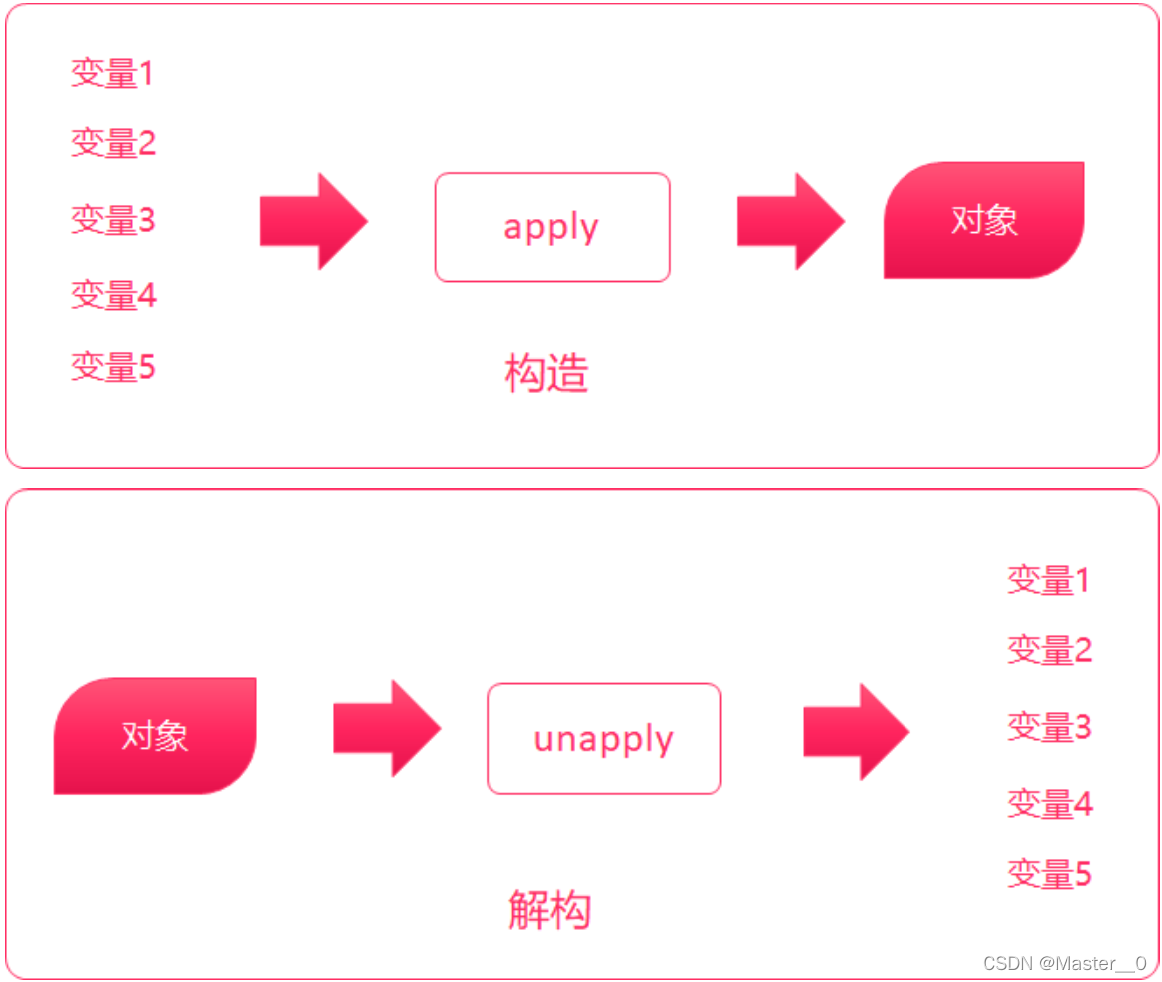
6.3 示例 需求
- 创建一个Student类,包含姓名年龄两个字段
- 实现一个类的提取器,并使用match表达式进行模式匹配,提取类中的字段。
参考代码
//案例: 演示Scala中的提取器.
//所谓的提取器就是: 在类的伴生对象中, 重写一个unapply()方法即可.
object ClassDemo17 {
//1. 创建一个Student类,包含姓名年龄两个字段
class Student(var name:String, var age:Int)
//2. 实现一个类的提取器,并使用match表达式进行模式匹配,提取类中的字段。
object Student { //伴生对象.
def apply(name:String, age:Int) = new Student(name, age) //免new
def unapply(s: Student): Option[(String, Int)] = { //相当于把对象 拆解成 其各个属性.
if (s != null)
Some(s.name, s.age)
else
None
}
}
//main方法, 作为程序的主入口.
def main(args: Array[String]): Unit = {
//3. 创建Student类的对象.
val s = new Student("糖糖", 73)
val s2 = Student("糖糖", 73)
//4. 打印对象的属性值
println(s2.name + "..." + s.age)
//5. 通过提取器获取对象中的方法.
val result = Student.unapply(s2)
println(result)
}
}
7. 案例: 随机职业
7.1 需求
- 提示用户录入一个数字(1~5), 然后根据用户录入的数字, 打印出他/她上辈子的职业.
- 假设: 1-> 一品带刀侍卫, 2 -> 宰相, 3 -> 江湖郎中, 4 -> 打铁匠, 5 -> 店小二.
7.2 目的
考察 键盘录入, 模式匹配 相关内容.
7.3 步骤
- 提示用户录入数字, 并接收.
- 通过模式匹配获取该用户上辈子的职业.
- 打印结果.
7.4 参考代码
//案例: 随机职业.
object ClassDemo18 {
def main(args: Array[String]): Unit = {
//1. 提示用户录入数字, 并接收.
println("请录入一个数字(1~5), 我来告诉您上辈子的职业: ") val num = StdIn.readInt()
//2. 通过模式匹配获取该用户上辈子的职业.
//假设: 1-> 一品带刀侍卫, 2 -> 宰相, 3 -> 江湖郎中, 4 -> 打铁匠, 5 -> 店小二.
val occupation = num match {
case 1 => "一品带刀侍卫" case 2 => "宰相"
case 3 => "江湖郎中" case 4 => "打铁匠"
case 5 => "店小二"
case _ => "公公"
}
//3. 打印结果.
println(s"您上辈子的职业是: ${occupation}") }
}
Scala第十二章节
章节目标
- 掌握Source读取数据的功能
- 掌握写入数据的功能
- 掌握学员成绩表案例
1. 读取数据
在Scala语言的 Source单例对象中 中, 提供了一些非常便捷的方法, 从而使开发者可以快速的从指定数据源(文本文
件, URL地址等)中获取数据, 在使用 Source单例对象 之前, 需要先导包, 即 import scala.io.Source .
1.1 按行读取
我们可以以 行 为单位, 来读取数据源中的数据, 返回值是一个 迭代器类型的对象 . 然后通过 toArray, toList 方 法, 将这些数据放到数组或者列表中即可.
注意: Source类扩展自Iterator[Char]
格式
//1. 获取数据源文件对象.
val source:BufferedSource = Source.fromFile("数据源文件的路径","编码表")
//2. 以行为单位读取数据.
val lines:Iterator[String] = source.getLines()
//3. 将读取到的数据封装到列表中.
val list1:List[String] = lines.toList
//4. 千万别忘记关闭Source对象.
source.close()
需求
-
在当前项目下创建data文件夹, 并在其中创建1.txt文本文件, 文件内容如下:
好好学习, 天天向上! Hadoop, Zookeeper, Flume, Spark Flink, Sqoop, HBase 选择黑马, 成就你一生的梦想. -
以行为单位读取该文本文件中的数据, 并打印结果.
参考代码
import scala.io.Source
//案例: 演示读取行.
object ClassDemo01 {
def main(args: Array[String]): Unit = {
//1. 获取数据源对象.
val source = Source.fromFile("./data/1.txt")
//2.通过getLines()方法, 逐行获取文件中的数据.
var lines: Iterator[String] = source.getLines()
//3. 将获取到的每一条数据都封装到列表中.
val list1 = lines.toList
//4. 打印结果
for(s <- list1) println(s)
//5. 记得关闭source对象.
source.close()
}
}
1.2 按字符读取
Scala还提供了 以字符为单位读取数据 这种方式, 这种用法类似于迭代器, 读取数据之后, 我们可以通过hasNext(),next()方法, 灵活的获取数据.
格式
//1. 获取数据源文件对象.
val source:BufferedSource = Source.fromFile("数据源文件的路径","编码表")
//2. 以字符为单位读取数据.
val iter:BufferedIterator[Char] = source.buffered
//3. 将读取到的数据封装到列表中.
while(iter.hasNext) {
print(iter.next())
}
//4. 千万别忘记关闭Source对象.
source.close()
注意:
如果文件不是很大, 我们可以直接把它读取到一个字符串中.val str:String = source.mkString
需求
-
在当前项目下创建data文件夹, 并在其中创建1.txt文本文件, 文件内容如下:
好好学习, 天天向上! Hadoop, Zookeeper, Flume, Spark Flink, Sqoop, HBase 选择黑马, 成就你一生的梦想. -
以行为单位读取该文本文件中的数据, 并打印结果.
参考代码
import scala.io.Source
//案例: 演示读取单个字符.
object ClassDemo02 {
def main(args: Array[String]): Unit = {
//1. 获取数据源对象.
val source = Source.fromFile("./data/1.txt")
//2. 获取数据源文件中的每一个字符.
val iter = source.buffered //这里, source对象的用法相当于迭代器.
//3. 通过hasNext(), next()方法获取数据.
while(iter.hasNext) {
print(iter.next()) //细节, 这里不要用println(), 否则输出结果可能不是你想要的.
}
//4. 通过mkString方法, 直接把文件中的所有数据封装到一个字符串中.
val str = source.mkString
//5. 打印结果.
println(str)
//6. 关闭source对象, 节约资源, 提高效率.
source.close()
}
}
1.3 读取词法单元和数字
所谓的词法单元指的是 以特定符号间隔开的字符串 , 如果数据源文件中的数据都是 数字形式的字符串 , 我们可以很方
便的从文件中直接获取这些数据, 例如:
10 2 5
11 2
5 1 3 2
格式
//1. 获取数据源文件对象.
val source:BufferedSource = Source.fromFile("数据源文件的路径","编码表")
//2. 读取词法单元.
// \s表示空白字符(空格, \t, \r, \n等)
val arr:Array[String] = source.mkString.split("\\s+")
//3. 将字符串转成对应的整数
val num = strNumber.map(_.toInt)
//4. 千万别忘记关闭Source对象.
source.close()
需求
-
在当前项目下创建data文件夹, 并在其中创建2.txt文本文件, 文件内容如下:
10 2 5 11 2 5 1 3 2 -
读取文件中的所有整数, 将其加1后, 把结果打印到控制台.
参考代码
import scala.io.Source
//案例: 读取词法单元和数字.
object ClassDemo03 {
def main(args: Array[String]): Unit = {
val source = Source.fromFile("./data/2.txt")
// \s表示空白字符(空格, \t, \r, \n等)
val strNumber = source.mkString.split("\\s+")
//将字符串转成对应的整数
val num = strNumber.map(_.toInt)
for(a <- num) println(a + 1)
}
}
1.4 从URL或者其他源读取数据
Scala中提供了一种方式, 可以让我们直接从指定的URL路径, 或者其他源(例如: 特定的字符串)中直接读取数据。
格式
-
从URL地址中读取数据
//1. 获取数据源文件对象. val source = Source.fromURL("http://www.itcast.cn") //2. 将数据封装到字符串中并打印. println(source.mkString) -
从其他源读取数据
//1. 获取数据源文件对象. val str = Source.fromString("黑马程序员") println(str.getLines())
需求
- 读取 传智播客官网(http://www.itcast.cn) 页面的数据, 并打印结果.
- 直接读取字符串 黑马程序员 , 并打印结果.
参考代码
import scala.io.Source
//案例: 从URL或者其他源读取数据
object ClassDemo04 {
def main(args: Array[String]): Unit = {
val source = Source.fromURL("http://www.itcast.cn")
println(source.mkString)
val str = Source.fromString("黑马程序员")
println(str.getLines())
}
}
1.5 读取二进制文件
Scala没有提供读取二进制文件的方法, 我们需要通过Java类库来实现.
需求
已知项目的data文件夹下有 05.png 这张图片, 请读取该图片数据, 并将读取到的字节数打印到控制台上.
参考代码
//案例: 读取二进制文件数据.
object ClassDemo05 {
def main(args: Array[String]): Unit = {
val file = new File("./data/04.png")
val fis = new FileInputStream(file)
val bys = new Array[Byte](file.length().toInt)
fis.read(bys)
fis.close()
println(bys.length)
}
}
2. 写入数据
Scala并没有内建的对写入文件的支持, 要写入数据到文件, 还是需要使用Java的类库.
2.1 往文件中写入指定数据
需求
往项目下的data文件夹的3.txt文本文件中, 编写一句话, 内容如下:
好好学习,
天天向上!
参考代码
//案例: 写入数据到文本文件.
object ClassDemo06 {
def main(args: Array[String]): Unit = {
val pw = new FileOutputStream("./data/3.txt")
pw.write("好好学习,\r\n".getBytes())
pw.write("天天向上!".getBytes())
pw.close()
}
}
2.2 序列化和反序列化
在Scala中, 如果想将对象传输到其他虚拟机, 或者临时存储, 就可以通过 序列化和反序列化 来实现了.
- 序列化: 把对象写到文件中的过程.
- 反序列化: 从文件中加载对象的过程.
注意: 一个类的对象要想实现序列化和反序列化操作, 则该类必须继承 Serializable特质 .
需求:
- 定义样例类Person, 属性为姓名和年龄.
- 创建Person样例类的对象p.
- 通过序列化操作将对象p写入到项目下的data文件夹下的4.txt文本文件中.
- 通过反序列化操作从项目下的data文件夹下的4.txt文件中, 读取对象p.
参考代码
//案例: 演示序列化和反序列化操作.
object ClassDemo07 {
case class Person(var name:String, var age:Int)
def main(args: Array[String]): Unit = {
//序列化操作.
/*val p = new Person("张三", 23)
val oos = new ObjectOutputStream(new FileOutputStream("./data/4.txt")) oos.writeObject(p)
oos.close()*/
//反序列化操作.
val ois = new ObjectInputStream(new FileInputStream("./data/4.txt"))
var p: Person = ois.readObject().asInstanceOf[Person]
println(p)
}
}
3. 案例: 学员成绩表
3.1 概述
- 已知项目下的data文件夹的student.txt文本文件中, 记录了一些学员的成绩, 如下:
格式为: 姓名 语文成绩 数学成绩 英语成绩
张三 37 90 100
李四 90 73 81
王五 60 90 76
赵六 89 21 72 田七
100 100 100
- 按照学员的总成绩降序排列后, 按照 姓名 语文成绩 数学成绩 英语成绩 总成绩 的格式, 将数据写到项目下的 data文件夹的stu.txt文件中.
3.2 目的
考察 流, 样例类, 以及函数式编程 相关内容.
3.3 步骤
- 定义样例类Person, 属性为: 姓名, 语文成绩, 数学成绩, 英语成绩, 且该类中有一个获取总成绩的方法.
- 读取指定文件(./data/student.txt)中所有的数据, 并将其封装到List列表中.
- 定义可变的列表ListBuffer[Student], 用来记录所有学生的信息.
- 遍历第二步获取到的数据, 将其封装成Person类的对象后, 并添加到ListBuffer中.
- 对第4步获取到的数据进行排序操作, 并将其转换成List列表.
- 按照指定格式, 通过BufferWriter将排序后的数据写入到目的地文件中(./data/stu.txt)
- 关闭流对象.
3.4 参考代码
//案例: 按照学员的总分降序排列.
object ClassDemo08 {
//1. 定义样例类Person, 属性: 姓名, 语文成绩, 数学成绩, 英语成绩, 且该类中有一个获取总成绩的方法.
case class Student(name:String, chinese:Int, math:Int, english:Int) {
def getSum() = chinese + math + english
}
def main(args: Array[String]): Unit = {
//2. 获取数据源文件对象.
val source = Source.fromFile("./data/student.txt")
//3. 读取指定文件(./data/student.txt)中所有的数据, 并将其封装到List列表中.
var studentList: Iterator[List[String]] = source.getLines().map(_.split("
")).map(_.toList)
//4. 定义可变的列表ListBuffer[Student], 用来记录所有学生的信息.
val list = new ListBuffer[Student]()
//5. 遍历第二步获取到的数据, 将其封装成Person类的对象后, 并添加到ListBuffer中.
for(s <- studentList) {
list += Student(s(0), s(1).toInt, s(2).toInt, s(3).toInt)
}
//6. 对第5步获取到的数据进行排序操作, 并将其转换成List列表.
val sortList = list.sortBy(_.getSum()).reverse.toList
//7. 按照指定格式, 通过BufferWriter将排序后的数据写入到目的地文件中(./data/stu.txt)
val bw = new BufferedWriter(new FileWriter("./data/stu.txt"))
for(s <- sortList) bw.write(s"${s.name} ${s.chinese} ${s.math} ${s.english}
${s.getSum()}\r\n")
//8. 关闭流对象
bw.close()
}
}
Scala第十三章节
章节目标
- 掌握作为值的函数及匿名函数的用法 2. 了解柯里化的用法
- 掌握闭包及控制抽象的用法
- 掌握计算器案例
1. 高阶函数介绍
Scala 混合了面向对象和函数式的特性,在函数式编程语言中,函数是“头等公民”,它和Int、String、Class等其他 类型处于同等的地位,可以像其他类型的变量一样被传递和操作。也就是说, 那么这个函数就被称之为 高阶函数(High-Order Function) .像我们之前学习过的map方法,它就可以接收一 个函数,完成List的转换。
常用的高阶函数有以下几类:
- 作为值的函数
- 匿名函数
- 闭包
- 柯里化等等
2. 作为值的函数
在Scala中,函数就像和数字、字符串一样,可以将函数对象传递给一个方法。例如: 我们可以对算法进行封装,然
后将具体的动作传递给方法,这种特性很有用。
示例
需求
将一个整数列表中的每个元素转换为对应个数的小星星, 如下:
List(1, 2, 3...) => *, **, ***
步骤
- 创建一个函数,用于将数字装换为指定个数的小星星
- 创建一个列表,调用map方法
- 打印转换后的列表
参考代码
//案例: 演示函数可以作为 对象传递.
object ClassDemo01 {
def main(args: Array[String]): Unit = {
//需求: 定义一个列表, 记录1~10的数组, 将该数字转换成对应个数的*.
//1: * , 2: **, 3: ***...
//1. 定义一个列表, 记录1~10的数字.
val list1 = (1 to 10).toList
//2. 定义一个函数对象(函数是Scala中的头等公民), 用来将Int -> String
val func = (a:Int) => "*" * a
//3. 调用函数map, 用来转换数字.
//list1.map(这里需要一个函数)
val list2 = list1.map(func)
//4. 打印结果.
println(list2)
}
}
3. 匿名函数
概述
上述的案例,把 (num:Int) => “*” * num 这个函数赋值给了一个变量,虽然实现了指定的需求, 但是这种写法有 一些啰嗦, 我们可以通过 匿名函数 来优化它。在Scala中,没有赋值给变量的函数就是匿名函数.
示例
通过匿名函数实现, 将一个整数列表中的每个元素转换为对应个数的小星星.
参考代码
//案例: 演示 匿名函数.
object ClassDemo02 {
def main(args: Array[String]): Unit = {
//需求: 定义一个列表, 记录1~10的数组, 将该数字转换成对应个数的*.
//1: * , 2: **, 3: ***...
//1. 定义一个列表, 记录1~10的数字.
val list1 = (1 to 10).toList
//2. 通过map函数用来进行转换, 该函数内部接收一个: 匿名函数.
val list2 = list1.map((a:Int) => "*" * a)
//3. 打印结果.
println(list2)
//简写版: 通过下划线实现.
val list3 = list1.map("*" * _)
//val list4 = list1.map(_ * "*") //不能这样写, 会报错.
println(list3)
}
}
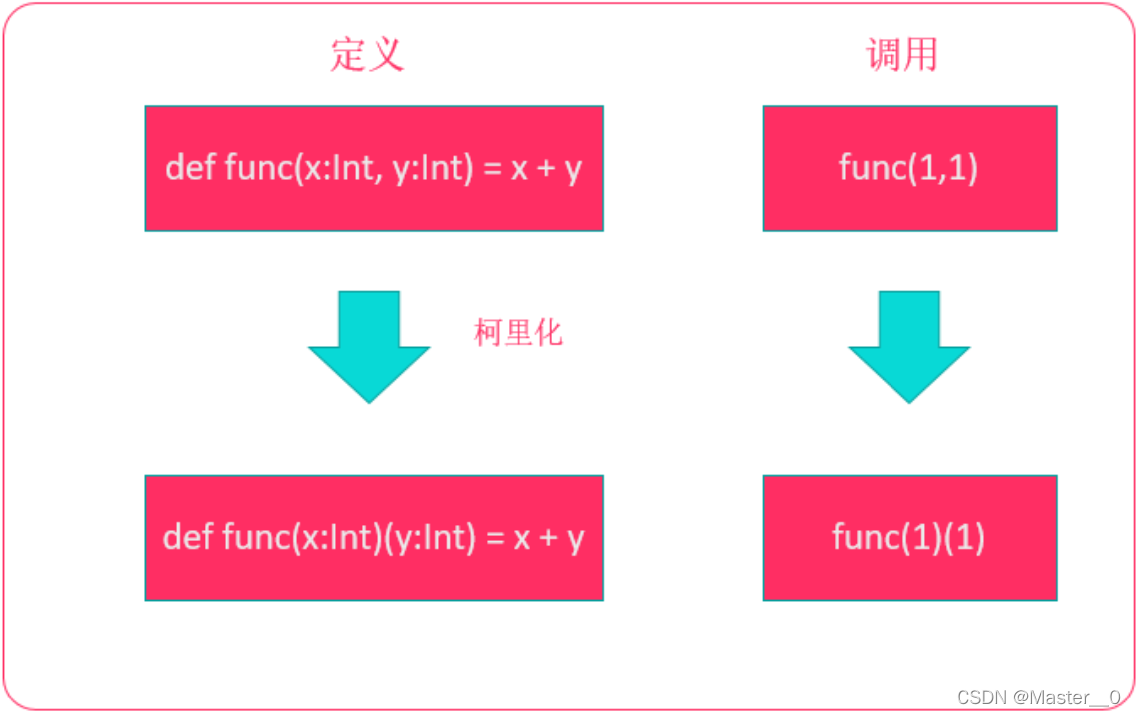
4. 柯里化
4.1 概述
在scala和spark的源代码中,大量使用到了柯里化。为了方便我们后续阅读源代码,我们需要来了解下柯里化。 柯里化(Currying)是指 将原先接受多个参数的方法转换为多个只有一个参数的参数列表的过程 。如下图:
4.2 流程详解
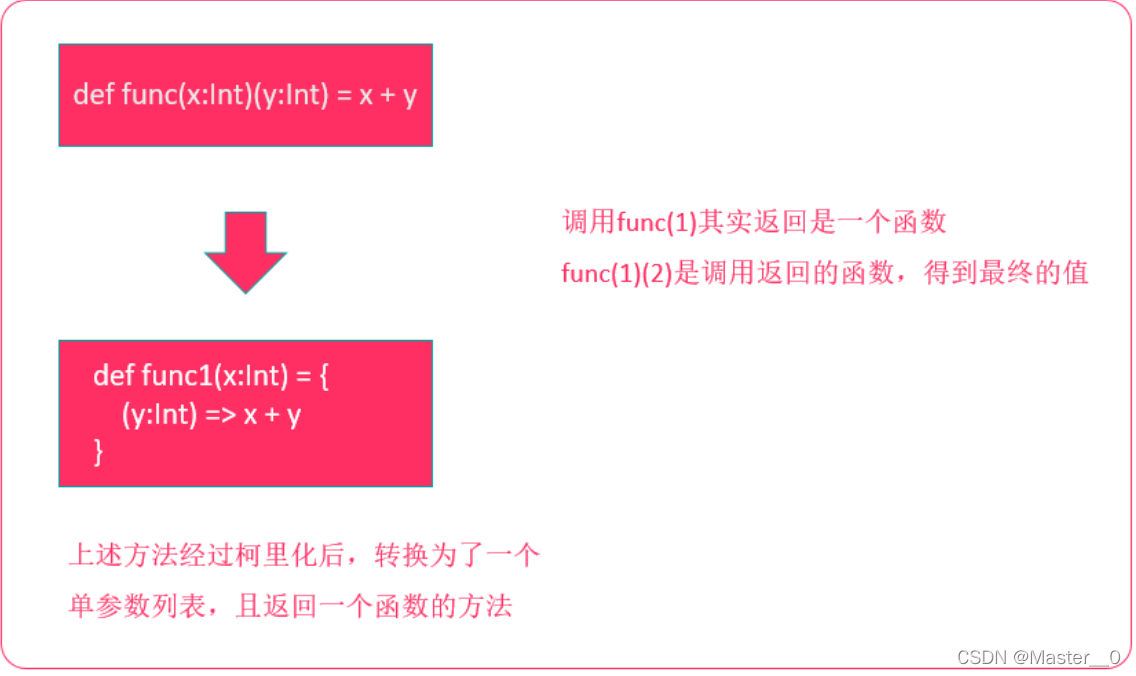
4.3 示例
需求
定义方法, 完成两个字符串的拼接.
参考代码
//案例: 演示柯里化.
object ClassDemo03 {
//需求: 定义方法, 完成两个字符串的拼接.
//方式一: 普通写法.
def merge1(s1:String, s2:String) = s1 + s2
//方式二: 柯里化操作.
def merge2(s1:String, s2:String)(f1: (String, String) => String) = f1(s1, s2)
def main(args: Array[String]): Unit = {
//调用普通写法
println(merge1("abc", "xyz"))
//调用柯里化写法.
println(merge2("abc", "xyz")(_ + _))
println(merge2("abc", "xyz")(_.toUpperCase() + _))
}
}
5. 闭包
闭包指的是 可以访问不在当前作用域范围数据的一个函数.
格式
注意: 柯里化就是一个闭包.
val y = 10 val add = (x:Int) => { x+y } println(add(5)) // 结果15
需求
定义一个函数, 用来获取两个整数的和, 通过闭包的形式实现.
参考代码
//案例: 演示闭包.
object ClassDemo04 {
def main(args: Array[String]): Unit = {
//需求: 定义一个函数, 用来获取两个整数的和.
//1. 在getSum函数外定义一个变量.
val a = 10
//2. 定义一个getSum函数, 用来获取两个整数的和.
val getSum = (b:Int) => a + b
//3. 调用函数
println(getSum(3))
}
}
6. 控制抽象
控制抽象也是函数的一种, 它可以让我们更加灵活的使用函数. 假设函数A的参数列表需要接受一个函数B, 且函数B没有输入值也没有返回值, 那么函数A就被称之为 控制抽象 函数.
格式
val 函数A = (函数B: () => Unit) => {
//代码1
//代码2
//...
函数B()
}
需求
- 定义一个函数myShop, 该函数接收一个无参数无返回值的函数(假设: 函数名叫f1).
- 在myShop函数中调用f1函数.
- 调用myShop函数.
参考代码
//案例: 演示控制抽象.
object ClassDemo05 {
def main(args: Array[String]): Unit = {
//1. 定义函数
val myShop = (f1: () => Unit) => {
println("Welcome in!")
f1()
println("Thanks for coming!")
}
//2. 调用函数
myShop {
() =>
println("我想买一个笔记版电脑")
println("我想买一个平板电脑")
println("我想买一个手机")
}
}
}
7. 案例: 计算器
需求
- 编写一个方法,用来完成两个Int类型数字的计算
- 具体如何计算封装到函数中
- 使用柯里化来实现上述操作
目的
考察 柯里化 相关的内容.
参考代码
//案例: 演示柯里化.
//柯里化(Currying): 将一个有多个参数的参数列表 转换成 多个只有一个参数的参数列表.
/*
示例:
方法名(数值){
//就是一个方法的调用, 只不过让方法的调用更加灵活.
函数
} */
object ClassDemo06 {
//需求: 定义一个方法, 用来完成两个整数的计算(例如: 加减乘除). //方式一: 普通写法.
def add(a:Int, b:Int) = a + b
def subtract(a:Int, b:Int) = a - b
def multiply(a:Int, b:Int) = a * b
def divide(a:Int, b:Int) = a / b
//方式二: 柯里化操作.
//参数列表1: 记录要进行操作的两个数据.
//参数列表2: 记录 具体的操作(加减乘除)
def calculate(a:Int, b:Int)(func: (Int, Int) => Int) = func(a, b)
def main(args: Array[String]): Unit = {
//测试普通方法.
println(add(10, 3))
println(subtract(10, 3))
println(multiply(10, 3))
println(divide(10, 3))
println("*" * 15)
//测试柯里化方法.
// 数值函数
println(calculate(7, 3)(_ + _))
println(calculate(7, 3)(_ - _))
println(calculate(7, 3)(_ * _))
println(calculate(7, 3)(_ / _))
}
}
Scala第十四章节
章节目标
- 掌握隐式转换相关内容
- 掌握隐式参数相关内容
- 掌握获取列表元素平均值的案例
1. 隐式转换和隐式参数介绍
隐式转换和隐式参数是Scala中非常有特色的功能,也是Java等其他编程语言没有的功能。我们可以很方便地利用隐式转换来丰富现有类的功能。在后续编写Akka并发编程, Spark, Flink程序时都会经常用到它们。
- 隐式转换: 指的是用 implicit关键字 声明的带有 单个参数 的方法.
- 隐式参数: 指的是用 implicit关键字 修饰的变量.
注意: implicit关键字 是在Scala的2.10版本出现的.
2. 隐式转换
2.1 概述
所谓隐式转换,是指 以implicit关键字声明的带有单个参数的方法 。该方法是被自动调用的,用来实现 自动将某种类型的数据转换为另外一种类型的数据。
2.2 使用步骤
- 在 object单例对象 中定义隐式转换方法.
隐式转换方法解释: 就是用implicit关键字修饰的方法.
- 在需要用到隐式转换的地方, 引入隐式转换.
类似于 导包 , 通过 import关键字实现 .
- 当需要用到
隐式转换方法时, 程序会自动调用
2.3 示例一: 手动导入隐式转换方法
需求
通过隐式转换, 让File类的对象具备有read功能(即: 实现将文本中的内容以字符串形式读取出来).
步骤
- 创建RichFile类,提供一个read方法,用于将文件内容读取为字符串
- 定义一个隐式转换方法,将File隐式转换为RichFile对象
- 创建一个File类的对象,导入隐式转换,调用File的read方法.
参考代码
import java.io.File import scala.io.Source
//案例: 演示 隐式转换, 手动导入.
/*
隐式转换:
概述:
用implicit修饰的 带有单个参数的方法, 该方法会被自动调用. //前提: 需要手动引入.
作用:
用来丰富某些对象的功能的. 大白话解释: 某个对象没有某个功能, 通过特定手段让他具有此功能.
//简单理解: 这个类似于Java中的装饰设计模式.
//BufferedReader br = new BufferedReader(new FileReader("a.txt))
//这样写会报错, 必须传入一个 要被升级功能的 对象.
//BufferedReader br = new BufferedReader("a.txt")
*/
object ClassDemo01 {
//1. 定义一个RichFile类, 用来给普通的File对象添加 read()功能.
class RichFile(file:File) {
//定义一个read()方法, 用来读取数据.
def read() = Source.fromFile(file).mkString
}
//2. 定义一个单例对象, 包含一个方法, 该方法用于将: 普通的File对象 转换成 RichFile对象.
object ImplicitDemo {
//定义一个方法, 该方法用于将: 普通的File对象 转换成 RichFile对象.
implicit def file2RichFile(file:File) = new RichFile(file)
}
def main(args: Array[String]): Unit = {
//3. 非常非常非常重要的地方: 手动导入 隐式转换.
import ImplicitDemo.file2RichFile
//4. 创建普通的File对象, 尝试调用其read()功能.
val file = new File("./data/1.txt")
/*
执行流程:
1. 先找File类有没有read(), 有就用.
2. 没有就去, 查看有没有该类型的隐式转换, 将该对象转成其他对象.
3. 如果没有隐式转换, 直接报错.
4. 如果可以将该对象升级为其他对象, 则查看升级后的对象中有没有指定方法, 有, 不报错, 没有就报
错.
如下的案例执行流程:
1. file对象中没有read()方法.
2. 检测到有 隐式转换将 file对象 转成 RichFile对象. 3. 调用RichFile对象的read()方法, 打印结果.
*/
println(file.read())
}
}
2.4 隐式转换的时机
既然 这么好用, 那什么时候程序才会自动调用隐式转换方法呢?
- 当对象调用类中不存在的方法或者成员时,编译器会自动对该对象进行隐式转换
- 当方法中的参数类型与目标类型不一致时, 编译器也会自动调用隐式转换.
2.5 示例二: 自动导入隐式转换方法
在Scala中,如果 在当前作用域中有隐式转换方法 ,会自动导入隐式转换。
需求: 将隐式转换方法定义在main所在的 object单例对象 中
import java.io.File
import scala.io.Source
//演示 隐式转换, 自动导入.
object ClassDemo02 {
//1. 定义一个RichFile类, 里边定义一个read()方法.
class RichFile(file:File) {
def read() = Source.fromFile(file).mkString
}
def main(args: Array[String]): Unit = {
//2. 自定义一个方法, 该方法用implicit修饰,
//用来将: 普通的File -> RichFile, 当程序需要使用的时候, 会自动调用.
implicit def file2RichFile(file:File) = new RichFile(file)
//3. 创建File对象, 调用read()方法.
val file = new File("./data/2.txt")
println(file.read())
}
}
3. 隐式参数
在Scala的方法中, 可以带有一个 标记为implicit的参数列表 。调用该方法时, 此参数列表可以不用给初始化值, 因
为 编译器会自动查找缺省值,提供给该方法 。
3.1 使用步骤
- 在方法后面添加一个参数列表,参数使用implicit修饰
- 在object中定义implicit修饰的隐式值
- 调用方法,可以不传入implicit修饰的参数列表,编译器会自动查找缺省值
注意:
1. 和隐式转换一样,可以使用import手动导入隐式参数
2. 如果在当前作用域定义了隐式值,会自动进行导入
3.2 示例
需求
-
定义一个show方法,实现将传入的值,使用指定的前缀分隔符和后缀分隔符包裹起来.
例如: show("张三")("<<<", ">>>"), 则运行结果为: <<<张三>>> -
使用隐式参数定义分隔符.
-
调用该方法,并打印结果.
参考代码
- 方式一: 手动导入隐式参数
//案例: 演示隐式参数, 手动导入.
//演示参数: 如果方法的某个参数列表用implicit修饰了, 则该参数列表就是: 隐式参数. //好处: 我们再调用方法的时候, 关于隐式参数是可以调用默认的值, 不需要我们传入参数.
object ClassDemo03 {
//需求: 定义一个方法, 传入一个姓名, 然后用指定的前缀和后缀将该名字包裹.
//1. 定义一个方法show(), 接收一个姓名, 在接受一个前缀, 后缀信息(这个是隐式参数).
def show(name:String)(implicit delimit:(String, String)) = delimit._1 + name +
delimit._2
//2. 定义一个单例对象, 给隐式参数设置默认值.
object ImplicitParam {
implicit val delimit_defalut = "<<<" -> ">>>"
}
def main(args: Array[String]): Unit = { //3. 手动导入: 隐式参数.
import ImplicitParam.delimit_defalut
//4. 尝试调用show()方法.
println(show("张三"))
println(show("张三")("(((" -> ")))"))
}
}
- 方式二: 自动导入隐式参数
//案例: 演示隐式参数, 自动导入.
//演示参数: 如果方法的某个参数列表用implicit修饰了, 则该参数列表就是: 隐式参数.
//好处: 我们再调用方法的时候, 关于隐式参数是可以调用默认的值, 不需要我们传入参数.
object ClassDemo04 {
//需求: 定义一个方法, 传入一个姓名, 然后用指定的前缀和后缀将该名字包裹.
//1. 定义一个方法show(), 接收一个姓名, 在接受一个前缀, 后缀信息(这个是隐式参数).
def show(name:String)(implicit delimit:(String, String)) = delimit._1 + name +
delimit._2
def main(args: Array[String]): Unit = {
//2. 自动导入 隐式参数.
implicit val delimit_defalut = "<<<" -> ">>>"
//3. 尝试调用show()方法.
println(show("李四"))
println(show("李四")("(((" -> ")))"))
}
}
4. 案例: 获取列表元素平均值
需求
通过隐式转换, 获取列表中所有元素的平均值.
目的
考察 隐式转换, 列表 相关内容.
步骤
- 定义一个RichList类, 用来给普通的List添加avg()方法,用于获取列表元素的平均值.
- 定义avg()方法, 用来获取List列表中所有元素的平均值.
- 定义隐式转换方法, 用来将普通List对象转换为RichList对象.
- 定义List列表, 获取其中所有元素的平均值.
参考代码
object ClassDemo05 {
//1. 定义一个RichList类, 用来给普通的List添加avg()方法.
class RichList(list:List[Int]) {
//2. 定义avg()方法, 用来获取List列表中所有元素的平均值.
def avg() = {
if(list.size == 0) None
else Some(list.sum / list.size)
}
}
//main方法, 作为程序的主入口.
def main(args: Array[String]): Unit = {
//3. 定义隐式转换方法.
implicit def list2RichList(list:List[Int]) = new RichList(list)
//4. 定义List列表, 获取其中所有元素的平均值.
val list1 = List(1, 2, 5, 4, 3)
println(list1.avg())
}
}
Scala第十五章节
章节目标
- 了解递归的相关概述
- 掌握阶乘案例
- 掌握斐波那契数列案例
- 掌握打印目录文件案例
1. 递归
递归指的就是 方法自己调用自己的情况 . 在涉及到复杂操作时, 我们会经常用到它. 在使用递归时, 要注意以下三点:
- 递归必须有出口, 否则容易造成 死递归 .
- 递归必须要有规律.
- 构造方法不能递归.
- 递归方法必有 返回值的数据类型 .
例如: 下述的代码就是递归的写法.
def show() = {
show()
}
2. 案例一: 求阶乘
2.1 概述
所谓的阶乘其实指的是 数字1到该数字的累乘结果 , 例如5的阶乘就相当于 5 * 4 * 3 * 2 * 1 , 4的阶乘就相当于 4 * 3 * 2 * 1 , 根据上述的描述, 我们可以得出两个结论:
1. 阶乘公式为(例如: 求数字n的阶乘): n! = n * (n - 1)!
2. 1的阶乘等于1, 即: 1! = 1
2.2 需求
计算5的阶乘.
2.3 参考代码
//案例: 求5的阶乘.
object ClassDemo01 {
//1. 定义方法, 用来求数字n的阶乘.
def factorial(n:Int):Int = if(n == 1) 1 else n * factorial(n - 1)
def main(args: Array[String]): Unit = {
//2. 调用factorial方法, 用来获取5的阶乘.
val num = factorial(5)
//3. 打印结果.
println(num)
}
}
2.4 内存图解
概述
在Scala中, 内存被分为五部分, 分别为 栈, 堆, 方法区, 本地方法区, 寄存器 , 特点如下:
- 栈
- 功能:
- 所有代码的执行.
- 存储局部变量.
- 特点: 按照 先进后出 的顺序执行, 方法执行完毕后立马被回收.
- 功能:
- 堆:
- 功能: 存储所有new出来的内容(即: 对象)
- 特点: 在不确定的时间被 GC 回收.
- 方法区:
- 功能: 存储字节码文件, 方法等数据.
- 特点: 程序执行完毕后, 由操作系统来回收资源.
- 本地方法区:
- 和 本地方法 相关, 了解即可.
- 寄存器
- 和 CPU 相关, 了解即可.
阶乘图解

3. 案例二: 斐波那契数列
3.1 概述
传说在罗马时期有个意大利青年叫 斐波那契 , 有一天他提出了一个非常有意思的问题, 假设:
- 一对小兔子一个月之后会成长为一对大兔子.
- 每一对大兔子每个月都会生一对小兔子.
- 假设所有兔子都不死亡的情况下, 问: 1对小兔子, 1年之后会变为多少对兔子?
3.2 思路分析
即: 已知数列1, 1, 2, 3, 5, 8, 13…, 问: 第12个数字是多少?
3.3 参考代码
//案例: 斐波那契数列
object ClassDemo02 {
//1. 定义方法, 用来获取兔子的对数.
def rabbit(month:Int):Int = {
if(month == 1 || month == 2) 1
else rabbit(month -1) + rabbit(month - 2)
}
def main(args: Array[String]): Unit = {
//2. 调用方法, 获取第12个月的兔子对数.
val num = rabbit(12)
//3. 打印结果.
println(num)
}
}
4. 案例三: 打印目录文件
4.1 需求
- 定义printFile(dir:File)方法, 该方法接收一个文件目录, 用来打印该目录下所有的文件路径. 2. 在main方法中测试printFile()方法.
4.2 目的
考察 递归, Java的File类 相关内容.
注意: 因为Scala是依赖JVM的, 所以Java中的类库, Scala也可以无缝调用,
4.3 参考代码
import java.io.File
//案例: 获取指定目录下所有的文件.
object ClassDemo03 {
//1. 定义printFile()方法, 用来打印指定目录下所有的文件信息.
def printFile(dir: File): Unit = {
if (!dir.exists()) { println("您录入的路径不存在")
} else {
val listFiles:Array[File] = dir.listFiles()
for(listFile <- listFiles) {
if(listFile.isFile) println(listFile)
else printFile(listFile)
}
}
}
//2.main方法, 作为程序的主入口.
def main(args: Array[String]): Unit = {
//3. 调用方法show()
printFile(new File("d:\\abc"))
}
}

















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









