






 本文深入探讨了PostgreSQL中的查询处理流程,包括解析器、分析器、重写器、规划器和执行器的工作原理,以及如何生成最优执行计划。特别介绍了多表查询优化和连接方法,如嵌套循环、合并和散列连接。
本文深入探讨了PostgreSQL中的查询处理流程,包括解析器、分析器、重写器、规划器和执行器的工作原理,以及如何生成最优执行计划。特别介绍了多表查询优化和连接方法,如嵌套循环、合并和散列连接。
本章概述了查询处理,尤其是查询优化。
本章包括以下三个部分:
- 3.1节概述Postgresql中的查询处理
- 本部分解释了获得单表查询的最优计划所遵循的步骤。在3.2和3.3节中,分别解释了估算成本和创建计划树的过程。3.4节简要描述了执行操作
- 本部分阐述了多表查询的最优方案的获取过程。在3.5节中,描述了3种连接方法:嵌套循环、合并和散列连接。在3.6节中,解释了创建多表查询计划树的过程。
PostgreSQL支持3个有趣且实用的技术特性,即外部数据包装器( Foreign Data Wrappers,FDW)、并行查询(Parallel Query)和JIT编译,这些特性在第11版中得到了支持。前两项将在第4章中描述。JIT编译详情见官方文档。
概要
在PostgreSQL中,虽然在9.6版中使用多个后台工作进程实现了并行查询,但后端进程基本上处理了由连接的客户机发出的所有查询。该后端由五个子系统组成,如下图所示:
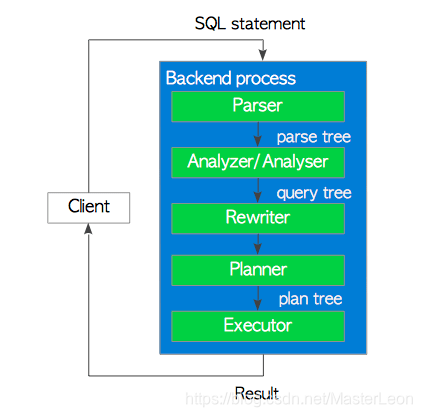
- 解析器(Parser)
解析器以纯文本行式从SQL语句生成分析树。
- 分析器(Analyzer/Analyser)
分析器对分析树进行语义分析并生成查询树。
- 重写器(rewriter)
如果存在规则,则重写器使用存储在规则系统中的规则转换查询树。
- 规划器(Planner)
规划器从查询树生成最有效的执行计划树。
- 执行器(Executor)
执行器通过按照计划树创建的顺序访问表和索引来执行查询。
在本节中,提供了这些子系统的概述。由于planner和executor非常复杂,因此将在以下各节中提供这些功能的详细说明。
PostgreSQL的查询处理在官方文档中有详细描述。
Parser
解析器以纯文本方式从SQL语句生成一个分析树, 后面的子系统可以读取该分析树。下面显示了一个具体的示例, 但没有详细的说明。
testdb=# SELECT id, data FROM tbl_a WHERE id < 300 ORDER BY data;
分析树的根节点是在parsenode.h中的Selectstmt定义。图3.2(b)说明了图3.2(a)所示的查询的分析树。
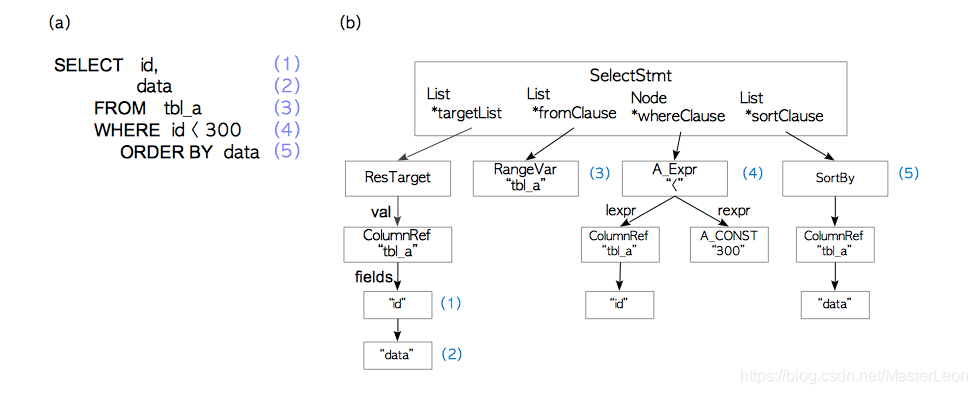
SELECT查询的元素和相应的分析树元素编号相同。例如,(1)是第一个目标列表的一个项目,它是该表的列"id", (4)是where子句,依此类推。
由于解析器在生成分析树时只检查输入的语法,因此它在查询中存在语法错误时才返回错误。
解析器不检查输入查询的语义。例如,即使查询包含不存在的表名,解析器也不会返回错误。语义检查由analyzer/analyser进行。
Analyzer/Analyser

















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









