




0.为什么要学习爬虫?
- 在当今大数据环境下,数据显的十分重要,而爬虫就是去获取数据的一种方式
1.爬虫的定义
- 爬虫就是模拟客户端发送网络请求,接收请求对应的响应,一种按照一定的规则,自动的抓取互联网的程序
2.爬虫的作用
-
只要是浏览器(用户)能够做的事情(原则上:)爬虫都能够做
-
主要用途:数据采集、12306抢票、网上投票、短信轰炸
3.爬虫的分类
- 通用爬虫:通常指搜索引擎的爬虫和大型web服务提供商的爬虫
- 聚焦爬虫:针对特定网站的爬虫,定向的获取某方面数据的爬虫
- 累积式爬虫:从第一页爬到最后一页,过程中会进行去重
- 增量式爬虫:爬取新增的内容
- Deep web爬虫:对应ajax请求所发送的请求:不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面
4.爬虫的流程(重点)
-
爬虫的工作原理
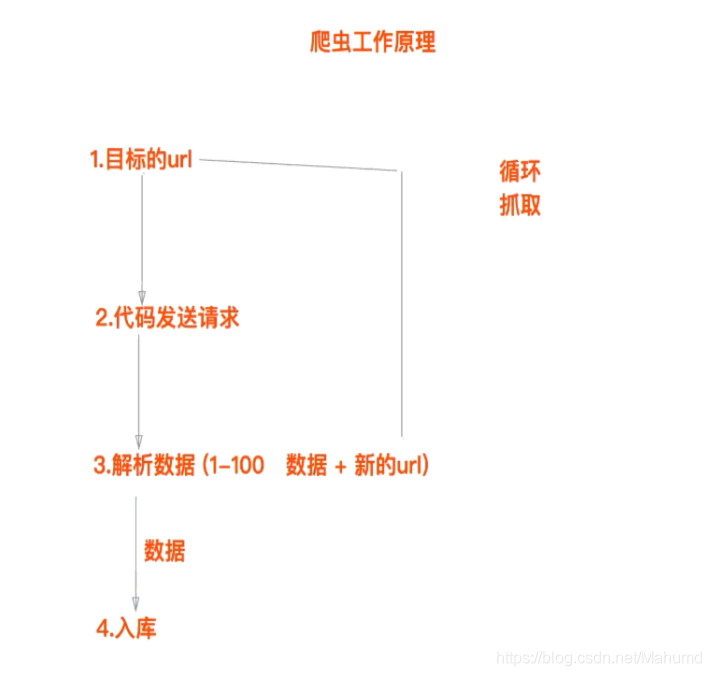
-
聚焦爬虫的流程
1.找到目标的url
2.代码发送请求
3.解析数据
4.入库 -
通用爬虫的流程
1.抓取网页
2.数据存储
3.预处理
4.提供检索服务
5.rebots协议
- 查看:当前的url地址 + ‘/rebots.txt’
- 注意:爬虫不遵守rebots协议,根据具体需求
6.HTTP相关知识
- 请求头中容易被反爬的几个地方:
- user_Agent:用户代理
- refer:跳转的前一个页面
- HTTP常见的请求头信息
- Host (主机和端口号)
- Connection (链接类型)
- Upgrade-Insecure-Requests (升级为HTTPS请求)
- User-Agent (用户代理): 服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等
Accept (传输文件类型)
7.编码问题
encode():str-->bytes
decode(): bytes-->str
encode()和decode()中的utf-8或者gbk要一致
-
str类型和bytes类型:
python2:- unicode()
- bytes(默认)–>又称作str–非unicode字符串
python3:
- unicode(默认)—>又称作str
- bytes
注意:unicode–str:英文字母1个字节,中文3个字节,其他复杂的4-6个字节


















 1133
1133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











