




 本文通过实例演示了如何使用Python的threading模块进行多线程爬虫开发,并对比了单线程与多线程爬虫的速度差异,结果显示多线程爬虫效率提升明显。
本文通过实例演示了如何使用Python的threading模块进行多线程爬虫开发,并对比了单线程与多线程爬虫的速度差异,结果显示多线程爬虫效率提升明显。

系列索引:菜菜的并发编程笔记 | Python并发编程详解(持续更新~)
一、思维导图🕵️♀️
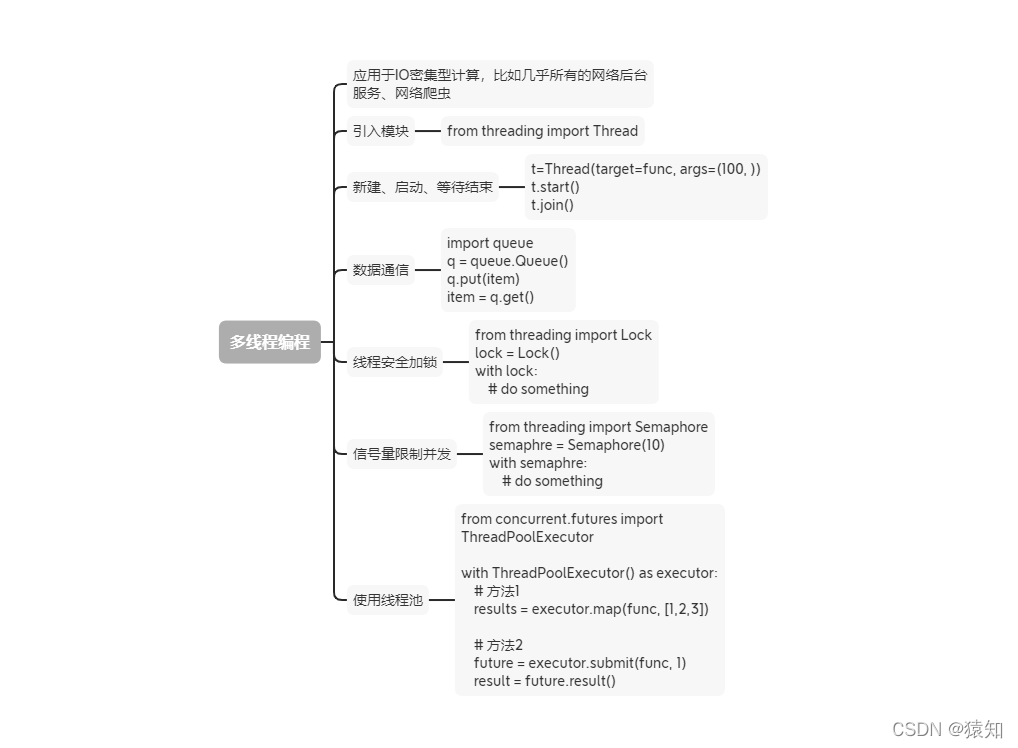
二、Python创建多线程的方法

这里我们以一个爬虫函数为例,主要步骤:导入threading,创建线程,启动,等待结束
三、改写爬虫程序,变成多线程爬取
多线程应用于
IO密集型计算,比如几乎所有的网络后台服务、网络爬虫
import requests
urls = [
f"https://www.cnblogs.com/#p{page}"
for page in range(1, 50 + 1)
]
def craw(url):
r = requests.get(url)
print(url, len(r.text), r.status_code)
craw(urls[2])
这里以爬取博客园为例来进行实验,先写一个基础的代码,运行一次爬取第3页试试,输出:
https://www.cnblogs.com/#p3 69377 200
说明代码正确,继续往下编写:
新建一个文件,导入刚才的基础爬虫代码blog_spider,使用time完成程序计时。然后使用threading模块实现一个多进程的函数,注意 target= 只写函数名,不加(),因为加()表示调用,args表示对应函数的参数,(url,)加逗号是防止被识别为字符串类型。
import blog_spider
import threading
import time
def single_thread():
print("single_thread begin")
for url in blog_spider.urls:
blog_spider.craw(url)
print("single_thread end")
def multi_thread():
print("multi_thread begin")
threads = []
for url in blog_spider.urls:
threads.append(
threading.Thread(target=blog_spider.craw, args=(url,))
)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print("multi_thread end")
if __name__ == "__main__":
start = time.time()
single_thread()
end = time.time()
print("single thread cost:", end - start, "seconds")
start = time.time()
multi_thread()
end = time.time()
print("multi thread cost:", end - start, "seconds")
四、速度对比:单线程爬虫 VS 多线程爬虫
运行代码会发现这效率错了不止10倍!!!
single thread cost: 10.912345170974731 seconds
multi thread cost: 0.5568950176239014 seconds
下一篇我们将以生产者-消费者模式来实现更高级的爬虫程序,欢迎关注~
Python进阶之并发编程篇持续更新,欢迎
点赞收藏+关注
上一篇:菜菜的并发编程笔记 |(二)全局解释器锁GIL
下一篇:菜菜的并发编程笔记 |(四)Python实战生产者-消费者模式多线程爬虫
本人水平有限,文章中不足之处欢迎下方👇评论区批评指正~如果感觉对你有帮助,点个赞👍 支持一下吧 ~
不定期分享 有趣、有料、有营养内容,欢迎 订阅关注 🤝 我的博客 ,期待在这与你相遇 ~


















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











