




 本文对Sentence类进行了优化,使其遵循Python的可迭代协议。通过引入SentenceIterator类和使用生成器,实现了更简洁的迭代逻辑,同时保持了迭代器模式的优点。
本文对Sentence类进行了优化,使其遵循Python的可迭代协议。通过引入SentenceIterator类和使用生成器,实现了更简洁的迭代逻辑,同时保持了迭代器模式的优点。
接下来对上一篇博客的Sentence类进行优化,实现标准的可迭代协议。
import re
import reprlib
from collections import abc
RE_WORD = re.compile('\w+')
class Sentence:
def __init__(self, text):
self.text = text
self.words = RE_WORD.findall(text)
def __repr__(self):
# reprlib.repr 这个实用函数用于生成大型数据结构的简略字符串表示形式
return 'Sentence(%s)' % reprlib.repr(self.text)
def __iter__(self):
return SentenceIterator(self.words)
class SentenceIterator:
def __init__(self, words):
# SentenceIterator 实例引用单词列表。
self.words = words
# self.index 用于确定下一个要获取的单词。
self.index = 0
def __next__(self):
try:
# 获取 self.index 索引位上的单词。
word = self.words[self.index]
except IndexError:
# 如果 self.index 索引位上没有单词,那么抛出 StopIteration 异常。
raise StopIteration()
# 递增 self.index 的值。
self.index += 1
# 返回单词。
return word
# 实现 self.__iter__ 方法
def __iter__(self):
return self
if __name__ == '__main__':
pass
1、与前一版相比,这里只多了一个 __iter__ 方法。这一版没有 __getitem__ 方法,为的是 明确表明这个类可以迭代,因为实现了 __iter__ 方法。
2、根据可迭代协议,__iter__ 方法实例化并返回一个迭代器。
但是上面的代码,其实是不够简洁,还定义实现了一个SentenceIterator 类,这样做很麻烦。下面来看看如何优化。
先对可迭代对象和迭代器进行讨论:
构建可迭代的对象和迭代器时经常会出现错误,原因是混淆了二者。要知道,可迭代的对 象有个 __iter__ 方法,每次都实例化一个新的迭代器;而迭代器要实现 __next__ 方法, 返回单个元素,此外还要实现 __iter__ 方法,返回迭代器本身。因此,迭代器可以迭代,但是可迭代的对象不是迭代器。
除了 __iter__ 方法之外,你可能还想在 Sentence 类中实现 __next__ 方法,让 Sentence 实 例既是可迭代的对象,也是自身的迭代器。可是,这种想法非常糟糕。根据有大量 Python 代码审查经验的 Alex Martelli 所说,这也是常见的反模式。
《设计模式:可复用面向对象软件的基础》一书讲解迭代器设计模式时,在“适用性”一 节中说:
迭代器模式可用来:
1、访问一个聚合对象的内容而无需暴露它的内部表示
2、支持对聚合对象的多种遍历
3、为遍历不同的聚合结构提供一个统一的接口(即支持多态迭代)
为了“支持多种遍历”,必须能从同一个可迭代的实例中获取多个独立的迭代器,而且各 个迭代器要能维护自身的内部状态,因此这一模式正确的实现方式是,每次调用 iter(my_ iterable) 都新建一个独立的迭代器。这就是为什么这个示例需要定义 SentenceIterator 类。
可迭代的对象一定不能是自身的迭代器。也就是说,可迭代的对象必须实现 __iter__ 方法,但不能实现 __next__ 方法。另一方面,迭代器应该一直可以迭代。迭代器的 __iter__ 方法应该返回自身。
那解决方案呢?就是用另一种方式实现 __iter__ 方法,即生成器。
import re
import reprlib
from collections import abc
RE_WORD = re.compile('\w+')
class Sentence:
def __init__(self, text):
self.text = text
self.words = RE_WORD.findall(text)
def __repr__(self):
# reprlib.repr 这个实用函数用于生成大型数据结构的简略字符串表示形式
return 'Sentence(%s)' % reprlib.repr(self.text)
def __iter__(self):
# 迭代 self.words
for i in self.words:
# 产出当前的 word
yield i
# 这个return 语句不是必要的;这个函数可以直接“落空”,自动返回。
# 不管有没有 return 语句,生成器函数都不会抛出 StopIteration 异常,而是在生成完全部值之后会 直接退出
return
if __name__ == '__main__':
s = Sentence('I love python')
ss = iter(s)
print(ss)
print(next(ss))
print(next(ss))
print(next(ss))
print(list(ss))
运行结果:
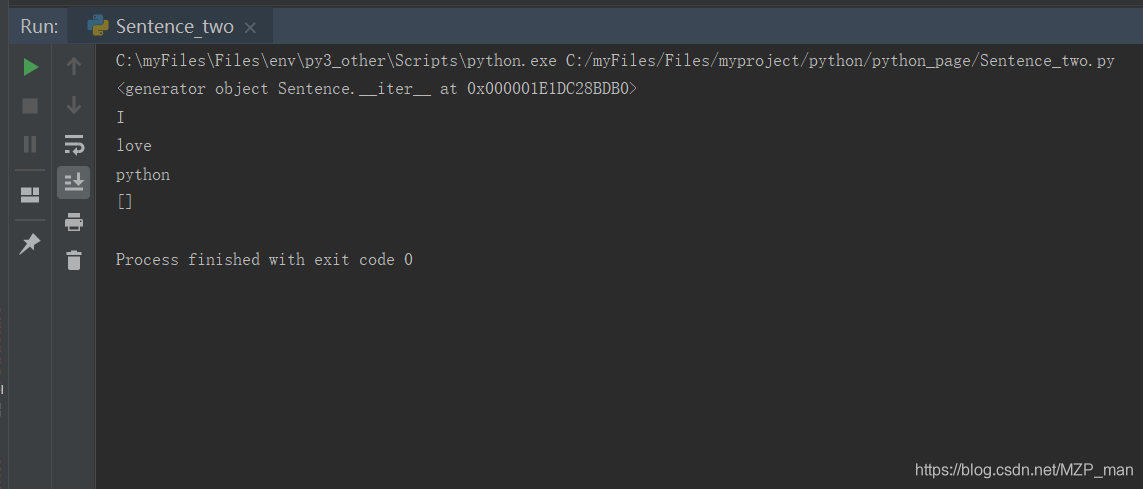 下一节,来讲述生成器函数的工作原理。
下一节,来讲述生成器函数的工作原理。

















 157
157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









