



声明1 本教程完全免费,请勿进行商业化使用
声明2 如有错误或不足之处,欢迎批评指正
声明3 完整代码项目地址:https://github.com/MEZY03/VIC-Data-Preparation
学习资源
VIC模型下载:VIC官方GitHub仓库
VIC官方文档:VIC官方文档
国外视频教程:NASA ARSET VIC模型介绍
国内搬运视频:B站VIC模型教程
目录
Variable Infiltration Capacity (VIC) 是一种半分布式宏观尺度水文模型,通过同时求解水能平衡与能量平衡来模拟地表状态及通量。该模型在水文研究中应用广泛,但其灵活的配置方式意味着需要准备多种输入数据,涉及多种数据处理工具,对初学者易造成困惑。本教程使用统一的Python代码,系统梳理VIC输入数据制备流程,帮助初学者快速理解各参数含义。
环境准备:安装必要的Python依赖库
conda install numpy pandas scipy xarray matplotlib gdal libgdal-hdf4 geopandas shapely rasterstats netcdf4 h5netcdf -c conda-forge辅助工具:安装CDO和NCO气象数据预处理工具
conda install cdo nco -c conda-forge0. VIC数据概览
VIC模型运行需要准备以下核心输入文件:土壤参数文件 (soil_param.txt)、植被参数文件 (veg_param.txt)、植被表 (veg_lib.txt)、气象强迫数据 (forcing_[lat]_[lon])、全局文件 (global_param.txt)。其中植被表和全局文件可从官方示例获取模板,而土壤参数文件、植被参数文件和气象强迫数据需根据研究区域定制生成。
| 文件类型 | 描述 | 制备方式 | 代码工具 |
|---|---|---|---|
| 基本数据 | 网格、地形、降水等 | 需自定义制备 | create_grid.py get_elevation.py calculate_climatology.sh get_precipitation.py |
| 土壤参数 | soil_param.txt | 需自定义制备 | get_soil.py calculate_soil_water.py create_soil_param.py |
| 植被参数 | veg_param.txt | 需自定义制备 | process_modis.py create_veg_param.py |
| 植被表 | veg_lib.txt | 可使用官方模板 | |
| 气象强迫数据 | forcing_[lat]_[lon] | 需自定义制备 | get_forcing.sh create_forcing.py |
| 全局文件 | global_param.txt | 可使用官方模板 |
1. 创建VIC网格
首先确定研究区域边界,提供相应的Shapefile文件 (.shp)。本教程以长江下游流域为例,基于研究区域边界和设定的空间分辨率 (如0.1°×0.1°) 生成模拟网格。下面代码生成的grid_coordinates.csv文件包含各网格中心点经纬度,后续所有数据都将对齐至这些坐标点:
##########################
# create_grid.py
##########################
import geopandas as gpd
import pandas as pd
import numpy as np
from shapely.geometry import box
import matplotlib.pyplot as plt
import os
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体
plt.rcParams['font.family']=['Times New Roman','SimSun']
plt.rcParams['axes.unicode_minus'] = False
def create_vic_grid(boundary_file, output_dir, grid_resolution):
"""
为VIC模型创建规则网格系统
参数:
boundary_file: 研究区域边界文件路径 (Shapefile)
output_dir: 输出目录路径
grid_resolution: 网格分辨率 (度)
返回:
grid_data: 包含网格几何和中心坐标的数据GeoDataFrame
"""
print("=== VIC模型网格生成 ===")
# 1. 读取边界文件
print("1. 读取研究区域边界...")
boundary = gpd.read_file(boundary_file)
# 转换为WGS84坐标系
if boundary.crs != 'EPSG:4326':
boundary = boundary.to_crs('EPSG:4326')
print(" 已转换为WGS84坐标系")
# 计算网格参数
bounds = boundary.total_bounds
min_lon, min_lat, max_lon, max_lat = bounds
print(f" 研究区域范围: {min_lon:.4f}, {min_lat:.4f} - {max_lon:.4f}, {max_lat:.4f}")
print(f" 网格分辨率: {grid_resolution}度")
n_cols = int((max_lon - min_lon) / grid_resolution) + 1
n_rows = int((max_lat - min_lat) / grid_resolution) + 1
print(f" 网格尺寸: {n_cols}列 × {n_rows}行")
# 2. 生成完整网格
print("2. 生成网格系统...")
grid_polygons = []
grid_centers = []
grid_ids = []
grid_id = 0
for i in range(n_rows):
for j in range(n_cols):
# 计算网格边界
left = min_lon + j * grid_resolution
right = left + grid_resolution
bottom = min_lat + i * grid_resolution
top = bottom + grid_resolution
# 创建网格多边形和中心点
polygon = box(left, bottom, right, top)
center_lon = (left + right) / 2
center_lat = (bottom + top) / 2
grid_polygons.append(polygon)
grid_centers.append((center_lon, center_lat))
grid_ids.append(grid_id)
grid_id += 1
# 创建完整网格数据框
full_grid = gpd.GeoDataFrame({
'grid_id': grid_ids,
'geometry': grid_polygons,
'lon_center': [p[0] for p in grid_centers],
'lat_center': [p[1] for p in grid_centers]
}, crs='EPSG:4326')
# 3. 裁剪到研究区域
print("3. 裁剪网格到研究区域...")
clipped_grid = gpd.sjoin(full_grid, boundary, how='inner', predicate='intersects')
grid_data = clipped_grid[['grid_id', 'geometry', 'lon_center', 'lat_center']]
print(f" 完整网格数: {len(full_grid)}")
print(f" 研究区域内网格数: {len(clipped_grid)}")
# 4. 检查并处理重复网格
print("4. 检查数据完整性...")
duplicate_count = grid_data.duplicated(subset=['grid_id']).sum()
if duplicate_count > 0:
print(f" 发现 {duplicate_count} 个重复网格ID,进行去重处理")
grid_data = grid_data.drop_duplicates(subset=['grid_id'], keep='first')
print(f" 去重后网格数: {len(grid_data)}")
else:
print(" 网格ID唯一性检查通过")
# 5. 保存结果文件
print("5. 保存输出文件...")
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
# 保存网格坐标CSV
grid_csv = f"{output_dir}/grid_coordinates.csv"
grid_data[['grid_id', 'lon_center', 'lat_center']].to_csv(grid_csv, index=False)
print(f" 网格坐标文件: {grid_csv}")
# 保存VIC格式网格信息
vic_info = f"{output_dir}/vic_grid_info.txt"
with open(vic_info, 'w') as f:
f.write("# VIC模型网格信息\n")
f.write("# grid_id lat lon\n")
for _, row in grid_data.iterrows():
f.write(f"{row['grid_id']} {row['lat_center']:.6f} {row['lon_center']:.6f}\n")
print(f" VIC网格信息: {vic_info}")
# 6. 生成可视化
print("6. 生成可视化图表...")
fig, ax = plt.subplots(figsize=(12, 8))
# 绘制研究区域边界
boundary.boundary.plot(ax=ax, color='red', linewidth=2, label='研究区域')
# 绘制网格
grid_data.boundary.plot(ax=ax, color='blue', linewidth=0.5, alpha=0.7, label='VIC网格')
# 绘制网格中心点
ax.scatter(grid_data['lon_center'], grid_data['lat_center'],
color='green', s=10, alpha=0.5, label='网格中心')
ax.set_title(f'VIC模型网格系统 ({len(grid_data)}个网格)', fontsize=14)
ax.set_xlabel('经度', fontsize=12)
ax.set_ylabel('纬度', fontsize=12)
ax.legend()
ax.grid(True, alpha=0.3)
# 保存图片
vis_file = f"{output_dir}/grid_visualization.png"
plt.tight_layout()
plt.savefig(vis_file, dpi=300, bbox_inches='tight')
print(f" 可视化文件: {vis_file}")
plt.close()
print("\n=== 网格生成完成 ===")
print(f"成功创建 {len(grid_data)} 个网格单元")
return grid_data
# 完整使用流程示例
if __name__ == "__main__":
# 参数设置
boundary_file = "Lower_YRB.shp" # 研究区域边界文件
output_dir = "./vic_grid" # 输出目录
grid_resolution = 0.1 # 网格分辨率 (度)
# 执行网格生成
grid_data = create_vic_grid(
boundary_file=boundary_file,
output_dir=output_dir,
grid_resolution=grid_resolution
)
# 输出结果摘要
print(f"\n输出文件:")
print(f" - 网格坐标文件: {output_dir}/grid_coordinates.csv")
print(f" - VIC网格信息: {output_dir}/vic_grid_info.txt")
print(f" - 可视化图表: {output_dir}/grid_visualization.png")
# 显示前几个网格信息
print(f"\n前5个网格信息:")
print(grid_data[['grid_id', 'lon_center', 'lat_center']].head())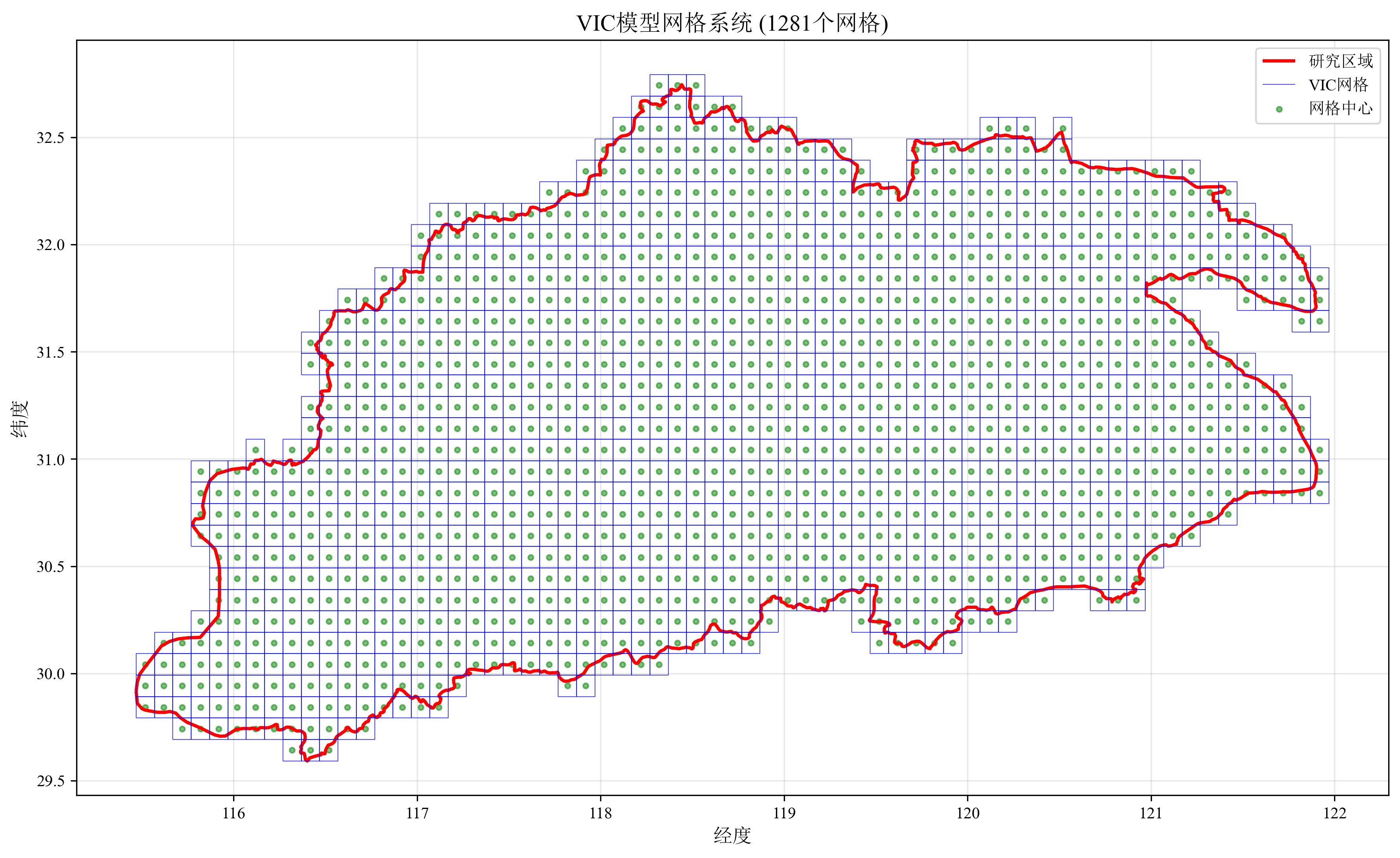
2. 制备地形数据
地形数据为VIC模型提供高程信息,影响产汇流过程和温度垂直梯度。本教程使用欧空局Copernicus GLO-90数字高程模型栅格数据 (.tif),下载时需确保覆盖整个研究区域。基于网格坐标提取各网格平均海拔高程,结果保存至grid_elevation.csv:
##########################
# get_elevation.py
##########################
import geopandas as gpd
import numpy as np
import pandas as pd
import rasterio
from shapely.geometry import Point, box
import matplotlib.pyplot as plt
import os
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体
plt.rcParams['font.family']=['Times New Roman','SimSun']
plt.rcParams['axes.unicode_minus'] = False
def extract_elevation_to_grid(dem_file, grid_coords_file, output_dir, grid_resolution=None):
"""
从DEM数据提取网格点高程
参数:
dem_file: DEM栅格文件路径
grid_coords_file: 网格坐标文件路径 (CSV格式)
output_dir: 输出目录路径
grid_resolution: 网格分辨率 (度), 如果为None则自动计算
返回:
elevation_df: 高程数据DataFrame
"""
print("=== 高程数据提取 ===")
# 1. 检查输入文件
print("1. 检查输入文件...")
if not os.path.exists(dem_file):
print(f"错误: DEM栅格文件不存在: {dem_file}")
return None
if not os.path.exists(grid_coords_file):
print(f"错误: 网格坐标文件不存在: {grid_coords_file}")
return None
# 2. 读取网格坐标数据
print("2. 读取网格坐标...")
grid_coords = pd.read_csv(grid_coords_file)
lons = grid_coords['lon_center']
lats = grid_coords['lat_center']
print(f" 网格点数量: {len(grid_coords)}")
print(f" 经度范围: {lons.min():.3f} ~ {lons.max():.3f}")
print(f" 纬度范围: {lats.min():.3f} ~ {lats.max():.3f}")
# 处理网格大小
if grid_resolution is None:
if len(lons) > 1:
# 使用经度差自动计算网格大小 (如果未提供)
grid_resolution = abs(lons[1] - lons[0])
print(f" 自动计算的空间分辨率: {grid_resolution:.6f} 度")
else:
# 如果只有一个网格,使用默认值
grid_resolution = 0.1
print(f" 警告: 只有一个网格,使用默认分辨率: {grid_resolution} 度")
else:
print(f" 使用指定的空间分辨率: {grid_resolution:.3f} 度")
# 创建网格多边形
polygons = []
for idx, row in grid_coords.iterrows():
lon, lat = row['lon_center'], row['lat_center']
half_res = grid_resolution / 2
polygon = box(lon - half_res, lat - half_res,
lon + half_res, lat + half_res)
polygons.append(polygon)
grid_gdf = gpd.GeoDataFrame(
grid_coords,
geometry=polygons,
crs='EPSG:4326'
)
# 3. 读取DEM数据
print("3. 读取DEM数据...")
with rasterio.open(dem_file) as src:
dem_crs = src.crs
dem_transform = src.transform
dem_data = src.read(1)
dem_nodata = src.nodata if src.nodata is not None else -9999
print(f" DEM范围: {src.bounds}")
print(f" DEM分辨率: {src.res}")
print(f" DEM坐标系: {src.crs}")
# 4. 提取网格点高程
print("4. 提取高程值...")
# 创建点几何对象并转换坐标系
points = [Point(lon, lat) for lon, lat in zip(grid_gdf['lon_center'], grid_gdf['lat_center'])]
points_gdf = gpd.GeoDataFrame(grid_gdf, geometry=points, crs='EPSG:4326')
points_gdf_proj = points_gdf.to_crs(dem_crs)
elevations = []
valid_count = 0
for idx, row in points_gdf_proj.iterrows():
x, y = row.geometry.x, row.geometry.y
# 地理坐标转像素坐标
col, row_idx = ~dem_transform * (x, y)
col, row_idx = int(col), int(row_idx)
# 检查坐标有效性并提取高程
if 0 <= row_idx < dem_data.shape[0] and 0 <= col < dem_data.shape[1]:
elevation = dem_data[row_idx, col]
if elevation != dem_nodata and not np.isnan(elevation):
elevations.append(elevation)
valid_count += 1
else:
elevations.append(np.nan)
else:
elevations.append(np.nan)
grid_gdf['elevation'] = elevations
missing_count = len(grid_gdf) - valid_count
print(f" 成功提取 {valid_count} 个点的高程数据")
print(f" 缺失高程数据: {missing_count} 个点")
# 5. 保存结果
print("5. 保存结果...")
os.makedirs(output_dir, exist_ok=True)
# 保存高程数据CSV文件
output_csv = f"{output_dir}/grid_elevation.csv"
elevation_df = grid_gdf[['grid_id', 'lon_center', 'lat_center', 'elevation']]
elevation_df.to_csv(output_csv, index=False)
print(f" 高程数据文件: {output_csv}")
# 6. 生成可视化
print("6. 生成可视化图表...")
fig, ax = plt.subplots(figsize=(10, 8))
# 使用geopandas的plot方法
valid_data = grid_gdf[~grid_gdf['elevation'].isna()]
valid_data.plot(column='elevation', ax=ax, legend=True,
cmap='terrain',marker='s',
legend_kwds={'label': '高程 (m)'})
ax.set_title('网格高程分布', fontsize=14)
ax.set_xlabel('经度', fontsize=12)
ax.set_ylabel('纬度', fontsize=12)
ax.grid(True, alpha=0.3)
plt.tight_layout()
vis_file = f"{output_dir}/elevation_visualization.png"
plt.savefig(vis_file, dpi=300, bbox_inches='tight')
print(f" 可视化文件: {vis_file}")
plt.close()
# 7. 输出详细的统计信息
print("\n=== 高程统计 ===")
valid_elevations = grid_gdf['elevation'].dropna()
if len(valid_elevations) > 0:
print(f" 最小值: {valid_elevations.min():.1f} m")
print(f" 最大值: {valid_elevations.max():.1f} m")
print(f" 平均值: {valid_elevations.mean():.1f} m")
print(f" 标准差: {valid_elevations.std():.1f} m")
print("\n=== 高程数据提取完成 ===")
return elevation_df
# 完整使用流程示例
if __name__ == "__main__":
# 参数设置
dem_file = "output_hh.tif" # DEM文件路径
grid_coords_file = "../grid/vic_grid/grid_coordinates.csv" # 网格坐标文件
output_dir = "./elevation_data" # 输出目录
grid_resolution = 0.1 # VIC网格分辨率
# 执行高程提取
elevation_df = extract_elevation_to_grid(
dem_file=dem_file,
grid_coords_file=grid_coords_file,
output_dir=output_dir,
grid_resolution=grid_resolution
)
# 输出结果摘要
print(f"\n 输出文件:")
print(f" - 高程数据: {output_dir}/grid_elevation.csv")
print(f" - 可视化图表: {output_dir}/elevation_visualization.png")
# 显示前几个网格的高程信息
print(f"\n 前5个网格高程:")
print(elevation_df.head())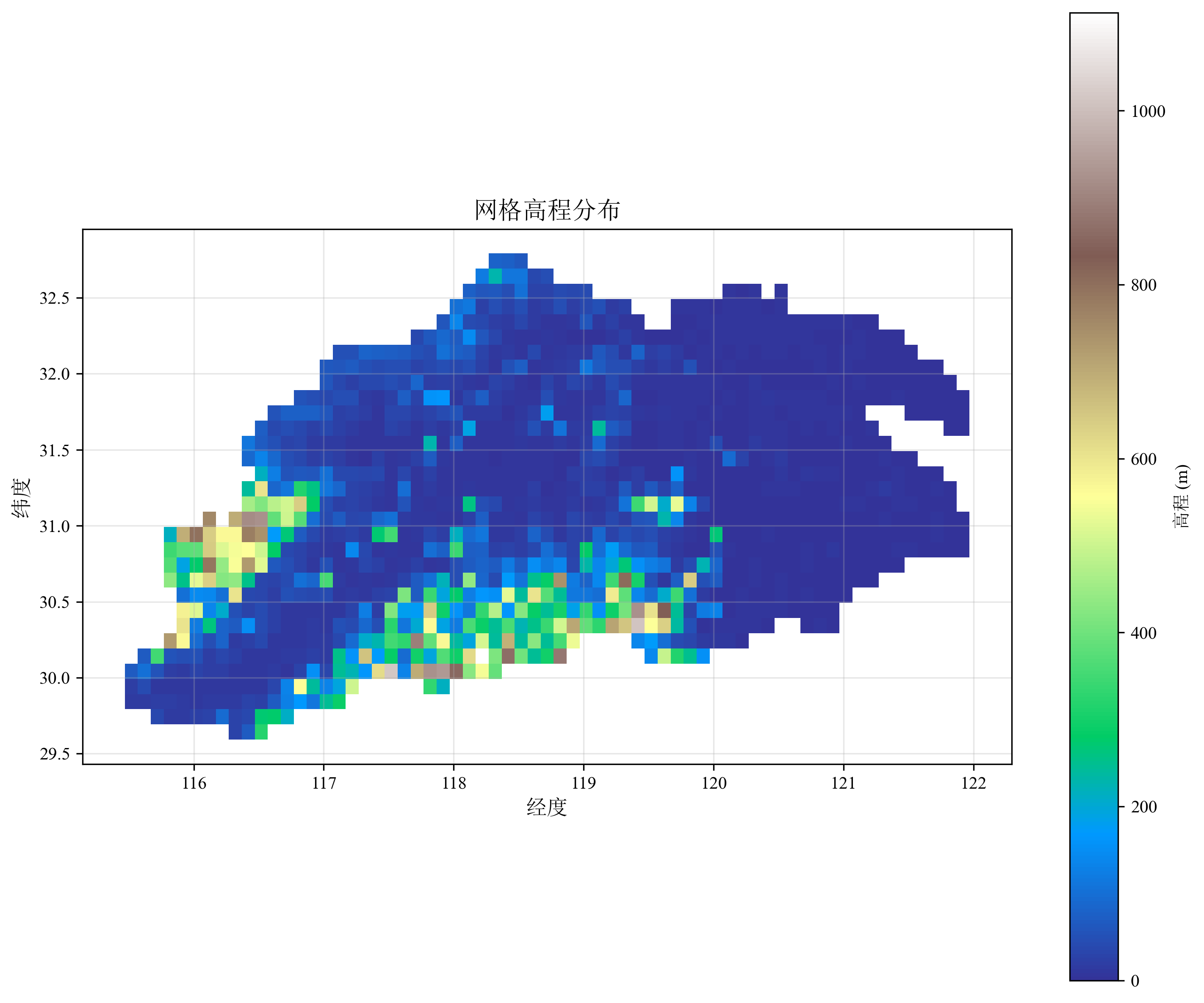
3. 制备气候态降水数据
气候态降水数据用于计算土壤参数中的年降水量项。本教程使用NASA MERRA-2降水NetCDF数据 (.nc),建议下载至少30年数据以保证气候代表性。注意单位转换:若原始数据为降水率 (kg m⁻² s⁻¹),需转换为年降水量 (mm/year)。下面CDO指令可以快速实现单位转换:
cdo --reduce_dim -setattribute,PRECTOT@units="mm/year" -expr,'PRECTOT = PRECTOT * 86400 *365' -timavg -mergetime MERRA/MERRA2_*.tavgM_2d_flx_Nx.*.nc4.nc4 precipitation_data/precip_climatology.nc下面代码提取各网格平均降水值,保存至grid_precipitation.csv:
##########################
# get_precipitation.py
##########################
import geopandas as gpd
import xarray as xr
import numpy as np
import pandas as pd
from shapely.geometry import Point, box
import matplotlib.pyplot as plt
import os
from scipy.interpolate import griddata
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体
plt.rcParams['font.family']=['Times New Roman','SimSun']
plt.rcParams['axes.unicode_minus'] = False
def extract_precipitation_to_grid(precip_file, grid_coords_file, output_dir, precip_variable_name, grid_resolution=None):
"""
从降水气候态文件中提取降水数据到网格点
参数:
precip_file: 降水气候态NetCDF文件路径
grid_coords_file: 网格坐标文件路径 (CSV格式)
output_dir: 输出目录路径
precip_variable_name: NetCDF中的降水变量名
grid_resolution: 网格分辨率 (度), 如果为None则自动计算
返回:
precip_df: 降水数据DataFrame
"""
print("=== 提取降水数据到网格点 ===")
# 1. 检查输入文件
print("1. 检查输入文件...")
if not os.path.exists(precip_file):
print(f"错误: 降水气候态NetCDF文件不存在: {precip_file}")
return None
if not os.path.exists(grid_coords_file):
print(f"错误: 网格坐标文件不存在: {grid_coords_file}")
return None
# 2. 读取网格坐标数据
print("2. 读取网格坐标...")
grid_coords = pd.read_csv(grid_coords_file)
lons = grid_coords['lon_center']
lats = grid_coords['lat_center']
print(f" 网格点数量: {len(grid_coords)}")
print(f" 经度范围: {lons.min():.3f} ~ {lons.max():.3f}")
print(f" 纬度范围: {lats.min():.3f} ~ {lats.max():.3f}")
# 处理网格大小
if grid_resolution is None:
if len(lons) > 1:
# 使用经度差自动计算网格大小 (如果未提供)
grid_resolution = abs(lons[1] - lons[0])
print(f" 自动计算的空间分辨率: {grid_resolution:.6f} 度")
else:
# 如果只有一个网格,使用默认值
grid_resolution = 0.1
print(f" 警告: 只有一个网格,使用默认分辨率: {grid_resolution} 度")
else:
print(f" 使用指定的空间分辨率: {grid_resolution:.3f} 度")
# 创建网格多边形
polygons = []
for idx, row in grid_coords.iterrows():
lon, lat = row['lon_center'], row['lat_center']
half_res = grid_resolution / 2
polygon = box(lon - half_res, lat - half_res,
lon + half_res, lat + half_res)
polygons.append(polygon)
grid_gdf = gpd.GeoDataFrame(
grid_coords,
geometry=polygons,
crs='EPSG:4326'
)
# 3. 读取降水气候态数据
print("3. 读取降水气候态数据...")
try:
ds = xr.open_dataset(precip_file)
# 检查变量名
if precip_variable_name not in ds.variables:
available_vars = list(ds.variables.keys())
print(f"变量 '{precip_variable_name}' 不存在")
print(f" 可用变量: {available_vars}")
# 尝试使用第一个数据变量
data_vars = [var for var in available_vars if len(ds[var].shape) >= 2]
if data_vars:
precip_variable_name = data_vars[0]
print(f" 使用变量: {precip_variable_name}")
else:
raise KeyError("未找到合适的数据变量")
precip_data = ds[precip_variable_name]
# 获取坐标信息
coord_mapping = {
'longitude': ['longitude', 'lon', 'x'],
'latitude': ['latitude', 'lat', 'y']
}
lons, lats = None, None
for std_name, possible_names in coord_mapping.items():
for name in possible_names:
if name in ds.coords:
if std_name == 'longitude':
lons = ds[name].values
else:
lats = ds[name].values
break
if lons is None or lats is None:
# 从数据维度推断
dims = precip_data.dims
if len(dims) >= 2:
lons = ds[dims[-1]].values if dims[-1] in ds.coords else None
lats = ds[dims[-2]].values if dims[-2] in ds.coords else None
if lons is None or lats is None:
raise ValueError("无法确定经纬度坐标")
print(f" 数据维度: {precip_data.dims}")
print(f" 数据形状: {precip_data.shape}")
print(f" 经度范围: {lons.min():.2f} ~ {lons.max():.2f}")
print(f" 纬度范围: {lats.min():.2f} ~ {lats.max():.2f}")
print(f" 降水范围: {precip_data.min().values:.1f} ~ {precip_data.max().values:.1f} mm/year")
print(f" 数据单位: {precip_data.attrs.get('units', '未知')}")
# 获取数据值
precip_values = precip_data.values
# 处理二维网格数据
if len(precip_values.shape) == 2:
lon_grid, lat_grid = np.meshgrid(lons, lats)
points_2d_source = np.column_stack([lon_grid.ravel(), lat_grid.ravel()])
values_source = precip_values.ravel()
else:
raise ValueError(f"不支持的降水数据维度: {precip_values.shape}")
ds.close()
except Exception as e:
print(f"读取降水数据失败: {e}")
return None
# 4. 插值气候态降水到网格点
print("4. 插值到网格点...")
target_points = np.column_stack([grid_gdf['lon_center'], grid_gdf['lat_center']])
precip_interpolated = griddata(
points_2d_source,
values_source,
target_points,
method='linear',
fill_value=np.nan
)
grid_gdf['precipitation'] = precip_interpolated
valid_count = np.sum(~np.isnan(precip_interpolated))
missing_count = len(grid_gdf) - valid_count
print(f" 成功插值 {valid_count} 个网格点")
print(f" 缺失气候态降水数据: {missing_count} 个点")
if missing_count > 0:
print(" 注意: 部分网格点位于降水数据范围之外")
# 5. 保存结果
print("5. 保存结果...")
os.makedirs(output_dir, exist_ok=True)
# 保存降水数据CSV文件
output_csv = f"{output_dir}/grid_precipitation.csv"
precip_df = grid_gdf[['grid_id', 'lon_center', 'lat_center', 'precipitation']]
precip_df.to_csv(output_csv, index=False)
print(f" 降水数据文件: {output_csv}")
# 6. 生成可视化
print("6. 生成可视化图表...")
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
# 子图1: 网格降水分布
valid_data = grid_gdf[~grid_gdf['precipitation'].isna()]
valid_data.plot(column='precipitation', ax=ax1, legend=True,
cmap='Blues',marker='s',
legend_kwds={'label': '年降水量 (mm/year)'})
ax1.set_title('网格降水分布', fontsize=14)
ax1.set_xlabel('经度', fontsize=12)
ax1.set_ylabel('纬度', fontsize=12)
ax1.grid(True, alpha=0.3)
# 子图2: 降水统计直方图
valid_precip = grid_gdf['precipitation'].dropna()
ax2.hist(valid_precip, bins=30, color='skyblue', edgecolor='black', alpha=0.7)
ax2.axvline(valid_precip.mean(), color='red', linestyle='--', linewidth=2,
label=f'平均值: {valid_precip.mean():.1f} mm/year')
ax2.set_title('降水值分布', fontsize=14)
ax2.set_xlabel('年降水量 (mm/year)', fontsize=12)
ax2.set_ylabel('频数', fontsize=12)
ax2.legend()
ax2.grid(True, alpha=0.3)
plt.tight_layout()
vis_file = f"{output_dir}/precipitation_visualization.png"
plt.savefig(vis_file, dpi=300, bbox_inches='tight')
print(f" 可视化文件: {vis_file}")
plt.close()
# 7. 输出详细的统计信息
print("\n=== 降水统计 ===")
if len(valid_precip) > 0:
print(f" 最小值: {valid_precip.min():.1f} mm/year")
print(f" 最大值: {valid_precip.max():.1f} mm/year")
print(f" 平均值: {valid_precip.mean():.1f} mm/year")
print(f" 标准差: {valid_precip.std():.1f} mm/year")
print(f" 中位数: {valid_precip.median():.1f} mm/year")
print(f" 缺失率: {missing_count/len(grid_gdf)*100:.1f}%")
# 空间分布统计
print(f" 空间分布:")
print(f" - 最高降水区域: {grid_gdf.loc[grid_gdf['precipitation'].idxmax(), ['lon_center', 'lat_center']].values}")
print(f" - 最低降水区域: {grid_gdf.loc[grid_gdf['precipitation'].idxmin(), ['lon_center', 'lat_center']].values}")
else:
print(" 无有效降水数据")
print("\n=== 降水数据提取完成 ===")
return precip_df
# 完整使用流程示例
if __name__ == "__main__":
# 参数设置
precip_file = "./precipitation_data/precip_climatology.nc" # 降水气候态文件
grid_coords_file = "../grid/vic_grid/grid_coordinates.csv" # 网格坐标文件
output_dir = "./precipitation_data" # 输出目录
precip_variable_name = "PRECTOT" # 降水变量名
grid_resolution = 0.1 # VIC网格分辨率
# 执行降水提取
precip_df = extract_precipitation_to_grid(
precip_file=precip_file,
grid_coords_file=grid_coords_file,
output_dir=output_dir,
precip_variable_name=precip_variable_name,
grid_resolution=grid_resolution
)
# 输出结果摘要
print(f"\n输出文件:")
print(f" - 降水数据: {output_dir}/grid_precipitation.csv")
print(f" - 可视化图表: {output_dir}/precipitation_visualization.png")
# 显示前几个网格的降水信息
print(f"\n前5个网格降水:")
print(precip_df.head())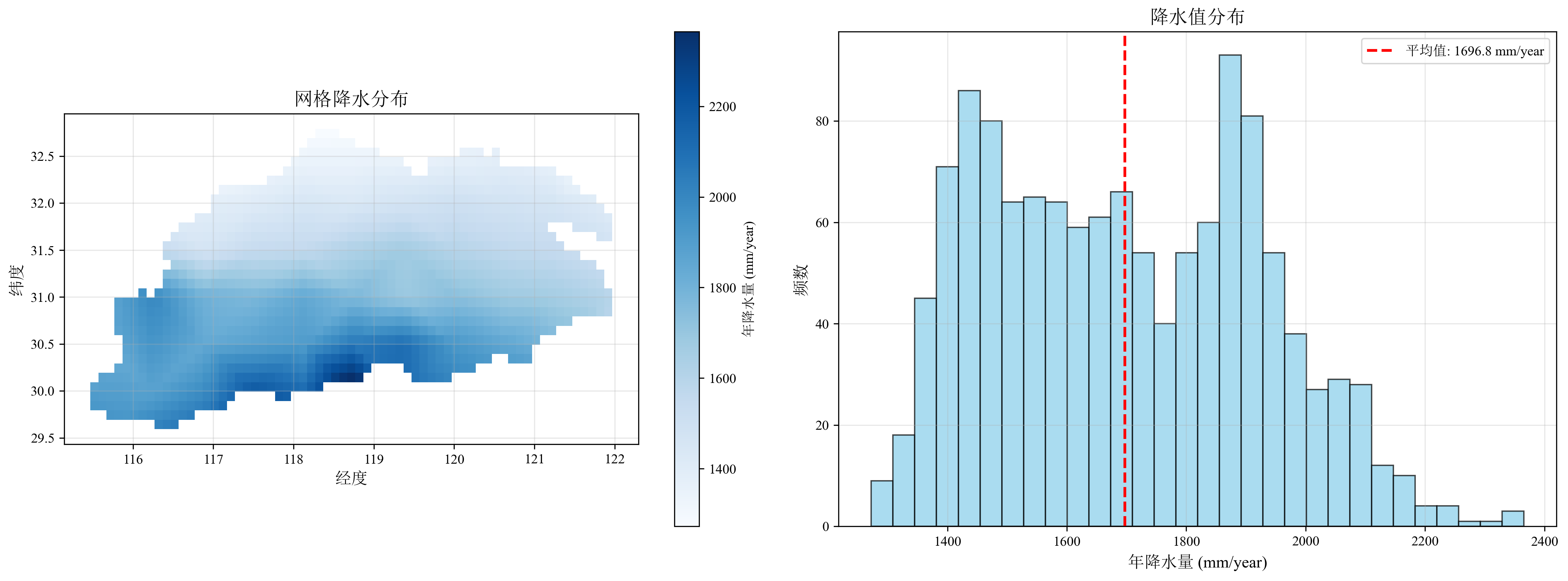
4. 制备土壤参数
土壤参数是VIC模型最复杂的部分。本教程使用联合国粮农组织HWSD土壤数据,包括栅格数据 (hwsd.bil)和属性数据库 (HWSD.mdb)。栅格文件配套的hwsd.blw和hwsd.hdr分别定义地理参考和头文件信息。
若无Microsoft Access,可通过Excel导入HWSD.mdb中的HWSD_DATA表并保存为CSV格式 (数据选项卡 > 自Access > 打开HWSD.mdb > 选择HWSD_DATA > 保存)。
下面代码基于网格坐标提取主导土壤类型:
##########################
# get_soil.py
##########################
import geopandas as gpd
import rasterio
import pandas as pd
import numpy as np
from rasterio.mask import mask
from rasterstats import zonal_stats
import matplotlib.pyplot as plt
from shapely.geometry import Point, box
import os
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体
plt.rcParams['font.family']=['Times New Roman','SimSun']
plt.rcParams['axes.unicode_minus'] = False
def extract_soil_to_grid(hwsd_raster, hwsd_csv, grid_coords_file, output_dir, grid_resolution=0.1):
"""
从HWSD中提取土壤数据到网格点 - 使用Excel导出的CSV文件
参数:
hwsd_raster: HWSD栅格文件路径 (hwsd.bil)
hwsd_csv: 从Excel导出的HWSD_DATA.csv文件路径
grid_coords_file: 网格坐标文件路径 (CSV格式)
output_dir: 输出目录
grid_resolution: 网格分辨率 (度), 如果为None则自动计算
返回:
soil_df: 土壤数据DataFrame
"""
print("=== HWSD土壤数据提取 (Excel CSV版本) ===")
# 1. 检查输入文件
print("1. 检查输入文件...")
if not os.path.exists(hwsd_csv):
print(f"错误: HWSD CSV文件不存在: {hwsd_csv}")
print("请先用Excel导出HWSD_DATA表为CSV格式")
return None
if not os.path.exists(hwsd_raster):
print(f"错误: HWSD栅格文件不存在: {hwsd_raster}")
return None
if not os.path.exists(grid_coords_file):
print(f"错误: 网格坐标文件不存在: {grid_coords_file}")
return None
# 2. 读取网格坐标数据
print("2. 读取网格坐标...")
grid_coords = pd.read_csv(grid_coords_file)
lons = grid_coords['lon_center']
lats = grid_coords['lat_center']
print(f" 网格点数量: {len(grid_coords)}")
print(f" 经度范围: {lons.min():.3f} ~ {lons.max():.3f}")
print(f" 纬度范围: {lats.min():.3f} ~ {lats.max():.3f}")
# 处理网格大小
if grid_resolution is None:
if len(lons) > 1:
# 使用经度差自动计算网格大小 (如果未提供)
grid_resolution = abs(lons[1] - lons[0])
print(f" 自动计算的空间分辨率: {grid_resolution:.6f} 度")
else:
# 如果只有一个网格,使用默认值
grid_resolution = 0.1
print(f" 警告: 只有一个网格,使用默认分辨率: {grid_resolution} 度")
else:
print(f" 使用指定的空间分辨率: {grid_resolution:.3f} 度")
# 创建网格多边形
polygons = []
for idx, row in grid_coords.iterrows():
lon, lat = row['lon_center'], row['lat_center']
half_res = grid_resolution / 2
polygon = box(lon - half_res, lat - half_res,
lon + half_res, lat + half_res)
polygons.append(polygon)
grid_gdf = gpd.GeoDataFrame(
grid_coords,
geometry=polygons,
crs='EPSG:4326'
)
# 3. 读取HWSD CSV数据
print("3. 读取HWSD CSV数据...")
hwsd_data = pd.read_csv(hwsd_csv)
print(f"HWSD数据记录数: {len(hwsd_data)}")
print(f"HWSD数据列: {list(hwsd_data.columns)}")
# 4. 计算每个网格的主导土壤类型
print("4. 计算主导土壤类型...")
with rasterio.open(hwsd_raster) as src:
print(f"HWSD栅格范围: {src.bounds}")
print(f"HWSD栅格尺寸: {src.width} x {src.height}")
# 使用rasterstats计算众数
stats = zonal_stats(
grid_gdf,
hwsd_raster,
stats=['majority'],
categorical=True,
nodata=src.nodata if src.nodata else -9999
)
majority_values = [stat.get('majority', np.nan) for stat in stats]
grid_gdf['MU_GLOBAL'] = majority_values
valid_count = sum(~pd.isna(majority_values))
print(f"成功计算 {valid_count} 个网格的主导土壤类型")
print(f"缺失土壤数据: {len(grid_gdf) - valid_count} 个网格")
# 5. 连接土壤属性数据
print("5. 连接土壤属性...")
# 确保MU_GLOBAL类型一致
grid_gdf['MU_GLOBAL'] = pd.to_numeric(grid_gdf['MU_GLOBAL'], errors='coerce')
hwsd_data['MU_GLOBAL'] = pd.to_numeric(hwsd_data['MU_GLOBAL'], errors='coerce')
# 执行连接
merged_gdf = grid_gdf.merge(
hwsd_data,
on='MU_GLOBAL',
how='left',
suffixes=('', '_hwsd')
)
connection_rate = (sum(~merged_gdf['MU_GLOBAL'].isna()) / len(merged_gdf)) * 100
print(f"土壤属性连接成功率: {connection_rate:.1f}%")
# 6. 保存结果
print("6. 保存结果...")
os.makedirs(output_dir, exist_ok=True)
# 保存土壤参数CSV文件
output_csv = f"{output_dir}/grid_soil.csv"
# 定义VIC模型需要的关键土壤参数
vic_soil_parameters = [
'grid_id', 'lon_center', 'lat_center', 'MU_GLOBAL',
# 表层土壤参数 (Topsoil)
'T_SAND', 'T_CLAY', 'T_SILT', 'T_OC',
'T_GRAVEL', 'T_REF_BULK_DENSITY', 'T_ECE',
# 底层土壤参数 (Subsoil)
'S_SAND', 'S_CLAY', 'S_SILT', 'S_OC',
'S_GRAVEL', 'S_REF_BULK_DENSITY', 'S_ECE'
]
# 只选择存在的列
available_columns = [col for col in vic_soil_parameters if col in merged_gdf.columns]
# 保存精简的CSV文件
soil_df = merged_gdf[available_columns]
soil_df.to_csv(output_csv, index=False, float_format='%.4f')
print(f"土壤参数文件: {output_csv}")
# 7. 生成可视化
print("7. 生成可视化...")
# 创建2行2列的子图布局
fig, axes = plt.subplots(2, 2, figsize=(18, 12))
# 子图1: 主导土壤类型分布
valid_data = merged_gdf[~merged_gdf['MU_GLOBAL'].isna()]
# 将土壤类型转换为整数
valid_data['MU_GLOBAL_int'] = valid_data['MU_GLOBAL'].astype(int)
valid_data.plot(column='MU_GLOBAL_int', ax=axes[0,0], legend=False, # 如果土壤类型太多可关闭图例
cmap='tab20', categorical=True,
legend_kwds={'title': '土壤类型'})
axes[0,0].set_title('主导土壤类型分布', fontsize=14)
axes[0,0].set_xlabel('经度', fontsize=12)
axes[0,0].set_ylabel('纬度', fontsize=12)
axes[0,0].grid(True, alpha=0.3)
# 子图位置微调
current_pos = axes[0,0].get_position()
axes[0,0].set_position([current_pos.x0-0.03, current_pos.y0, current_pos.width*0.97, current_pos.height*0.97])
# 子图2: 表层砂粒含量分布
valid_sand = merged_gdf[~merged_gdf['T_SAND'].isna()]
valid_sand.plot(column='T_SAND', ax=axes[0,1], legend=True,
cmap='OrRd',
legend_kwds={'label': '砂粒含量 (%)'})
axes[0,1].set_title('表层砂粒含量', fontsize=14)
axes[0,1].set_xlabel('经度', fontsize=12)
axes[0,1].set_ylabel('纬度', fontsize=12)
axes[0,1].grid(True, alpha=0.3)
# 子图3: 表层粘粒含量
valid_clay = merged_gdf[~merged_gdf['T_CLAY'].isna()]
valid_clay.plot(column='T_CLAY', ax=axes[1,0], legend=True,
cmap='YlGn',
legend_kwds={'label': '粘粒含量 (%)'})
axes[1,0].set_title('表层粘粒含量', fontsize=14)
axes[1,0].set_xlabel('经度', fontsize=12)
axes[1,0].set_ylabel('纬度', fontsize=12)
axes[1,0].grid(True, alpha=0.3)
# 子图4: 表层有机碳含量
valid_oc = merged_gdf[~merged_gdf['T_OC'].isna()]
valid_oc.plot(column='T_OC', ax=axes[1,1], legend=True,
cmap='BuPu',
legend_kwds={'label': '有机碳含量 (%)'})
axes[1,1].set_title('表层有机碳含量', fontsize=14)
axes[1,1].set_xlabel('经度', fontsize=12)
axes[1,1].set_ylabel('纬度', fontsize=12)
axes[1,1].grid(True, alpha=0.3)
vis_file = f"{output_dir}/soil_visualization.png"
plt.savefig(vis_file, dpi=300, bbox_inches='tight')
print(f"可视化文件: {vis_file}")
plt.close()
# 8. 输出详细的统计信息
print("\n=== 土壤统计 ===")
# 主导土壤类型统计
if 'MU_GLOBAL' in merged_gdf.columns:
soil_types = merged_gdf['MU_GLOBAL'].value_counts()
print(f" 主导土壤类型数量: {len(soil_types)}")
print(f" 前5种主要土壤类型:")
for soil_type, count in soil_types.head().items():
print(f" MU_GLOBAL {int(soil_type)}: {count} 个网格 ({count/len(merged_gdf)*100:.1f}%)")
# 关键土壤参数统计
key_parameters = {
'T_SAND': '表层砂粒含量',
'T_CLAY': '表层粘粒含量',
'T_SILT': '表层粉粒含量',
'T_OC': '表层有机碳含量',
'T_GRAVEL': '表层砾石含量'
}
for param, desc in key_parameters.items():
if param in merged_gdf.columns:
valid_data = merged_gdf[param].dropna()
if len(valid_data) > 0:
print(f" {desc}: {valid_data.min():.1f}-{valid_data.max():.1f}% "
f"(平均: {valid_data.mean():.1f}%)")
print("\n=== 土壤数据提取完成 ===")
return soil_df
def check_soil_texture(soil_df):
"""
检查VIC模型所需的土壤参数完整性
"""
print("\n=== VIC模型土壤参数检查 ===")
# 检查VIC模型关键参数
required_params = ['T_SAND', 'T_CLAY', 'T_SILT', 'T_OC']
optional_params = ['T_GRAVEL', 'T_REF_BULK_DENSITY', 'S_SAND', 'S_CLAY', 'S_SILT']
print("关键参数检查:")
for param in required_params:
if param in soil_df.columns:
missing_rate = (soil_df[param].isna().sum() / len(soil_df)) * 100
print(f" {param}: {missing_rate:.1f}% 缺失")
else:
print(f" {param}: 列不存在!")
print("\n可选参数检查:")
for param in optional_params:
if param in soil_df.columns:
missing_rate = (soil_df[param].isna().sum() / len(soil_df)) * 100
print(f" {param}: {missing_rate:.1f}% 缺失")
else:
print(f" {param}: 列不存在")
# 检查土壤质地总和
if all(param in soil_df.columns for param in ['T_SAND', 'T_CLAY', 'T_SILT']):
valid_rows = soil_df[['T_SAND', 'T_CLAY', 'T_SILT']].dropna()
if len(valid_rows) > 0:
total = valid_rows['T_SAND'] + valid_rows['T_CLAY'] + valid_rows['T_SILT']
avg_total = total.mean()
print(f"\n土壤质地验证:")
print(f" 砂粒+粘粒+粉粒平均总和: {avg_total:.1f}%")
if abs(avg_total - 100) > 5:
print(f" 警告: 土壤质地总和偏离100%较多,可能需要检查数据")
# 完整使用流程示例
if __name__ == "__main__":
# 设置文件路径
hwsd_raster = "hwsd.bil" # HWSD栅格文件
hwsd_csv = "HWSD_DATA.csv" # 从Excel导出的CSV文件
grid_coords_file = "../grid/vic_grid/grid_coordinates.csv" # 网格坐标CSV
output_dir = "./soil_data" # 输出目录
grid_resolution = 0.1 # VIC网格分辨率
# 提取土壤数据
soil_df = extract_soil_to_grid(
hwsd_raster=hwsd_raster,
hwsd_csv=hwsd_csv,
grid_coords_file=grid_coords_file,
output_dir=output_dir,
grid_resolution=grid_resolution
)
# 输出结果摘要
print(f"\n输出文件:")
print(f" - 土壤数据: {output_dir}/grid_soil.csv")
print(f" - 可视化图表: {output_dir}/soil_visualization.png")
# 检查VIC模型参数完整性
check_soil_texture(soil_df)
# 显示前几个网格的土壤参数
print(f"\n前5个网格的土壤参数:")
print(soil_df.head())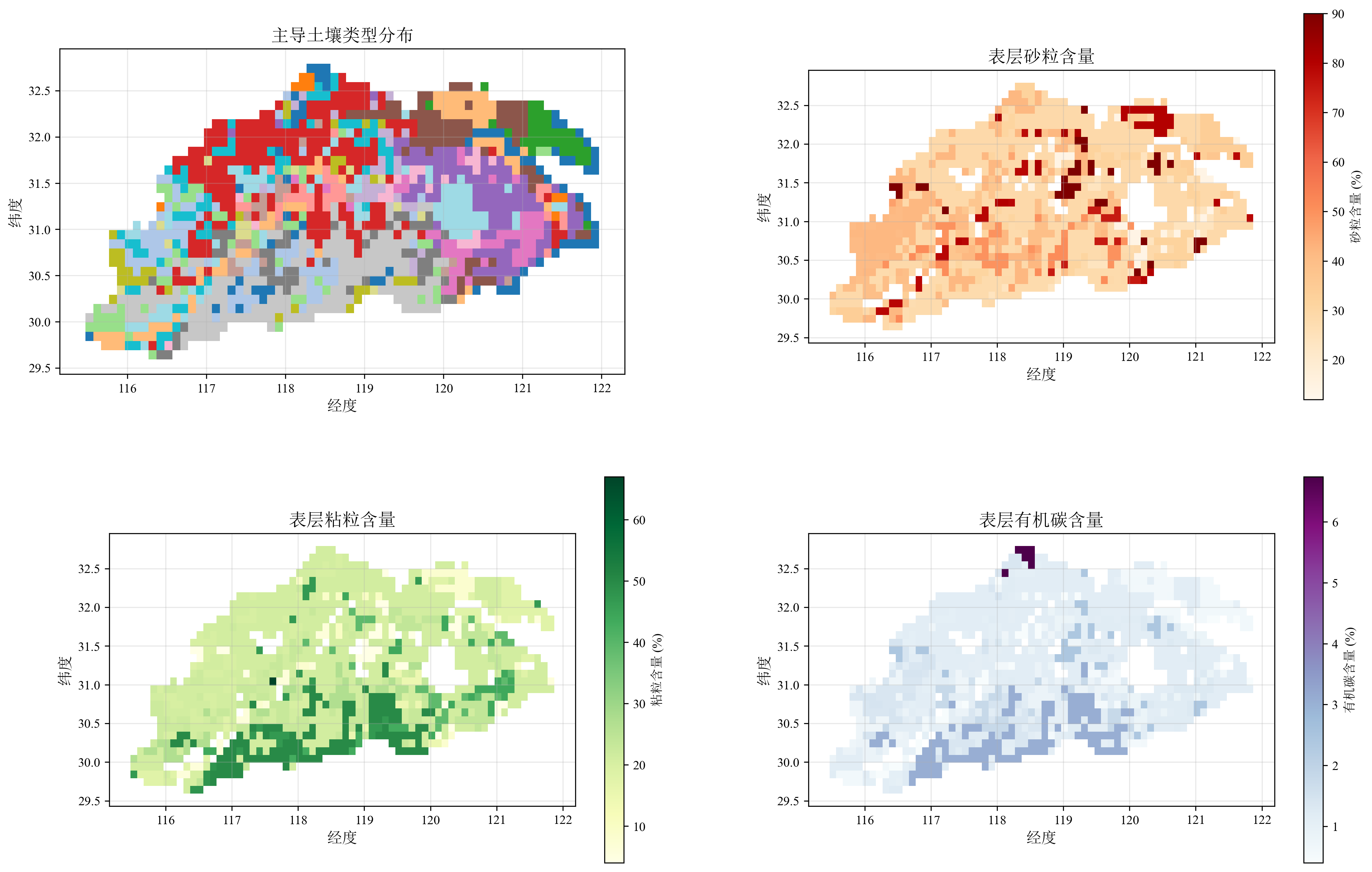
下面代码结合Saxton公式计算萎蔫点、田间持水量等水力参数:
##########################
# calculate_soil_water.py
##########################
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
def calculate_soil_water_characteristic(Sand, Clay, OrganicMatter, Salinity=0, Gravel=0, Compaction=1.0):
"""
基于 Saxton & Rawls (2006) 公式计算土壤水力参数
计算结果应与SPAW软件的输出一致
参数:
Sand: 砂粒含量,质量百分比 (0.1-99.9)
Clay: 粘粒含量,质量百分比 (0.1-99.9)
OrganicMatter: 有机质含量,质量百分比 (0.1-20)
Salinity: 盐度 (dS/m),默认值为 0
Gravel: 砾石含量,体积百分比 (0-80),默认值为 0
Compaction: 压实因子 (0.9-1.3),默认值为 1.0
返回:
soil_water_dict: 包含计算出的土壤水力参数的字典dict
"""
# 限制输入范围并转换单位
S = np.clip(Sand, 0.1, 99.9) / 100.0 # 转换为小数
C = np.clip(Clay, 0.1, 99.9) / 100.0 # 转换为小数
OM = np.clip(OrganicMatter, 0.1, 20) # 保持为百分比
R_v = np.clip(Gravel, 0, 80) / 100.0 # 转换为小数
DF = np.clip(Compaction, 0.9, 1.3) # 压实因子
# 1. 计算基本水分特征参数 (方程1-5)
# 萎蔫点 θ_1500 (方程1)
theta_1500t = (-0.024 * S + 0.487 * C + 0.006 * OM +
0.005 * (S * OM) - 0.013 * (C * OM) +
0.068 * (S * C) + 0.031)
theta_1500 = theta_1500t + (0.14 * theta_1500t - 0.02)
# 田间持水量 θ_33 (方程2)
theta_33t = (-0.251 * S + 0.195 * C + 0.011 * OM +
0.006 * (S * OM) - 0.027 * (C * OM) +
0.452 * (S * C) + 0.299)
theta_33 = theta_33t + (1.283 * theta_33t**2 - 0.374 * theta_33t - 0.015)
# 饱和-田间持水量差 θ_S-33 (方程3)
theta_S33t = (0.278 * S + 0.034 * C + 0.022 * OM -
0.018 * (S * OM) - 0.027 * (C * OM) -
0.584 * (S * C) + 0.078)
theta_S33 = theta_S33t + (0.636 * theta_S33t - 0.107)
# 饱和含水量 θ_S (方程5)
theta_S = theta_33 + theta_S33 - 0.097 * S + 0.043
# 2. 计算容重和密度效应 (方程6-10)
# 名义容重 (方程6)
bulk_density_normal = (1 - theta_S) * 2.65 # g/cm³
# 校正后的容重 (方程7)
bulk_density_DF = bulk_density_normal * DF # g/cm³
# 校正后的饱和含水量 (方程8)
theta_S_DF = 1 - (bulk_density_DF / 2.65) # 小数
# 校正后的田间持水量 (方程9)
theta_33_DF = theta_33 - 0.2 * (theta_S - theta_S_DF) # 小数
# 3. 计算进气吸力 ψ_e (方程4)
psi_et = (-21.67 * S - 27.93 * C - 81.97 * theta_S33 +
71.12 * (S * theta_S33) + 8.29 * (C * theta_S33) +
14.05 * (S * C) + 27.16)
psi_e = psi_et + (0.02 * psi_et**2 - 0.113 * psi_et - 0.70) # kPa
# 4. 计算饱和导水率 K_s (方程16, 15, 18)
# 计算 B 参数 (方程15)
B = (np.log(1500) - np.log(33)) / (np.log(theta_33_DF) - np.log(theta_1500))
lambda_val = 1 / B # 方程18
# 饱和导水率 (方程16)
K_s = 1930 * (theta_S_DF - theta_33_DF)**(3 - lambda_val) # mm/h
# 5. 应用砾石校正 (方程19-22)
alpha = bulk_density_DF / 2.65 # α = ρ_DF / 2.65
R_w = R_v/(R_v * (1 - alpha) + alpha) # 方程19变形
# 砾石校正后的容重 (方程20)
bulk_density_gravel = bulk_density_DF * (1 - R_v) + (R_v * 2.65) # g/cm³
# 砾石校正后的导水率 (方程22)
K_b_Ks = (1 - R_w) / (1 - R_w * (1 - 1.5 * alpha))
K_b = K_b_Ks * K_s # mm/h
# 6. 盐度校正 (方程23-24)
EC = Salinity # 电导率 dS/m
psi_o = 36 * EC # 方程23 - 饱和时的渗透势 (kPa)
# 7. 计算有效含水量
available_water = theta_33_DF - theta_1500 # 小数
soil_water_dict = {
'wilting_point': np.clip(theta_1500, 0.01, 0.5), # m³/m³
'field_capacity': np.clip(theta_33_DF, 0.05, 0.6), # m³/m³
'saturation': np.clip(theta_S_DF, 0.3, 0.7), # m³/m³
'available_water': np.clip(available_water, 0.01, 0.4), # m³/m³
'sat_hydraulic_cond': np.clip(K_b, 0.1, 1000), # mm/h
'matric_bulk_density': np.clip(bulk_density_DF, 1.0, 2.0), # g/cm³
'b_parameter': np.clip(B, 1, 20), # 无量纲
'lambda_param': np.clip(lambda_val, 0.05, 2.0), # 无量纲
'air_entry_tension': np.clip(psi_e, 1, 50), # kPa
'bulk_density_normal': bulk_density_normal, # g/cm³
'compaction_factor': DF # 无量纲 (压实因子)
}
return soil_water_dict
def process_soil_water_characteristic(input_file, output_file, default_BD=None, default_Compaction=1.0):
"""
处理土壤参数计算的主函数
参数:
input_file: 输入CSV文件路径
output_file: 输出CSV文件路径
default_BD: 默认土壤容重 (g/cm³),如果HWSD数据中无容重数据,则使用此值
default_Compaction: 默认压实因子,默认值为 1.0
返回:
soil_water_df: 包含计算出的土壤水力参数的数据框DataFrame
"""
print("=== 土壤参数计算 ===")
# 1. 读取CSV文件
print("1. 读取CSV文件...")
df = pd.read_csv(input_file)
print(f" 读取到 {len(df)} 条记录")
# 2. 检查必要的字段
print("2. 检查必要字段...")
required_columns = ['grid_id', 'lon_center', 'lat_center', 'T_SAND', 'T_CLAY', 'T_OC']
missing_columns = [col for col in required_columns if col not in df.columns]
if missing_columns:
print(f"错误:缺少必要的字段: {missing_columns}")
return None
# 3. 数据清洗和预处理
print("3. 数据预处理...")
df_clean = df.copy()
# 处理数值型字段
numeric_columns = ['T_SAND', 'T_CLAY', 'T_OC', 'T_GRAVEL', 'T_ECE', 'T_REF_BULK_DENSITY']
for col in numeric_columns:
if col in df_clean.columns:
df_clean[col] = pd.to_numeric(df_clean[col], errors='coerce')
else:
if col == 'T_ECE': # 盐度,单位 dS/m
df_clean[col] = 0
elif col == 'T_GRAVEL': # 砾石,单位 %w
df_clean[col] = 0
elif col == 'T_REF_BULK_DENSITY': # 容重,单位 g/cm³
df_clean[col] = default_BD
# 确保坐标字段为数值型
df_clean['lon_center'] = pd.to_numeric(df_clean['lon_center'], errors='coerce')
df_clean['lat_center'] = pd.to_numeric(df_clean['lat_center'], errors='coerce')
# 计算有机质含量 (%w)
df_clean['T_OM'] = df_clean['T_OC'] * 1.724
# 4. 批量计算土壤水力参数
print("4. 计算土壤水力参数...")
results = []
error_count = 0
for idx, row in df_clean.iterrows():
try:
# 获取容重
BD = row.get('T_REF_BULK_DENSITY', default_BD)
params = calculate_soil_water_characteristic(
Sand=row['T_SAND'], # %w
Clay=row['T_CLAY'], # %w
OrganicMatter=row['T_OM'], # %w
Salinity=row.get('T_ECE', 0), # dS/m
Gravel=row.get('T_GRAVEL', 0), # %w
Compaction=default_Compaction, # 压实因子
)
# 组织结果
result_row = {
'grid_id': row['grid_id'],
'lon_center': row['lon_center'],
'lat_center': row['lat_center'],
'T_SAND': row['T_SAND'], # %w
'T_CLAY': row['T_CLAY'], # %w
'T_SILT': 100 - row['T_SAND'] - row['T_CLAY'], # %w
'T_OC': row['T_OC'], # %w
'T_OM': row['T_OM'], # %w
'T_GRAVEL': row.get('T_GRAVEL', 0), # %w
'T_ECE': row.get('T_ECE', 0), # dS/m
'T_REF_BULK_DENSITY': BD # g/cm³
}
result_row.update(params)
results.append(result_row)
except Exception as e:
error_count += 1
if error_count <= 5: # 只打印前5个错误
print(f" 警告: 计算第 {idx} 行时出错: {e}")
continue
if error_count > 0:
print(f" 共有 {error_count} 个网格计算失败")
# 5. 创建结果DataFrame并保存结果
print("5. 保存结果...")
soil_water_df = pd.DataFrame(results)
soil_water_df.to_csv(output_file, index=False)
print(f" 土壤参数文件: {output_file}")
print(f" 成功计算了 {len(soil_water_df)} 个网格的土壤参数")
# 6. 输出统计信息
print("\n=== 土壤参数统计 ===")
key_parameters = ['wilting_point', 'field_capacity', 'saturation', 'available_water', 'sat_hydraulic_cond']
for col in key_parameters:
if col in soil_water_df.columns:
valid_data = soil_water_df[col].dropna()
if len(valid_data) > 0:
if col == 'sat_hydraulic_cond':
unit = "mm/h"
else:
unit = "m³/m³"
print(f" {col}: {valid_data.mean():.4f} {unit} ± {valid_data.std():.4f}")
return soil_water_df
# 完整使用流程示例
if __name__ == "__main__":
# 参数设置
input_file = "./soil_data/grid_soil.csv" # 输入土壤数据文件
output_file = "./soil_data/grid_soil_water.csv" # 输出土壤水力文件
# 执行土壤参数计算
soil_water_df = process_soil_water_characteristic(input_file, output_file)
# 输出结果摘要
print(f"\n输出文件:")
print(f" - 土壤参数: {output_file}")
# 显示前几个网格的土壤水力参数
print(f"\n前5个网格的土壤水力参数:")
display_columns = ['grid_id', 'lon_center', 'lat_center',
'wilting_point', 'field_capacity', 'saturation', 'sat_hydraulic_cond']
available_columns = [col for col in display_columns if col in soil_water_df.columns]
print(soil_water_df[available_columns].head(5).to_string(index=False))下面代码整合地形、降水和土壤水分参数,生成VIC可读的土壤参数文件soil_param.txt。通常需要3层土壤支持模型运行 (Nlayer=3),共计53个参数 (12*3+17=53):
##########################
# create_soil_param.py
##########################
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
def generate_soil_param(soil_file, dem_file, precip_file, output_soil_file, soil_depth = [0.1, 0.3, 1.5]):
"""
生成VIC模型所需的土壤参数文件
参数:
soil_file: 土壤参数CSV文件路径
dem_file: 地形数据CSV文件路径
precip_file: 降水数据CSV文件路径
output_soil_file: 输出的土壤参数文件路径
soil_depth: 各层土壤厚度,默认为3层
"""
print("=== 生成VIC土壤参数文件 ===")
# 1. 读取数据
print("1. 读取数据文件...")
soil_df = pd.read_csv(soil_file)
dem_df = pd.read_csv(dem_file)
precip_df = pd.read_csv(precip_file)
print(f" 土壤数据: {len(soil_df)} 个网格")
print(f" 地形数据: {len(dem_df)} 个网格")
print(f" 降水数据: {len(precip_df)} 个网格")
# 2. 合并数据
print("2. 合并数据...")
merged_df = pd.merge(soil_df, dem_df, on='grid_id', how='inner')
merged_df = pd.merge(merged_df, precip_df, on='grid_id', how='inner')
print(f" 合并后: {len(merged_df)} 个网格")
# 3. 土壤数据清洗
print("3. 土壤数据清洗...")
initial_count = len(merged_df)
# 移除缺失值
merged_df = merged_df.dropna(subset=['T_SAND', 'T_CLAY', 'T_OC'])
# 移除异常值
merged_df = merged_df[
(merged_df['T_SAND'] >= 0) & (merged_df['T_SAND'] <= 100) &
(merged_df['T_CLAY'] >= 0) & (merged_df['T_CLAY'] <= 100) &
(merged_df['T_OC'] >= 0) & (merged_df['T_OC'] <= 100)
]
print(f" 清洗后: {len(merged_df)} 个网格 (过滤了 {initial_count - len(merged_df)} 个)")
if len(merged_df) == 0:
print("错误: 清洗后无有效数据")
return None
# 4. 填充缺失值
print("4. 填充缺失值...")
soil_vic_df = merged_df.copy()
# 为可能缺失的列设置默认值
default_values = {
'sat_hydraulic_cond': 10,
'lambda_param': 0.5,
'field_capacity': 0.3,
'wilting_point': 0.1,
'saturation': 0.5,
'air_entry_tension': 10,
'matric_bulk_density': 1.5,
'elevation': 100,
'precipitation': 1000
}
for col, default in default_values.items():
if col in soil_vic_df.columns:
soil_vic_df[col] = soil_vic_df[col].fillna(default)
# 5. 生成土壤参数文件
print("5. 生成土壤参数文件...")
with open(output_soil_file, 'w') as f:
for idx, row in soil_vic_df.iterrows():
# 基本网格信息
run_cell = 1
gridcel = int(row['grid_id'])
lat = row['lat_center']
lon = row['lon_center']
# 基本水力参数
wilting_point = row['wilting_point']
field_capacity = row['field_capacity']
saturation = row['saturation']
sat_hydraulic_cond = row['sat_hydraulic_cond']
lambda_param = row['lambda_param']
# 下渗与基流参数
infilt = 0.3
Ds = 0.001
Ws = 0.8
c = 2.0
# 土壤水力参数
expt = 3 + 2 / lambda_param
Ksat = sat_hydraulic_cond * 24
slope = 0.1
Dsmax = Ksat * slope
phi_s = -99
# 土壤深度
depth = np.array(soil_depth)
# 初始土壤水分
init_moist = field_capacity * depth * 1000 * 0.6
# 地形和气候参数
elev = row['elevation']
avg_T = 15 - (elev / 100) * 0.6
dp = 4.0
# 土壤物理参数
bubble = row['air_entry_tension'] * 10.197
# bubble = 0.32 * expt + 4.3 # 备选方法
quartz = 0.4 + 0.003 * row['T_SAND']
bulk_density = row['matric_bulk_density'] * 1000
soil_density = 2685
# 时区和水分特征参数
off_gmt = 8
Wcr_FRACT = 0.7 * field_capacity / saturation
Wpwp_FRACT = min(wilting_point / saturation, Wcr_FRACT)
# 地表参数
rough = 0.01
snow_rough = 0.001
annual_prec = row['precipitation']
# 其他参数
resid_moist = wilting_point * 0.3
fs_active = 0
# 组织输出行 - 按参数类别分组,避免过长行
# 1. 基本网格信息 (4个参数)
grid_info = f"{run_cell} {gridcel} {lat:.6f} {lon:.6f}"
# 2. 下渗与基流参数 (5个参数)
infiltration_params = f"{infilt:.4f} {Ds:.4f} {Dsmax:.4f} {Ws:.4f} {c:.0f}"
# 3. 土壤水力参数 (12个参数)
hydraulic_params = f"{expt:.4f} {expt:.4f} {expt:.4f} {Ksat:.4f} {Ksat:.4f} {Ksat:.4f}"
hydraulic_params += f" {phi_s:.0f} {phi_s:.0f} {phi_s:.0f}"
hydraulic_params += f" {init_moist[0]:.4f} {init_moist[1]:.4f} {init_moist[2]:.4f}"
# 4. 地形和气候参数 (6个参数)
terrain_params = f"{elev:.2f} {depth[0]:.4f} {depth[1]:.4f} {depth[2]:.4f} {avg_T:.2f} {dp:.0f}"
# 5. 土壤物理参数 (12个参数)
soil_physics = f"{bubble:.4f} {bubble:.4f} {bubble:.4f}"
soil_physics += f" {quartz:.3f} {quartz:.3f} {quartz:.3f}"
soil_physics += f" {bulk_density:.1f} {bulk_density:.1f} {bulk_density:.1f}"
soil_physics += f" {soil_density:.0f} {soil_density:.0f} {soil_density:.0f}"
# 6. 时区和水分特征参数 (7个参数)
moisture_params = f"{off_gmt:.0f}"
moisture_params += f" {Wcr_FRACT:.4f} {Wcr_FRACT:.4f} {Wcr_FRACT:.4f}"
moisture_params += f" {Wpwp_FRACT:.4f} {Wpwp_FRACT:.4f} {Wpwp_FRACT:.4f}"
# 7. 地表和其他参数 (7个参数)
surface_params = f"{rough:.4f} {snow_rough:.4f} {annual_prec:.2f}"
surface_params += f" {resid_moist:.4f} {resid_moist:.4f} {resid_moist:.4f}"
surface_params += f" {fs_active:.0f}"
# 合并所有参数
output_line = f"{grid_info} {infiltration_params} {hydraulic_params} {terrain_params} {soil_physics} {moisture_params} {surface_params}"
f.write(output_line + '\n')
print(f"VIC土壤参数文件生成完成: {output_soil_file}")
print(f"共处理了 {len(soil_vic_df)} 个网格")
# 显示统计信息
print("\n=== 统计信息 ===")
print(f"网格数量: {len(soil_vic_df)}")
print(f"纬度范围: {soil_vic_df['lat_center'].min():.4f} - {soil_vic_df['lat_center'].max():.4f}")
print(f"经度范围: {soil_vic_df['lon_center'].min():.4f} - {soil_vic_df['lon_center'].max():.4f}")
print(f"高程范围: {soil_vic_df['elevation'].min():.1f} - {soil_vic_df['elevation'].max():.1f} m")
print(f"年降水范围: {soil_vic_df['precipitation'].min():.1f} - {soil_vic_df['precipitation'].max():.1f} mm")
def create_soil_param_description(output_desc_file="soil_param_description.txt", soil_depth = [0.1, 0.3, 1.5]):
"""
创建土壤参数文件的描述文档
"""
description = """# VIC土壤参数文件说明
生成时间: {time}
## 文件格式
总列数: 53列
### 1. 基本网格信息 (4列)
列号\t变量名\t单位\t描述
1\trun_cell\t-\t1=运行网格, 0=不运行
2\tgridcel\t-\t网格编号
3\tlat\t度\t纬度
4\tlon\t度\t经度
### 2. 下渗与基流参数 (5列)
5\tinfilt\t-\t变量下渗曲线参数
6\tDs\t分数\t非线性基流开始的比例
7\tDsmax\tmm/天\t最大基流速度
8\tWs\t分数\t非线性基流发生的土壤水分比例
9\tc\t-\t基流曲线指数
### 3. 土壤水力参数 (12列)
10-12\texpt\t-\tCampbell水力传导指数 (3层)
13-15\tKsat\tmm/天\t饱和水力传导率 (3层)
16-18\tphi_s\t-\t土壤水分扩散参数(未使用) (3层)
19-21\tinit_moist\tmm\t初始土壤水分 (3层)
### 4. 地形和气候参数 (6列)
22\telev\tm\t平均高程
23-25\tdepth\tm\t土壤层厚度 (3层)
26\tavg_T\t°C\t平均土壤温度
27\tdp\tm\t土壤热阻尼深度
### 5. 土壤物理参数 (12列)
28-30\tbubble\tcm\t气泡压力 (3层)
31-33\tquartz\t-\t石英含量 (3层)
34-36\tbulk_density\tkg/m³\t土壤容重 (3层)
37-39\tsoil_density\tkg/m³\t土壤颗粒密度 (3层)
### 6. 时区和水分特征参数 (7列)
40\toff_gmt\t小时\t时区偏移
41-43\tWcr_FRACT\t分数\t临界点水分比例 (3层)
44-46\tWpwp_FRACT\t分数\t萎蔫点水分比例 (3层)
### 7. 地表和其他参数 (7列)
47\trough\tm\t地表粗糙度
48\tsnow_rough\tm\t雪面粗糙度
49\tannual_prec\tmm\t年平均降水
50-52\tresid_moist\t分数\t残余水分含量 (3层)
53\tfs_active\t-\t冻土算法激活标志
## 参数估算说明
- infilt, Ds, Ws, c: 使用典型文献值
- Dsmax: 基于饱和导水率估算 (Ksat * slope)
- avg_T: 基于高程估算(每100m降温0.6°C)
- quartz: 使用典型值0.6
- soil_density: 使用典型值2685 kg/m³
- Wcr_FRACT: 使用典型值0.7
- Wpwp_FRACT: 萎蔫点/饱和含水量
- 粗糙度参数: 使用典型文献值
- 初始土壤水分: 设为田间持水量的80%
- 残余水分含量: 设为萎蔫点的50%
## 土壤层设置
- 第1层: 0-{layer1:.1f}m (厚度: {thickness1:.1f}m)
- 第2层: {layer1:.1f}-{layer2:.1f}m (厚度: {thickness2:.1f}m)
- 第3层: {layer2:.1f}-{layer3:.1f}m (厚度: {thickness3:.1f}m)
总厚度: {layer3:.1f}m
""".format(time=pd.Timestamp.now().strftime("%Y-%m-%d %H:%M:%S"),
layer1=soil_depth[0],
layer2=soil_depth[0] + soil_depth[1],
layer3=soil_depth[0] + soil_depth[1] + soil_depth[2],
thickness1=soil_depth[0],
thickness2=soil_depth[1],
thickness3=soil_depth[2]
)
with open(output_desc_file, 'w', encoding='utf-8') as f:
f.write(description)
print(f"参数描述文件已生成: {output_desc_file}")
# 完整使用流程示例
if __name__ == "__main__":
# 参数设置
soil_file = "./soil_data/grid_soil_water.csv" # 输出土壤水力文件
dem_file = "../elevation/elevation_data/grid_elevation.csv" # 输入地形数据文件
precip_file = "../precipitation/precipitation_data/grid_precipitation.csv" # 输入降水数据文件
output_soil_file = "soil_param.txt" # 输出土壤参数文件
soil_depth = [0.1, 0.3, 1.5] # 各层土壤厚度
# 生成VIC土壤参数文件
generate_soil_param(
soil_file=soil_file,
dem_file=dem_file,
precip_file=precip_file,
output_soil_file=output_soil_file,
soil_depth = soil_depth
)
# 输出结果摘要
print(f"\n输出文件:")
print(f" - 土壤参数文件: {output_soil_file}")
# 生成输出参数描述文件
create_soil_param_description(soil_depth = soil_depth)
# 显示文件前几行作为示例
print(f"\n前3个网格的土壤参数:")
with open(output_soil_file, 'r') as f:
for i, line in enumerate(f):
if i < 3:
print(f"第{i+1}行: {line.strip()}")
else:
break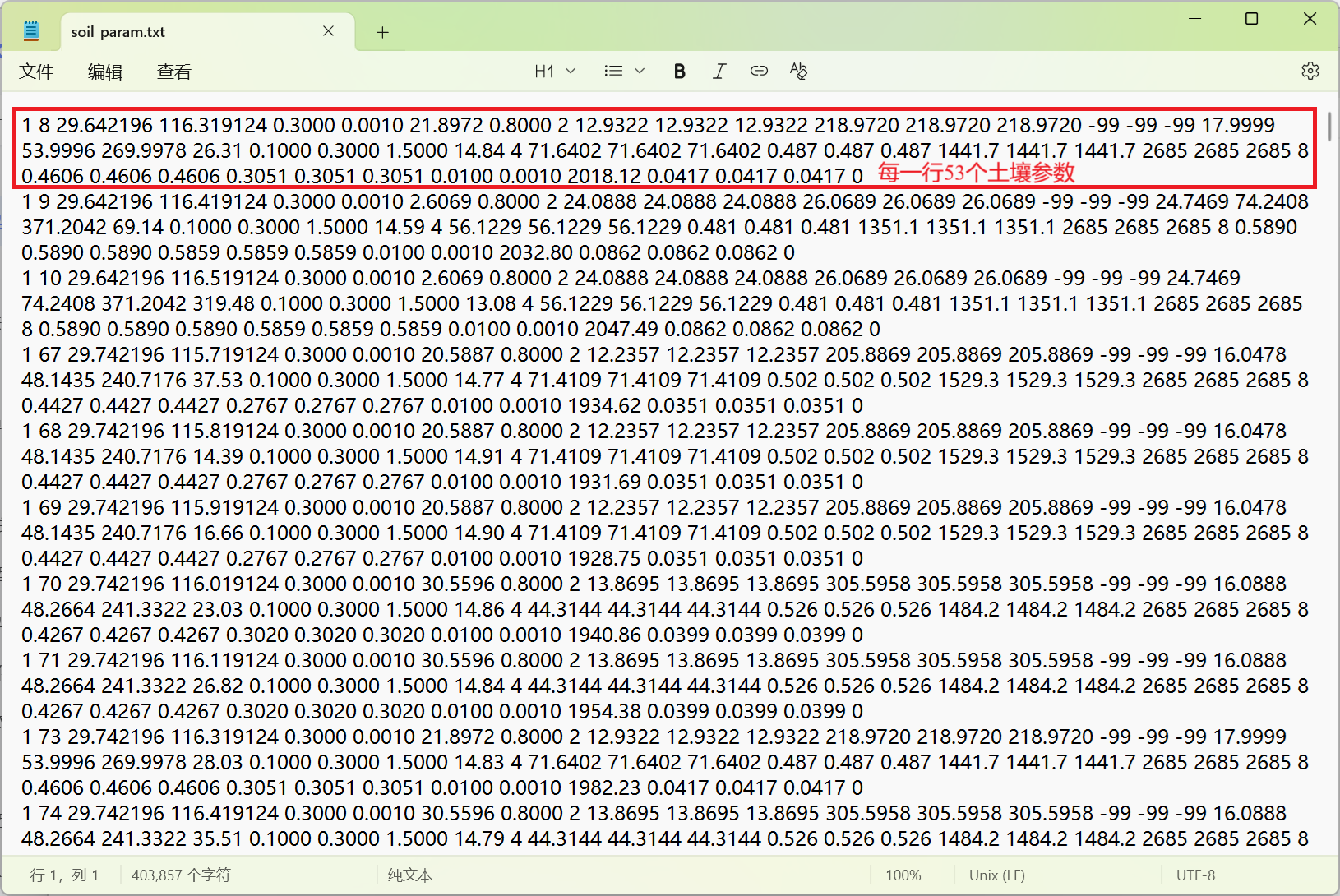
5. 制备植被参数
本教程使用NASA MODIS土地覆盖数据,可能需要下载多个瓦片并进行拼接,拼接方法参见https://blog.youkuaiyun.com/ME1010/article/details/148881961,或直接使用下面代码拼接:
##########################
# process_modis.py
##########################
from osgeo import gdal
import numpy as np
import os
from glob import glob
import warnings
warnings.filterwarnings('ignore')
def extract_modis_hdf(hdf_files, output_dir):
"""
从MCD12Q1 HDF文件中提取土地覆盖数据层
参数:
hdf_files: HDF文件列表
output_dir: 输出目录路径
返回:
extracted_files: 提取的TIFF文件路径列表list
"""
layers = {
'LC_Type1': 'HDF4_EOS:EOS_GRID:"{fname}":MCD12Q1:LC_Type1',
'QC': 'HDF4_EOS:EOS_GRID:"{fname}":MCD12Q1:QC'
}
extracted_files = []
for hdf_file in hdf_files:
base_name = os.path.basename(hdf_file).replace('.hdf', '')
for layer_name, template in layers.items():
gdal_path = template.format(fname=hdf_file)
output_tif = os.path.join(output_dir, f"{base_name}_{layer_name}.tif")
try:
gdal.Translate(output_tif, gdal_path)
extracted_files.append(output_tif)
print(f"提取完成: {output_tif}")
except Exception as e:
print(f"提取失败 {output_tif}: {e}")
return extracted_files
def reproject_and_mosaic(input_files, output_dir, target_epsg="EPSG:4326", output_res=0.005):
"""
将正弦投影转换为地理坐标系并拼接
参数:
input_files: 输入TIFF文件列表
output_dir: 输出目录路径
target_epsg: 目标坐标系, 默认EPSG:4326
output_res: 输出分辨率, 默认0.005度
返回:
mosaic_output: 拼接后的文件路径str
"""
reprojected_files = []
for tif_file in input_files:
if "LC_Type1" in tif_file:
base_name = os.path.basename(tif_file).replace('.tif', '')
output_file = os.path.join(output_dir, f"{base_name}_reprojected.tif")
gdal.Warp(output_file, tif_file,
dstSRS=target_epsg,
resampleAlg=gdal.GRA_NearestNeighbour,
xRes=output_res, yRes=output_res)
reprojected_files.append(output_file)
print(f"重投影完成: {output_file}")
# 拼接
mosaic_output = os.path.join(output_dir, "MCD12Q1_LC_Type1_mosaic.tif")
if len(reprojected_files) > 1:
gdal.Warp(mosaic_output, reprojected_files,
format='GTiff', resampleAlg=gdal.GRA_NearestNeighbour)
print(f"拼接完成: {mosaic_output}")
else:
gdal.Translate(mosaic_output, reprojected_files[0])
print(f"单文件转换完成: {mosaic_output}")
return mosaic_output
def clip_to_shp_region(input_raster, region_shp, output_dir):
"""
将数据裁剪到研究区域范围
参数:
input_raster: 输入栅格文件路径
region_shp: 区域边界Shapefile路径
output_dir: 输出目录路径
返回:
clipped_output: 裁剪后的文件路径str
"""
base_name = os.path.basename(input_raster).replace('.tif', '')
clipped_output = os.path.join(output_dir, f"{base_name}_Yangtze.tif")
gdal.Warp(clipped_output, input_raster,
cutlineDSName=region_shp,
cropToCutline=True,
dstNodata=255,
resampleAlg=gdal.GRA_NearestNeighbour)
print(f"裁剪完成: {clipped_output}")
return clipped_output
def process_modis_data(hdf_files, output_dir, region_shp=None):
"""
处理MODIS数据的完整流程
参数:
hdf_files: HDF文件列表
output_dir: 输出目录路径
region_shp: 区域边界Shapefile路径 (可选)
返回:
final_output: 最终的土地覆盖文件路径str
"""
print("=== 开始处理MCD12Q1数据 ===")
# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
print(f"输出目录: {output_dir}")
# 1. 提取HDF数据
print("1. 提取HDF数据...")
extracted_tifs = extract_modis_hdf(hdf_files, output_dir)
# 2. 投影转换和拼接
print("2. 投影转换和拼接...")
lc_type1_files = [f for f in extracted_tifs if "LC_Type1" in f]
mosaic_file = reproject_and_mosaic(lc_type1_files, output_dir)
# 3. 裁剪到研究区域 (如果提供了边界文件)
if region_shp and os.path.exists(region_shp):
print("3. 裁剪到研究区域...")
final_output = clip_to_shp_region(mosaic_file, region_shp, output_dir)
else:
print("3. 跳过裁剪步骤 (未提供边界文件)")
final_output = mosaic_file
print("\n=== 数据处理完成 ===")
print(f"最终土地覆盖文件: {final_output}")
return final_output
# 完整使用流程示例
if __name__ == "__main__":
# 参数设置
hdf_files = glob("MODIS/MCD12Q1*.hdf") # HDF文件路径模式
output_dir = "./modis_data" # 输出目录
# region_shp = "../grid/Lower_YRB.shp" # 研究区域边界文件 (可选)
# 执行完整流程
final_lc_file = process_modis_data(
hdf_files=hdf_files,
output_dir=output_dir
)
# 输出结果摘要
print(f"\n输出文件:")
print(f" - 土地覆盖数据: {final_lc_file}")
# 显示文件信息
dataset = gdal.Open(final_lc_file)
print(f"\n文件信息:")
print(f" 尺寸: {dataset.RasterXSize} x {dataset.RasterYSize}")
print(f" 波段数: {dataset.RasterCount}")
print(f" 地理范围: {dataset.GetGeoTransform()}")
dataset = None下面代码基于网格坐标和土地覆盖栅格生成植被参数文件veg_param.txt,其中根系参数参考Schaperow文献,LAI和反照率与植被表文件veg_lib.txt保持一致:
##########################
# create_veg_param.py
##########################
import geopandas as gpd
import pandas as pd
import numpy as np
from osgeo import gdal
from rasterstats import zonal_stats
import os
import warnings
warnings.filterwarnings('ignore')
def calculate_vegetation_fractions(soil_param_file, landcover_file, grid_resolution=None):
"""
计算各植被类型的比例
参数:
soil_param_file: 土壤参数文件路径
landcover_file: 土地覆盖栅格文件路径
grid_resolution: 网格分辨率 (度), 如果为None则自动计算
返回:
vegetation_data: 植被比例数据list
"""
print("=== 开始计算植被类型比例 ===")
# 1. 从土壤参数文件读取网格信息
print("1. 读取网格信息...")
soil_params = pd.read_csv(soil_param_file, delim_whitespace=True, header=None)
# 提取网格ID、纬度和经度
grid_ids = soil_params[1].values # 第2列是grid_id
lats = soil_params[2].values # 第3列是纬度
lons = soil_params[3].values # 第4列是经度
print(f" 网格点数量: {len(grid_ids)}")
print(f" 经度范围: {lons.min():.3f} ~ {lons.max():.3f}")
print(f" 纬度范围: {lats.min():.3f} ~ {lats.max():.3f}")
# 处理网格大小
if grid_resolution is None:
if len(lons) > 1:
# 使用经度差自动计算网格大小 (如果未提供)
grid_resolution = abs(lons[1] - lons[0])
print(f" 自动计算的空间分辨率: {grid_resolution:.6f} 度")
else:
# 如果只有一个网格,使用默认值
grid_resolution = 0.1
print(f" 警告: 只有一个网格,使用默认分辨率: {grid_resolution} 度")
else:
print(f" 使用指定的空间分辨率: {grid_resolution:.3f} 度")
# 创建网格多边形
grid_features = []
for i, (grid_id, lat, lon) in enumerate(zip(grid_ids, lats, lons)):
half_res = grid_resolution / 2
left = lon - half_res
right = lon + half_res
bottom = lat - half_res
top = lat + half_res
polygon = {
'type': 'Polygon',
'coordinates': [[
[left, bottom],
[right, bottom],
[right, top],
[left, top],
[left, bottom]
]]
}
grid_features.append({
'type': 'Feature',
'properties': {'grid_id': grid_id, 'lat': lat, 'lon': lon},
'geometry': polygon
})
# 转换为GeoDataFrame
grid_gdf = gpd.GeoDataFrame.from_features(grid_features)
grid_gdf.crs = "EPSG:4326"
# 2. IGBP到VIC植被类型映射
print("2. 映射IGBP到VIC...")
IGBP_TO_VIC = {
1: 1, # Evergreen Needleleaf Forest
2: 2, # Evergreen Broadleaf Forest
3: 3, # Deciduous Needleleaf Forest
4: 4, # Deciduous Broadleaf Forest
5: 5, # Mixed Forests
6: 6, # Closed Shrublands
7: 7, # Open Shrublands
8: 8, # Woody Savannas
9: 9, # Savannas
10: 10, # Grasslands
11: 11, # Permanent Wetlands
12: 12, # Croplands
13: 13, # Urban and Built-up
14: 14, # Cropland/Natural Vegetation Mosaic
15: 15, # Snow and Ice
16: 16, # Barren
17: 0, # Water (IGBP 17)
}
# 3. 执行区域统计
print("3. 正在进行区域统计...")
stats = zonal_stats(grid_gdf,
landcover_file,
categorical=True,
category_map=IGBP_TO_VIC,
all_touched=True,
nodata=255)
# 4. 处理统计结果
print("4. 处理统计结果...")
vegetation_data = []
for i, (grid_id, lat, lon, stat) in enumerate(zip(grid_ids, lats, lons, stats)):
total_pixels = sum(stat.values())
if total_pixels == 0:
print(f"警告: 网格 {grid_id} 没有有效数据")
# 添加默认植被类型(裸地)
vegetation_data.append({
'grid_id': grid_id,
'lat': lat,
'lon': lon,
'vegetation_fractions': [(16, 1.0)] # 100% 裸地
})
continue
# 计算植被比例 (各像素数除以总像素数)
vic_fractions = {}
for veg_type, pixel_count in stat.items():
vic_contribution = pixel_count / total_pixels
if veg_type in vic_fractions:
vic_fractions[veg_type] += vic_contribution
else:
vic_fractions[veg_type] = vic_contribution
# 归一化处理
total_fraction = sum(vic_fractions.values())
if abs(total_fraction - 1.0) > 0.01:
for vic_type in vic_fractions:
vic_fractions[vic_type] /= total_fraction
sorted_fractions = sorted(vic_fractions.items(), key=lambda x: x[1], reverse=True)
vegetation_data.append({
'grid_id': grid_id,
'lat': lat,
'lon': lon,
'vegetation_fractions': sorted_fractions
})
print(f"植被比例计算完成,处理了 {len(vegetation_data)} 个网格")
return vegetation_data
def generate_veg_param(soil_param_file, vegetation_data, output_file, veg_lai_params=None, veg_albedo_params=None):
"""
基于 Schaperow (2021) 表格生成VIC模型所需的植被参数文件
参数:
soil_param_file: 土壤参数文件路径
vegetation_data: 之前计算的植被比例数据
output_file: 输出文件路径
veg_lai_params: LAI参数,如果为None则不输出LAI
veg_albedo_params: 反照率参数,如果为None则不输出反照率
"""
print("=== 开始生成植被参数文件 ===")
# 1. 检查参数设置
if veg_lai_params is None:
print("注意: veg_lai_params=None, 将不在veg_param.txt中输出LAI")
print("提示: 请在全局参数文件中设置 LAI_SRC=FROM_VEGLIB")
if veg_albedo_params is None:
print("注意: veg_albedo_params=None, 将不在veg_param.txt中输出反照率")
print("提示: 请在全局参数文件中设置 ALB_SRC=FROM_VEGLIB")
# 2. 从土壤参数文件读取网格信息
soil_params = pd.read_csv(soil_param_file, delim_whitespace=True, header=None)
# 提取网格ID、纬度和经度
grid_ids = soil_params[1].values # 第2列是grid_id
lats = soil_params[2].values # 第3列是纬度
lons = soil_params[3].values # 第4列是经度
print(f"从土壤参数文件中处理 {len(grid_ids)} 个网格单元")
# 3. 植被类型参数默认值
# 根区参数 - 假设3个根区
veg_root_params = {
# veg_type: [root_depth1, root_fract1, root_depth2, root_fract2, root_depth3, root_fract3]
0: [0.1, 0.44, 0.6, 0.45, 0.8, 0.11], # 水体 (Open water)
1: [0.1, 0.34, 0.6, 0.51, 1.1, 0.14], # 常绿针叶林 (Evergreen needleleaf forest)
2: [0.1, 0.32, 0.6, 0.44, 2.3, 0.23], # 常绿阔叶林 (Evergreen broadleaf forest)
3: [0.1, 0.34, 0.6, 0.50, 1.3, 0.16], # 落叶针叶林 (Deciduous needleleaf forest)
4: [0.1, 0.31, 0.6, 0.52, 1.3, 0.17], # 落叶阔叶林 (Deciduous broadleaf forest)
5: [0.1, 0.25, 0.6, 0.52, 1.7, 0.22], # 混交林 (Mixed forest)
6: [0.1, 0.31, 0.6, 0.49, 1.8, 0.21], # 郁闭灌丛 (Closed shrublands)
7: [0.1, 0.33, 0.6, 0.43, 2.4, 0.24], # 开放灌丛 (Open shrublands)
8: [0.1, 0.37, 0.6, 0.50, 1.0, 0.13], # 木本稀树草原 (Woody savanna)
9: [0.1, 0.36, 0.6, 0.45, 1.7, 0.19], # 稀树草原 (Savanna)
10: [0.1, 0.44, 0.6, 0.45, 0.8, 0.11], # 草地 (Grasslands)
11: [0.1, 0.44, 0.6, 0.45, 0.8, 0.11], # 湿地 (Permanent wetlands)
12: [0.1, 0.33, 0.6, 0.55, 0.8, 0.12], # 耕地 (Cropland)
13: [0.1, 0.44, 0.6, 0.45, 0.8, 0.11], # 城市 (Urban)
14: [0.1, 0.33, 0.6, 0.55, 0.8, 0.12], # 耕地/自然混合 (Cropland/natural vegetation mosaic)
15: [0.1, 0.44, 0.6, 0.45, 0.8, 0.11], # 冰雪 (Permanent snow and ice)
16: [0.1, 0.22, 0.6, 0.46, 3.3, 0.31] # 裸地 (Barren)
}
# 4. LAI月值 (根据表格数据更新)
if veg_lai_params is None:
# 使用空字典,表示不输出LAI
veg_lai_params = {}
elif veg_lai_params=='default':
# 使用提供的LAI参数
veg_lai_params = {
# veg_type: 12个月的叶面积指数 (1月到12月)
0: [0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20], # 水体 (Open Water)
1: [3.40, 3.40, 3.50, 3.70, 4.00, 4.40, 4.40, 4.30, 4.20, 3.70, 3.50, 3.40], # 常绿针叶林 (Evergreen Needleleaf forest)
2: [3.40, 3.40, 3.50, 3.70, 4.00, 4.40, 4.40, 4.30, 4.20, 3.70, 3.50, 3.40], # 常绿阔叶林 (Evergreen Broadleaf forest)
3: [1.68, 1.52, 1.68, 2.90, 4.90, 5.00, 5.00, 4.60, 3.44, 3.04, 2.16, 2.00], # 落叶针叶林 (Deciduous Needleleaf forest)
4: [1.68, 1.52, 1.68, 2.90, 4.90, 5.00, 5.00, 4.60, 3.44, 3.04, 2.16, 2.00], # 落叶阔叶林 (Deciduous Broadleaf forest)
5: [1.68, 1.52, 1.68, 2.90, 4.90, 5.00, 5.00, 4.60, 3.44, 3.04, 2.16, 2.00], # 混交林 (Mixed forest)
6: [2.00, 2.25, 2.95, 3.85, 3.75, 3.50, 3.55, 3.20, 3.30, 2.85, 2.60, 2.20], # 郁闭灌丛 (Closed Shrublands)
7: [2.00, 2.25, 2.95, 3.85, 3.75, 3.50, 3.55, 3.20, 3.30, 2.85, 2.60, 2.20], # 开放灌丛 (Open Shrublands)
8: [1.68, 1.52, 1.68, 2.90, 4.90, 5.00, 5.00, 4.60, 3.44, 3.04, 2.16, 2.00], # 木本稀树草原 (Woody Savannas)
9: [2.00, 2.25, 2.95, 3.85, 3.75, 3.50, 3.55, 3.20, 3.30, 2.85, 2.60, 2.20], # 稀树草原 (Savannas)
10: [2.00, 2.25, 2.95, 3.85, 3.75, 3.50, 3.55, 3.20, 3.30, 2.85, 2.60, 2.20], # 草地 (Grasslands)
11: [2.00, 2.25, 2.95, 3.85, 3.75, 3.50, 3.55, 3.20, 3.30, 2.85, 2.60, 2.20], # 湿地 (Permanent wetlands)
12: [0.50, 0.50, 0.50, 0.50, 1.50, 3.00, 4.50, 5.00, 2.50, 0.50, 0.50, 0.50], # 耕地 (Croplands)
13: [0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20], # 城市 (Urban and built-up)
14: [2.00, 2.25, 2.95, 3.85, 3.75, 3.50, 3.55, 3.20, 3.30, 2.85, 2.60, 2.20], # 耕地/自然混合 (Cropland/Natural vegetation mosaic)
15: [0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20], # 冰雪 (Snow and ice)
16: [0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20] # 裸地 (Barren or sparsely vegetated)
}
# 5. 反照率月值 (根据表格数据更新)
if veg_albedo_params is None:
# 使用空字典,表示不输出反照率
veg_albedo_params = {}
elif veg_albedo_params=='default':
# 使用提供的反照率参数
veg_albedo_params = {
# veg_type: 12个月的反照率 (1月到12月)
0: [0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20], # 水体 (Open Water)
1: [0.12, 0.12, 0.12, 0.12, 0.12, 0.12, 0.12, 0.12, 0.12, 0.12, 0.12, 0.12], # 常绿针叶林 (Evergreen Needleleaf forest)
2: [0.12, 0.12, 0.12, 0.12, 0.12, 0.12, 0.12, 0.12, 0.12, 0.12, 0.12, 0.12], # 常绿阔叶林 (Evergreen Broadleaf forest)
3: [0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18], # 落叶针叶林 (Deciduous Needleleaf forest)
4: [0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18], # 落叶阔叶林 (Deciduous Broadleaf forest)
5: [0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18], # 混交林 (Mixed forest)
6: [0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19], # 郁闭灌丛 (Closed Shrublands)
7: [0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19], # 开放灌丛 (Open Shrublands)
8: [0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18, 0.18], # 木本稀树草原 (Woody Savannas)
9: [0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19], # 稀树草原 (Savannas)
10: [0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20], # 草地 (Grasslands)
11: [0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20], # 湿地 (Permanent wetlands)
12: [0.10, 0.10, 0.10, 0.10, 0.20, 0.20, 0.20, 0.20, 0.20, 0.10, 0.10, 0.10], # 耕地 (Croplands)
13: [0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20], # 城市 (Urban and built-up)
14: [0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19, 0.19], # 耕地/自然混合 (Cropland/Natural vegetation mosaic)
15: [0.60, 0.60, 0.60, 0.60, 0.60, 0.60, 0.60, 0.60, 0.60, 0.60, 0.60, 0.60], # 冰雪 (Snow and ice)
16: [0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20, 0.20] # 裸地 (Barren or sparsely vegetated)
}
# 6. 生成植被参数文件
with open(output_file, 'w') as f:
for i, (grid_id, lat, lon) in enumerate(zip(grid_ids, lats, lons)):
# 获取该网格的植被类型比例数据
if i < len(vegetation_data):
grid_veg_data = vegetation_data[i]
else:
print(f"警告: 网格 {grid_id} 没有植被数据,跳过")
continue
# 网格号和植被类型数量
n_veg_types = len(grid_veg_data['vegetation_fractions'])
f.write(f"{int(grid_id)} {n_veg_types}\n")
# 遍历该网格的每种植被类型
for veg_type, fraction in grid_veg_data['vegetation_fractions']:
veg_type = int(veg_type)
# 植被类型和覆盖比例
f.write(f" {veg_type} {fraction:.4f} ")
# 根区参数(3个根区)
if veg_type in veg_root_params:
root_params = veg_root_params[veg_type]
for zone in range(3):
if zone==2:
f.write(f"{root_params[zone*2]:.3f} {root_params[zone*2+1]:.3f}\n")
else:
f.write(f"{root_params[zone*2]:.3f} {root_params[zone*2+1]:.3f} ")
else:
# 使用默认值
for zone in range(3):
if zone==2:
f.write("0.100 0.333\n")
else:
f.write("0.100 0.333 ")
# LAI月值(12个月)- 仅在veg_lai_params不为None时输出
if veg_lai_params and veg_type in veg_lai_params:
lai_values = veg_lai_params[veg_type]
lai_line = " ".join([f"{val:.3f}" for val in lai_values])
f.write(f" {lai_line}\n")
elif veg_lai_params:
# 使用默认值
lai_line = " ".join(["1.000"] * 12) + "\n"
f.write(f" {lai_line}\n")
# 如果veg_lai_params为None,则不输出LAI行
# 反照率月值(12个月)- 仅在veg_albedo_params不为None时输出
if veg_albedo_params and veg_type in veg_albedo_params:
albedo_values = veg_albedo_params[veg_type]
albedo_line = " ".join([f"{val:.3f}" for val in albedo_values])
f.write(f" {albedo_line}\n")
elif veg_albedo_params:
# 使用默认值
albedo_line = " ".join(["0.150"] * 12) + "\n"
f.write(f" {albedo_line}\n")
# 如果veg_albedo_params为None,则不输出反照率行
print(f"VIC植被参数文件已生成: {output_file}")
# 完整使用流程示例
if __name__ == "__main__":
# 参数设置
soil_param_file = "../soil/soil_param.txt" # 土壤参数文件
landcover_file = "./modis_data/MCD12Q1_LC_Type1_mosaic.tif" # 土地覆盖数据
output_veg_file = "veg_param.txt" # 输出植被参数文件
grid_resolution = 0.1 # VIC网格分辨率
# 计算植被比例
vegetation_data = calculate_vegetation_fractions(soil_param_file, landcover_file, grid_resolution)
# 生成植被参数文件
generate_veg_param(soil_param_file, vegetation_data, output_veg_file, veg_lai_params='default', veg_albedo_params='default')
# 输出结果摘要
print(f"\n输出文件:")
print(f" - 植被参数: {output_veg_file}")
# 显示基本网格统计信息
n_grids = len(vegetation_data)
print(f"网格总数: {n_grids}")
# 每个网格的植被类型数量统计
veg_types_per_grid = [len(grid['vegetation_fractions']) for grid in vegetation_data]
avg_veg_types = np.mean(veg_types_per_grid)
max_veg_types = np.max(veg_types_per_grid)
min_veg_types = np.min(veg_types_per_grid)
print(f"每个网格的植被类型数:")
print(f" - 平均: {avg_veg_types:.2f}")
print(f" - 最大: {max_veg_types}")
print(f" - 最小: {min_veg_types}")VIC可读的植被参数文件veg_param.txt包含头行信息和各植被类型的根系分布 (深度和比例)、LAI月值、反照率月值等参数,按固定格式循环排列。
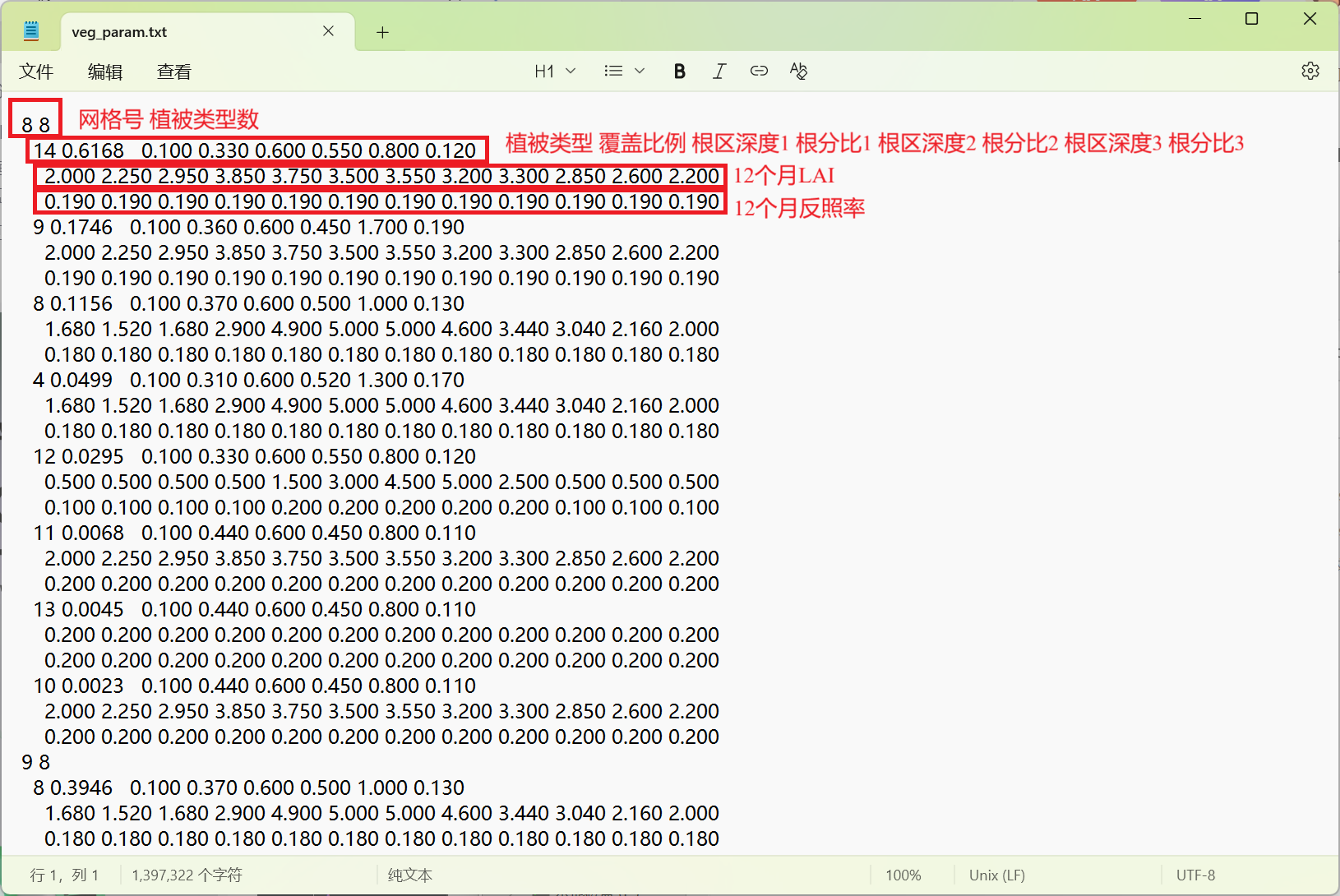
同时模型运行还需要植被表文件veg_lib.txt,可直接使用官方示例中IGBP分类的植被表。
6. 制备强迫数据
VIC模型必需的强迫变量包括:气温、降水、气压、向下短波辐射、向下长波辐射、水汽压、风速。本教程使用MERRA-2逐小时数据,下载地址包括通量、辐射和气压数据集。下载完成后使用CDO等方法将各变量提取为单独的文件。
下面代码基于网格坐标生成各格点的气象强迫数据forcing_[lat]_[lon],每行对应一小时数据,七列变量顺序需与全局文件中FORCE_TYPE定义一致。单位转换在Python代码的配置 (config)部分完成:
##########################
# create_forcing.py
##########################
import xarray as xr
import numpy as np
import pandas as pd
from scipy import interpolate
import os
from datetime import datetime
from typing import Dict, List, Optional, Tuple
import warnings
warnings.filterwarnings('ignore')
class VICForcingGenerator:
"""
VIC模型驱动数据生成器
"""
def __init__(self, config: Dict):
"""
初始化驱动数据生成器
参数:
config: 配置字典, 包含文件路径和参数设置
"""
self.config = config
self.vic_variables = {}
self.grid_info = {}
self.datasets = {}
self.time_offsets = {} # 存储各变量的时间偏移 (小时)
self.vic_var_order = ['AIR_TEMP', 'PREC', 'PRESSURE', 'SWDOWN', 'LWDOWN', 'VP', 'WIND']
@staticmethod
def calculate_vapor_pressure(specific_humidity: np.ndarray, surface_pressure: np.ndarray) -> np.ndarray:
"""
根据比湿和地表气压计算水汽压
"""
vapor_pressure_pa = specific_humidity * surface_pressure / (0.622 + 0.378 * specific_humidity)
vapor_pressure_kpa = vapor_pressure_pa / 1000.0
return vapor_pressure_kpa
@staticmethod
def estimate_incoming_longwave_radiation(air_temperature: np.ndarray) -> np.ndarray:
"""
简化版长波辐射计算 - 使用固定发射率0.85
参数:
air_temperature: 气温 (K)
返回:
longwave_radiation: 下行长波辐射通量 (W/m²)
"""
stefan_boltzmann = 5.67e-8 # Stefan-Boltzmann常数
emissivity = 0.85 # 固定发射率
longwave_radiation = emissivity * stefan_boltzmann * air_temperature**4
return longwave_radiation
def interpolate_to_target_grid(self, source_data: xr.DataArray, data_name: str = None, method: str = 'linear') -> np.ndarray:
"""
将气象数据插值到目标网格系统
参数:
source_data: 源数据数组
data_name: 数据名称 (用于获取时间偏移)
method: 插值方法
"""
source_lons = source_data.lon.values
source_lats = source_data.lat.values
n_grid_cells = len(self.grid_info['longitudes'])
# 获取该数据的时间偏移
offset = self.time_offsets.get(data_name, 0)
# 计算需要提取的时间步数
total_source_steps = len(source_data.time)
steps_to_extract = min(self.n_time_steps, total_source_steps - offset)
if steps_to_extract <= 0:
print(f" 警告: {data_name} 无有效数据, 偏移={offset}, 总步数={total_source_steps}")
return np.full((self.n_time_steps, n_grid_cells), np.nan)
# 初始化结果数组
interpolated_data = np.full((self.n_time_steps, n_grid_cells), np.nan)
# 只处理有效的时间范围
for i in range(steps_to_extract):
time_idx = offset + i
interpolation_function = interpolate.RegularGridInterpolator(
(source_lats, source_lons),
source_data[time_idx, :, :].values,
method=method,
bounds_error=False,
fill_value=np.nan
)
target_coordinates = np.column_stack((self.grid_info['latitudes'], self.grid_info['longitudes']))
interpolated_data[i, :] = interpolation_function(target_coordinates)
# 记录处理信息
if data_name:
print(f" {data_name}: 从第{offset}步开始提取{steps_to_extract}步")
return interpolated_data
def load_grid_information(self) -> bool:
"""
加载目标网格信息
"""
print("1. 加载目标网格信息...")
try:
soil_params = pd.read_csv(self.config['soil_param_file'], delim_whitespace=True, header=None)
self.grid_info['ids'] = soil_params[1].values
self.grid_info['latitudes'] = soil_params[2].values
self.grid_info['longitudes'] = soil_params[3].values
print(f" 网格数量: {len(self.grid_info['latitudes'])}")
print(f" 纬度范围: {np.min(self.grid_info['latitudes']):.3f} ~ {np.max(self.grid_info['latitudes']):.3f}")
print(f" 经度范围: {np.min(self.grid_info['longitudes']):.3f} ~ {np.max(self.grid_info['longitudes']):.3f}")
return True
except Exception as e:
print(f" 错误: 无法加载网格信息 - {e}")
return False
def _apply_unit_conversion(self, data: np.ndarray, conversion_key: str) -> np.ndarray:
"""
应用单位转换函数
参数:
data: 输入数据
conversion_key: 单位转换配置键名
返回:
转换后的数据
"""
if conversion_key in self.config and self.config[conversion_key] is not None:
try:
return self.config[conversion_key](data)
except Exception as e:
print(f" 警告: 单位转换失败 {conversion_key} - {e}")
return data
return data
def process_temperature_data(self) -> bool:
"""
处理气温数据
"""
if 'temperature' not in self.datasets:
return False
print(" 处理气温数据...")
temperature_data = self.datasets['temperature'][self.config['temperature_var']]
# 传递数据名称以获取时间偏移
temperature_interp = self.interpolate_to_target_grid(
temperature_data,
data_name='temperature',
method='linear'
)
# 应用单位转换
temperature_interp = self._apply_unit_conversion(temperature_interp, 'temperature_conv')
self.vic_variables['AIR_TEMP'] = temperature_interp
return True
def process_precipitation_data(self) -> bool:
"""
处理降水数据
"""
if 'precipitation' not in self.datasets:
return False
print(" 处理降水数据...")
precipitation_data = self.datasets['precipitation'][self.config['precipitation_var']]
# 传递数据名称以获取时间偏移
precipitation_interp = self.interpolate_to_target_grid(
precipitation_data,
data_name='precipitation',
method='linear'
)
# 应用单位转换
precipitation_interp = self._apply_unit_conversion(precipitation_interp, 'precipitation_conv')
self.vic_variables['PREC'] = precipitation_interp
return True
def process_pressure_data(self) -> bool:
"""
处理气压数据
"""
if 'pressure' not in self.datasets:
return False
print(" 处理气压数据...")
pressure_data = self.datasets['pressure'][self.config['pressure_var']]
# 传递数据名称以获取时间偏移
pressure_interp = self.interpolate_to_target_grid(
pressure_data,
data_name='pressure',
method='linear'
)
# 应用单位转换
pressure_interp = self._apply_unit_conversion(pressure_interp, 'pressure_conv')
self.vic_variables['PRESSURE'] = pressure_interp
return True
def process_shortwave_radiation(self) -> bool:
"""
处理短波辐射数据
"""
if 'shortwave' not in self.datasets:
return False
print(" 处理短波辐射...")
shortwave_data = self.datasets['shortwave'][self.config['shortwave_var']]
# 传递数据名称以获取时间偏移
shortwave_interp = self.interpolate_to_target_grid(
shortwave_data,
data_name='shortwave',
method='linear'
)
# 应用单位转换
shortwave_interp = self._apply_unit_conversion(shortwave_interp, 'shortwave_conv')
self.vic_variables['SWDOWN'] = shortwave_interp
return True
def process_longwave_radiation(self) -> bool:
"""
处理长波辐射数据
"""
# 优先使用观测的长波辐射
if ('longwave' in self.datasets and
self.config.get('longwave_var') and
self.config['longwave_var'] in self.datasets['longwave'].variables):
print(" 处理长波辐射(观测)...")
longwave_data = self.datasets['longwave'][self.config['longwave_var']]
# 传递数据名称以获取时间偏移
longwave_interp = self.interpolate_to_target_grid(
longwave_data,
data_name='longwave',
method='linear'
)
# 应用单位转换
longwave_interp = self._apply_unit_conversion(longwave_interp, 'longwave_conv')
self.vic_variables['LWDOWN'] = longwave_interp
return True
else:
# 使用简化公式估算长波辐射
print(" 使用简化公式估算长波辐射...")
if 'temperature' in self.datasets:
temperature_data = self.datasets['temperature'][self.config['temperature_var']]
# 传递数据名称以获取时间偏移
temperature_k_interp = self.interpolate_to_target_grid(
temperature_data,
data_name='temperature',
method='linear'
)
# 使用简化公式计算长波辐射
estimated_longwave = self.estimate_incoming_longwave_radiation(temperature_k_interp)
self.vic_variables['LWDOWN'] = estimated_longwave
return True
print(" 警告: 无法处理长波辐射数据")
return False
def process_humidity_data(self) -> bool:
"""
处理湿度数据并计算水汽压
"""
if 'humidity' not in self.datasets or 'PRESSURE' not in self.vic_variables:
return False
print(" 计算水汽压...")
humidity_data = self.datasets['humidity'][self.config['humidity_var']]
# 传递数据名称以获取时间偏移
humidity_interp = self.interpolate_to_target_grid(
humidity_data,
data_name='humidity',
method='linear'
)
# 应用单位转换
humidity_interp = self._apply_unit_conversion(humidity_interp, 'humidity_conv')
# 计算水汽压 (注意单位: PRESSURE是kPa, 需要转换为Pa)
vapor_pressure = self.calculate_vapor_pressure(
humidity_interp,
self.vic_variables['PRESSURE'] * 1000
)
self.vic_variables['VP'] = vapor_pressure
return True
def process_wind_data(self) -> bool:
"""
处理风速数据
"""
if 'wind' not in self.datasets:
return False
print(" 处理风速数据...")
wind_data = self.datasets['wind'][self.config['wind_var']]
# 传递数据名称以获取时间偏移
wind_interp = self.interpolate_to_target_grid(
wind_data,
data_name='wind',
method='linear'
)
# 应用单位转换
wind_interp = self._apply_unit_conversion(wind_interp, 'wind_conv')
self.vic_variables['WIND'] = wind_interp
return True
def generate_vic_forcing_files(self) -> bool:
"""
生成VIC格式的驱动文件
"""
print("4. 生成VIC驱动文件...")
output_dir = self.config['output_dir']
os.makedirs(output_dir, exist_ok=True)
# VIC变量顺序
vic_var_order = self.vic_var_order
n_grid_cells = len(self.grid_info['latitudes'])
print(f" 输出目录: {output_dir}")
print(f" 网格点数: {n_grid_cells}")
print(f" 时间步数: {self.n_time_steps}")
# 为每个网格点生成驱动文件
file_count = 0
for grid_index in range(n_grid_cells):
current_lat = self.grid_info['latitudes'][grid_index]
current_lon = self.grid_info['longitudes'][grid_index]
current_grid_id = self.grid_info['ids'][grid_index]
# 构建文件名
filename = f"forcing_{current_lat:.6f}_{current_lon:.6f}"
file_path = os.path.join(output_dir, filename)
try:
# 使用二进制模式写入, 避免编码问题
with open(file_path, 'w', encoding='utf-8') as file_handler:
for time_index in range(self.n_time_steps):
data_line = []
for variable_name in vic_var_order:
if variable_name in self.vic_variables:
variable_data = self.vic_variables[variable_name]
value = float(variable_data[time_index, grid_index])
# 数据有效性检查
if np.isnan(value) or np.isinf(value):
value = 0.0
data_line.append(f"{value:.4f}")
else:
data_line.append("0.0000")
file_handler.write(" ".join(data_line) + "\n")
file_count += 1
if file_count % 100 == 0:
print(f" 已生成 {file_count}/{n_grid_cells} 个文件")
except Exception as e:
print(f" 警告: 生成文件 {filename} 失败 - {e}")
continue
# 生成网格信息元数据文件
self._generate_grid_metadata_file(output_dir)
print(f" 共生成 {file_count}/{n_grid_cells} 个驱动文件")
return file_count > 0
def close_datasets(self):
"""
关闭所有打开的数据集
"""
for name, dataset in self.datasets.items():
try:
dataset.close()
except:
pass
def load_meteorological_data(self) -> bool:
"""
加载气象强迫数据 - 基于以下算法
1. 按小时 (忽略分钟)读取各变量的时间, 找出共同小时范围, 以及时间步长
2. 将各变量的起始小时与共同起始小时进行比较, 计算时间偏移
"""
print("2. 加载气象强迫数据并计算时间偏移...")
try:
# 加载所有数据集
file_mappings = [
('temperature', 'temperature_file', 'temperature_var'),
('pressure', 'pressure_file', 'pressure_var'),
('humidity', 'humidity_file', 'humidity_var'),
('wind', 'wind_file', 'wind_var'),
('shortwave', 'shortwave_file', 'shortwave_var'),
('precipitation', 'precipitation_file', 'precipitation_var')
]
for ds_name, file_key, var_key in file_mappings:
if (file_key in self.config and
self.config[file_key] and
os.path.exists(self.config[file_key])):
ds = xr.open_dataset(self.config[file_key])
# 检查变量是否存在
if self.config[var_key] in ds.variables:
self.datasets[ds_name] = ds
print(f" {ds_name}: {os.path.basename(self.config[file_key])}")
else:
print(f" 警告: {self.config[file_key]} 中无变量 {self.config[var_key]}")
ds.close()
# 可选的长波辐射
if ('longwave_file' in self.config and
self.config['longwave_file'] and
os.path.exists(self.config['longwave_file'])):
ds_lw = xr.open_dataset(self.config['longwave_file'])
if (self.config.get('longwave_var') and
self.config['longwave_var'] in ds_lw.variables):
self.datasets['longwave'] = ds_lw
print(f" longwave: {os.path.basename(self.config['longwave_file'])}")
else:
ds_lw.close()
if not self.datasets:
print(" 错误: 未加载任何有效的气象数据")
return False
# 时间处理算法实现
# 按小时 (忽略分钟)读取各变量的时间, 找出共同小时范围
all_start_hours = []
all_end_hours = []
print(" 各数据集时间范围:")
for ds_name, dataset in self.datasets.items():
if hasattr(dataset, 'time') and hasattr(dataset.time, 'values'):
time_coords = dataset.time.values
if len(time_coords) > 0:
# 转换为pandas时间戳
if isinstance(time_coords[0], np.datetime64):
start_time = pd.Timestamp(time_coords[0])
end_time = pd.Timestamp(time_coords[-1])
else:
try:
start_time = pd.to_datetime(str(time_coords[0]))
end_time = pd.to_datetime(str(time_coords[-1]))
except:
continue
# 输出原始时间范围
print(f" {ds_name}: {start_time} ~ {end_time} ({len(time_coords)}步)")
# 将时间精度降低到小时 (忽略分钟)
start_hour = start_time.replace(minute=0, second=0, microsecond=0)
end_hour = end_time.replace(minute=0, second=0, microsecond=0)
# 结束时间加1小时, 确保包含最后一个完整小时
end_hour += pd.Timedelta(hours=1)
all_start_hours.append(start_hour)
all_end_hours.append(end_hour)
if not all_start_hours or not all_end_hours:
print(" 警告: 无法确定共同时间范围")
return False
# 共同小时范围 = 最晚开始小时 ~ 最早结束小时
common_start_hour = max(all_start_hours)
common_end_hour = min(all_end_hours)
# 计算时间步长 (小时数)
self.n_time_steps = int((common_end_hour - common_start_hour).total_seconds() / 3600)
print(f" 共同小时范围: {common_start_hour} ~ {common_end_hour}")
print(f" 时间步长 (小时数): {self.n_time_steps}")
# 将各变量的起始小时与共同起始小时进行比较, 计算时间偏移
self.time_offsets = {}
print(" 各变量时间偏移计算:")
for ds_name, dataset in self.datasets.items():
if hasattr(dataset, 'time') and hasattr(dataset.time, 'values'):
time_coords = dataset.time.values
if len(time_coords) > 0:
if isinstance(time_coords[0], np.datetime64):
var_start = pd.Timestamp(time_coords[0])
else:
var_start = pd.to_datetime(str(time_coords[0]))
# 计算变量起始小时
var_start_hour = var_start.replace(minute=0, second=0, microsecond=0)
# 计算偏移 (小时): 变量起始小时早于共同起始小时多少小时
if var_start_hour < common_start_hour:
# 如果变量起始早于共同起始, 偏移为负 (需要跳过前面的数据)
offset_hours = int((common_start_hour - var_start_hour).total_seconds() / 3600)
else:
# 如果变量起始晚于共同起始, 偏移为0 (从变量的第一个数据开始)
offset_hours = 0
# 验证偏移后的数据是否足够
total_var_steps = len(time_coords)
if offset_hours + self.n_time_steps > total_var_steps:
print(f" 警告: {ds_name} 数据不足, 需要 {offset_hours + self.n_time_steps} 步, 但只有 {total_var_steps} 步")
# 调整该变量的有效时间步数
available_steps = total_var_steps - offset_hours
if available_steps > 0:
print(f" 将使用前 {available_steps} 步数据")
else:
print(f" 无可用数据")
self.time_offsets[ds_name] = offset_hours
print(f" {ds_name}: 偏移 = {offset_hours} 小时")
print(f" 最终时间步长: {self.n_time_steps}")
return True
except Exception as e:
print(f" 错误: 加载气象数据失败 - {e}")
return False
def _generate_grid_metadata_file(self, output_dir: str):
"""
生成网格信息元数据文件
"""
metadata_filepath = os.path.join(output_dir, "vic_forcing_info.txt")
try:
with open(metadata_filepath, 'w', encoding='utf-8') as meta_file:
# 写入文件头信息
meta_file.write("=" * 60 + "\n")
meta_file.write("VIC模型驱动数据信息文件\n")
meta_file.write("=" * 60 + "\n\n")
# 1. 生成信息
meta_file.write("1. 生成信息\n")
meta_file.write(f" 生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
meta_file.write(f" 总网格点数: {len(self.grid_info['latitudes'])}\n")
meta_file.write(f" 总时间步数: {self.n_time_steps}\n\n")
# 2. 时间偏移信息
meta_file.write("2. 各变量时间偏移(小时)\n")
for ds_name, offset in self.time_offsets.items():
total_steps = len(self.datasets[ds_name].time) if ds_name in self.datasets else "未知"
meta_file.write(f" {ds_name:15s}: 偏移 = {offset:2d} 小时, 总步数 = {total_steps}\n")
meta_file.write("\n")
# 3. 变量信息
meta_file.write("3. 输出变量信息\n")
meta_file.write(" 变量顺序: " + ' '.join([f"{var}" for var in self.vic_var_order]) + "\n")
vic_var_units = {
'AIR_TEMP': '°C',
'PREC': 'mm/时间步',
'PRESSURE': 'kPa',
'SWDOWN': 'W/m²',
'LWDOWN': 'W/m²',
'VP': 'kPa',
'WIND': 'm/s'
}
var_unit_str = ' '.join([f"{var}({vic_var_units.get(var, '未知单位')})" for var in self.vic_var_order])
meta_file.write(f" 变量单位: {var_unit_str}\n\n")
# 4. 网格列表
meta_file.write("4. 网格点详细信息\n")
meta_file.write(" GridID Latitude Longitude Filename\n")
meta_file.write(" " + "-" * 50 + "\n")
for i in range(len(self.grid_info['latitudes'])):
filename = f"forcing_{self.grid_info['latitudes'][i]:.6f}_{self.grid_info['longitudes'][i]:.6f}"
meta_file.write(f" {self.grid_info['ids'][i]:8d} "
f"{self.grid_info['latitudes'][i]:10.6f} "
f"{self.grid_info['longitudes'][i]:10.6f} "
f"{filename}\n")
meta_file.write("\n" + "=" * 60 + "\n")
meta_file.write("重要提示:\n")
meta_file.write("1. 时间处理采用小时级精度, 忽略分钟差异\n")
meta_file.write("2. 各变量根据时间偏移量提取数据\n")
meta_file.write("3. NaN值表示该时间点无有效数据\n")
meta_file.write("=" * 60 + "\n")
print(f" 详细网格元数据文件: {metadata_filepath}")
except Exception as e:
print(f" 警告: 生成网格元数据文件失败 - {e}")
def generate_forcing_data(self) -> bool:
"""
生成VIC驱动数据的主函数
"""
print("=== VIC模型驱动数据生成 (小时级时间对齐) ===")
start_time = datetime.now()
try:
# 1. 加载网格信息
if not self.load_grid_information():
return False
# 2. 加载气象数据并计算时间偏移
if not self.load_meteorological_data():
return False
# 3. 处理各个气象变量
print("3. 处理气象变量...")
# 处理顺序很重要: 气压和温度需要先处理, 因为其他变量依赖它们
processing_steps = [
(self.process_temperature_data, "气温"),
(self.process_pressure_data, "气压"),
(self.process_precipitation_data, "降水"),
(self.process_shortwave_radiation, "短波辐射"),
(self.process_humidity_data, "湿度"),
(self.process_wind_data, "风速"),
(self.process_longwave_radiation, "长波辐射")
]
success_count = 0
for process_func, desc in processing_steps:
if process_func():
success_count += 1
print(f" {desc}处理完成")
else:
print(f" {desc}处理跳过")
# 检查必需变量
essential_vars = ['AIR_TEMP', 'PREC', 'PRESSURE', 'SWDOWN']
missing_essential = [var for var in essential_vars if var not in self.vic_variables]
if missing_essential:
print(f" 错误: 缺少必需变量: {missing_essential}")
return False
# 4. 生成驱动文件
if not self.generate_vic_forcing_files():
return False
# 5. 清理资源
self.close_datasets()
processing_time = datetime.now() - start_time
# 输出时间信息摘要
print(f"\n时间处理摘要:")
print(f" 最终时间步长: {self.n_time_steps}")
print(f" 各变量时间偏移: {self.time_offsets}")
print(f"=== 驱动数据生成完成! 总耗时: {processing_time} ===")
return True
except Exception as e:
print(f"=== 驱动数据生成失败: {e} ===")
import traceback
traceback.print_exc()
self.close_datasets()
return False
# 完整使用流程示例
if __name__ == "__main__":
print("VIC模型驱动数据生成工具")
print("功能: 将气象强迫数据转换为VIC模型输入格式")
# 创建配置
config = {
# 目标网格信息
'soil_param_file': "../soil/soil_param.txt",
# 输入文件配置 (注意: 这些文件应该有重叠的时间范围)
'temperature_file': "./forcing_data/temperature.nc",
'precipitation_file': "./forcing_data/precipitation.nc",
'pressure_file': "./forcing_data/pressure.nc",
'shortwave_file': "./forcing_data/shortwave_radiation.nc",
'longwave_file': "./forcing_data/longwave_radiation.nc", # 可选
'humidity_file': "./forcing_data/specific_humidity.nc",
'wind_file': "./forcing_data/wind_speed.nc",
# 变量名映射
'temperature_var': 'TLML',
'precipitation_var': 'PRECTOT',
'pressure_var': 'PS',
'shortwave_var': 'SWGDN',
'longwave_var': 'LWGAB', # 可选
'humidity_var': 'QLML',
'wind_var': 'SPEED',
# 单位转换函数 (如果前处理已完成转换, 设为None)
'temperature_conv': lambda x:x-273.15, # K -> °C
'precipitation_conv': lambda x:x*3600, # kg/m²/s -> mm/h
'pressure_conv': lambda x:x/1000, # Pa -> kPa
'shortwave_conv': None, # 通常无需转换
'longwave_conv': None, # 通常无需转换
'humidity_conv': None, # 通常无需转换
'wind_conv': None, # 通常无需转换
# 输出配置
'output_dir': "./forcings"
}
# 初始化生成器
generator = VICForcingGenerator(config)
# 生成驱动数据
success = generator.generate_forcing_data()
# 输出结果
if success:
print(f"\n生成成功, 输出文件:")
print(f" - 驱动数据文件: {config['output_dir']}/forcing_*")
print(f" - 网格信息文件: {config['output_dir']}/vic_forcing_info.txt")
print(f"\n下一步: 使用生成的强迫数据和配置文件运行VIC模型")
else:
print("\n生成失败, 请检查配置和输入数据")7. 修改全局文件
全局文件定义模拟时间步长、时段、土壤层次、文件路径等关键参数。为了获取全局文件global_param.txt,可参考官方示例模板,根据实际研究需求修改模拟时段和文件路径。
# VIC Global Parameter File for Lower Yangtze River Basin Simulation
# Created based on FindleyLake example, adapted for Lower Yangtze River Basin 2024 simulation
# Notice: xxx should be replaced with your user name, or you can choose other specified path
# You can also link the vic_classic.exe to other directories than default installation directory
# Run VIC simulation: ./vic_classic.exe -g global_param.txt
# 时间步长设置
NLAYER 3 # 土壤层数, 即soil_param.txt中的层数
NODES 3 # 土壤热力学节点数
MODEL_STEPS_PER_DAY 24
SNOW_STEPS_PER_DAY 24
RUNOFF_STEPS_PER_DAY 24
# 模拟时段
STARTYEAR 2024
STARTMONTH 1
STARTDAY 1
ENDYEAR 2024
ENDMONTH 1
ENDDAY 1
# 物理过程选项
FULL_ENERGY TRUE
FROZEN_SOIL FALSE
AERO_RESIST_CANSNOW AR_406
# 驱动数据设置
FORCING1 /home/xxx/VIC-5.1.0/vic/drivers/classic/forcings/forcing_
FORCE_FORMAT ASCII
FORCE_TYPE AIR_TEMP temp
FORCE_TYPE PREC prec
FORCE_TYPE PRESSURE air_pressure
FORCE_TYPE SWDOWN shortwave
FORCE_TYPE LWDOWN longwave
FORCE_TYPE VP vapor_pressure
FORCE_TYPE WIND wind
FORCE_STEPS_PER_DAY 24
FORCEYEAR 2024
FORCEMONTH 1
FORCEDAY 1
GRID_DECIMAL 6
WIND_H 10.0
# 参数文件路径
SOIL /home/xxx/VIC-5.1.0/vic/drivers/classic/soil_param.txt
VEGLIB /home/xxx/VIC-5.1.0/vic/drivers/classic/veg_lib_IGBP.txt
VEGPARAM /home/xxx/VIC-5.1.0/vic/drivers/classic/veg_param.txt
# 植被参数设置
ROOT_ZONES 3 # 根系分区数, 与veg_param.txt中的根区定义一致
VEGLIB_FCAN FALSE
VEGPARAM_LAI TRUE
VEGPARAM_FCAN FALSE
VEGPARAM_ALB TRUE
LAI_SRC FROM_VEGPARAM
FCAN_SRC FROM_DEFAULT
ALB_SRC FROM_VEGPARAM
# 网格设置
EQUAL_AREA FALSE
RESOLUTION 0.1
SNOW_BAND 1
# 输出设置
RESULT_DIR /home/xxx/VIC-5.1.0/vic/drivers/classic/output/
OUTFILE fluxes
COMPRESS FALSE
OUT_FORMAT ASCII
AGGFREQ NDAYS 1
# 输出变量 - 选择典型水文变量
OUTVAR OUT_PREC
OUTVAR OUT_EVAP
OUTVAR OUT_RUNOFF
OUTVAR OUT_BASEFLOW
OUTVAR OUT_SWE
OUTVAR OUT_SOIL_MOIST
OUTVAR OUT_SOIL_TEMP
OUTVAR OUT_AIR_TEMP
OUTVAR OUT_SENSIBLE
OUTVAR OUT_LATENT8. 安装VIC模式并运行
完成输入文件制备后,按以下步骤安装和运行VIC模型:
wget https://github.com/UW-Hydro/VIC/archive/refs/tags/5.1.0.tar.gz
tar -zxvf 5.1.0.tar.gz
cd VIC-5.1.0/vic/drivers/classic/
make
./vic_classic.exe –v将输入文件置于正确路径后执行模拟:
./vic_classic.exe -g global_param.txt成功运行后将显示"Completed running VIC Classic",结果输出至全局文件定义的RESULT_DIR目录。
9. 结束语
本教程提供了VIC模型输入数据制备的完整流程,旨在帮助初学者快速入门。需要强调的是,这仅是一个基础参考案例,实际应用中模型的准确模拟还需要经过细致的参数率定和验证。如发现教程中存在任何问题或不足之处,欢迎在项目评论区提出宝贵意见,共同完善本教程内容。


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









