



1 梳理关系
1.梳理哪些实体 什么样的实体(属性、约束等)
2.梳理实体间的关系(一对一、一对多、多对多、无关)
2 关系详解
2.1一对一
2.2一对多
mysql不支持数组类型,不支持(2)
例子:
(1)class(id=1,name=‘math’)student(sid=1 sname=‘qq’ classid=1,sid=2 sname=‘ww’ classid=1);
(2)class(id=1,name=‘math’,ssid=1,2,..)student(sid=1 sname=‘qq’ ,sid=2 sname=‘ww’ );
redis支持(2)
2.3多对多
一个学生-多门课
一门课-多个学生

3 查询进阶
3.1查询搭配插入
insert into 插入表名 select *from 查询表名;
查询出的结果集合 列数/类型 要和插入这个表匹配!
3.2聚合查询
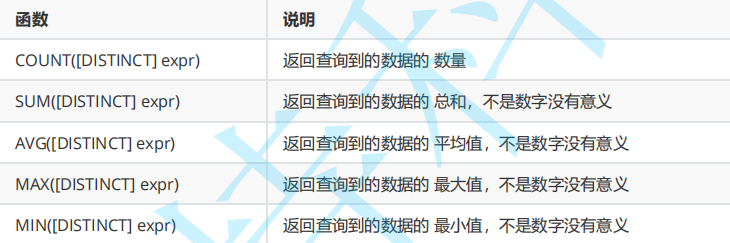
- count
返回查询到的数据的数量(行数)
count(列名/*)
ps.如果列中有null ,就不记做一行
count(distinct 列名)
ps.distinct - 去重
- sum
sum(distinct 列名)/(列名表达式)
这一列必须是数字列/以数字形成的字符串,会先将数据尝试转为double,不可以就会报错!
- avg
avg(distinct 列名)
计算平均值;
- min/max(distinct 列名)
返回最大最小值;
3.3分组查询
使用group by 分组,针对每个分组,再分别进行聚合查询;
group by:针对指定的列进行分组;
select 列名1,列名2 from 表名 group by 列名1;(查询出每一组中一个代表数据)
select 列名1,列名2聚合函数 from 表名 group by 列名1;
搭配条件(1.2.可以联合使用)
1.分组之前 (where)
查询每个岗位平均工资,排除张三的
where...+group by...
2.分组之后(使用having描述条件)
查询每个岗位平均薪资,排除平均薪资超过两万的
group by...+having...(聚合函数条件)
3.4联合查询/多表查询(重点)
ps.数据量庞大(耗时,耗量)/查询复杂(可读性差)
笛卡尔积组合(表1 m*n ,表2 a*b)
【select * from 表1,表2;】
笛卡尔积列数=m+a
笛卡尔积行数=n*b
连接条件 连接两个表排除非法数据的条件
【select * from 表1,表2 where 表1.列1=表2.列1;】
总体分析步骤:
1.先进行笛卡尔积
2.指定连接条件
3.精简一下列/行
4.再进行group by聚合查询
4 内连接 外连接
如果两张表存在对应关系,那么内连接和外连接是一样的
4.1内连接
1.select * from 表1,表2 where 表1.id=表2.id;
2.select * from 表1 (inner) join 表2 on 表1.id=表2.id;
4.2外连接(当两个表数据出现不完全匹配情况)
左外连接(以左侧表为基准,保留左侧表每个数据都在最终结果,如果未在右侧表查询到,则对应列为NULL)
left join
右外连接(同上,以右侧表为基准)
right join
全外连接(mysql不支持,oracle支持)
5 自连接
1.一张表 自己和自己笛卡尔积 比较行与行之间的关系 ps.需要给表用“表名 as 别名”起别名之后再进行笛卡尔积 否则会重名
2.再进行精细筛选
6 子查询
把多个简单sql语句嵌套成一个复杂的
6.1单行子查询
子查询语句必须返回的是某个数值/一行记录!
6.2多行子查询
子查询返回的是多个记录;
7 合并查询
把多个sql查询的结果集合,合并到一起;
允许把多个不同表的查询结果合并在一起(结果集的列要匹配)
select ..... union select.....(可以去重)
select ..... union all select.....(不会去重)
sql中注释语句 “-- ”/“ # ”
配置项差异 :打开mysql终端属性,目标文件找到“my.ini”文件路径,用记事本打开,修改配置项;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









