




 本文探讨了一款全链路跟踪中间件的设计原则,强调其低消耗、低侵入、可开关以及良好的延展性。中间件涵盖了HTTP、MQ、RPC等多种调用场景,并提供了详细的调用链分析,包括TraceId列表、调用链列表、依赖分析图和节点详情页。同时,针对异步调用和线程池问题,引入了特定的解决方案,如使用transmittable-thread-local库,并对各种HTTP客户端和RPC框架进行了改造。
本文探讨了一款全链路跟踪中间件的设计原则,强调其低消耗、低侵入、可开关以及良好的延展性。中间件涵盖了HTTP、MQ、RPC等多种调用场景,并提供了详细的调用链分析,包括TraceId列表、调用链列表、依赖分析图和节点详情页。同时,针对异步调用和线程池问题,引入了特定的解决方案,如使用transmittable-thread-local库,并对各种HTTP客户端和RPC框架进行了改造。
公司内部的业务系统有近千个,基本上很少有比较孤立的;尤其外部系统,即便用户在页面上一个很普通的操作,后台也需要少则几个多则几十个服务协同完成。以前我们定位调用链上的问题方式,基本上都是叫上调用链上所有对服务比较熟悉的技术人员,定位问题费时费力;由此,我们团队决定引入一套全链路跟踪中间件产品。
起初,我们全面调研了社区很多比较成熟的产品之后,发现这些产品与我们公司现存场景多有不符的地方,主要的一点就是我们公司内部应用之间通信方式的多样化。各业务部门之间技术栈极不统一,各业务部门内部的应用之间以及各业务部门应用之间的通信方式自然也多种多样,公开服务的方式包括:REST、RabbitMQ、Dubbo、RMI、Zookeeper等,调用服务的方式包括:OkHttp 2.x、OkHttp 3.x 、Apache HttpClient、Spring RestTemplate、RabbitMQ、Dubbo、RMI、Zookeeper等。我们在自研这套产品过程中,首先参考了谷歌公开的《Dapper大规模分布式系统的跟踪系统》这篇论文,借鉴了社区类似产品的很多思路和理念,像Twitter的Zipkin、阿里的鹰眼、去哪儿网的QTracer、GitHub上开源的PinPoint等产品。

设计目标是企业的设计部门根据设计战略的要求组织各项设计活动预期取得的成果。在产品设计之初,我们就参考了谷歌公开的《Dapper大规模分布式系统的跟踪系统》论文及我们的实际业务场景,制定了如下设计目标:
低消耗:全链路跟踪中间件在接入后应该做到对在线服务的影响足够小,甚至可以忽略不计;
低侵入:不应该让各在线服务显示感受到跟踪API的存在,至少不应该显示侵入业务代码内部,也就是不能出现在类中的import处;
可开关:全链路跟踪中间件的调用链参数传递及日志落地时机要做到在线开关,以避免重大Bug影响在线服务;
延展性:全链路跟踪中间件至少在未来几年的服务体量和集群规模都应该能完全把控住,主要针对的是存储组件。
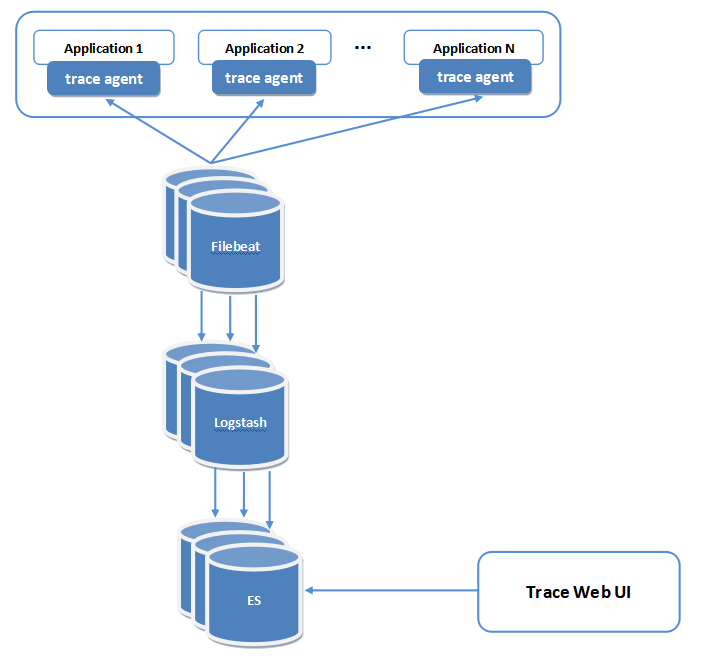
Trace Agent:各业务服务内部的埋点,其中包括各种通信方式的参数传递、配置模块、接入模块等,最终将调用链节点数据以日志形式落地;
Filebeat:采集Trace agent产生的调用链节点日志并送给Logstash;
Logstash:对跟踪日志进行再处理,像属性提取并结构化后输出到ElasticSearch;
ElasticSearch:调用链节点日志的最终存储地,每个节点日志以行为单位进行存储;
Trace Web UI:数据展现页分为四部分,调用链TraceId列表、调用链列表、依赖分析图(基于百度的Echarts)、节点详情页,如下:
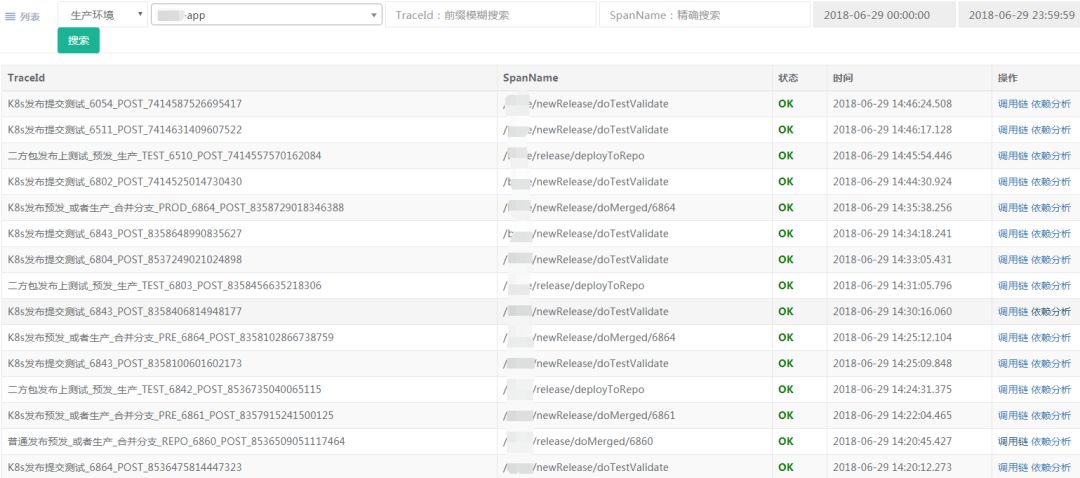
调用链TraceId列表
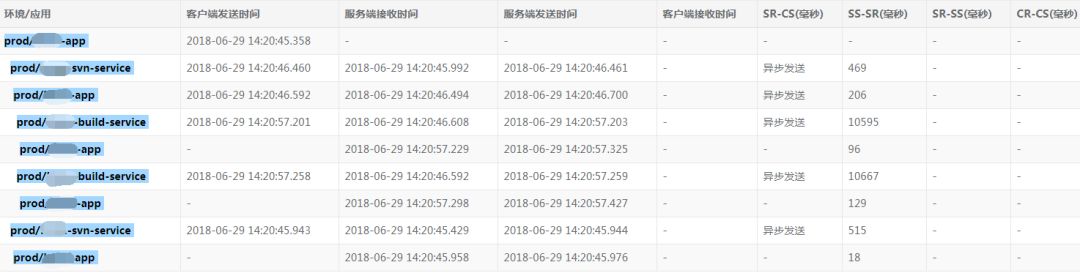
调用链列表
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









