




 集成模型可提高算法准确性和鲁棒性。本文介绍了几种集成方法,包括bootstrapping重采样,bagging生成多个预测器版本聚合预测,重点是降低方差;boosting使模型有衔接性,重点是降低偏置;stacking考虑异质学习器,用元模型组合基础模型,还提及了其训练步骤和缺点。
集成模型可提高算法准确性和鲁棒性。本文介绍了几种集成方法,包括bootstrapping重采样,bagging生成多个预测器版本聚合预测,重点是降低方差;boosting使模型有衔接性,重点是降低偏置;stacking考虑异质学习器,用元模型组合基础模型,还提及了其训练步骤和缺点。
集成模型可以提高算法的准确性和鲁棒性
bootstrapping
- bootstrap方法是指的随机抽样和替换,即重采样,是的模型可以理解重采样中存在的偏差方差和特征
bagging
- bagging生成一个预测器的多个版本,并使用这些版本获得一个聚合预测器。
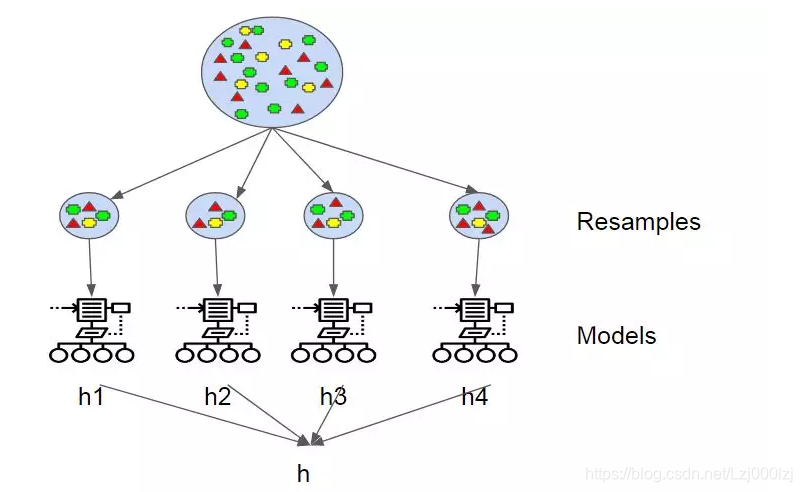
- 当进行分类时,多个模型进行投票。当进行回归分析时,多个模型进行平均。各个模型的权重相同
- bagging的重点是获得一个方差较低的集成模型
boosting
- boosting使模型之间富有衔接性,而不是像bagging使各个模型之间相互独立。
- boosting同样需要bootstrapping,每个模型都规定了下一个模型关注的特性。
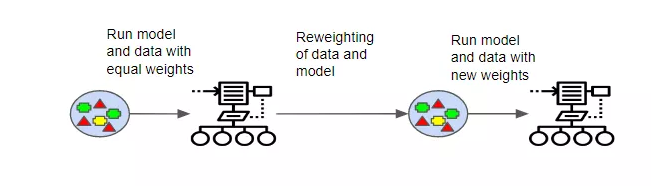
- boost会追踪样本,对于分类错误较多的样本会赋予更重的权重,加以更多次数的迭代训练
- boosting和stackIng的重点是生成一个偏置较小的集成模型(方差也会相应降低)
stacking
- 与以上两种方法不同的是:stacking通常考虑的是异质学习器;并且,stacking学习用元模型组合基础模型,而以上两种方法根据确定性算法组合弱学习器
- 例子:对于某个分类问题,将KNN,SVM,logit回归作为弱学习器,将神经网络作为元模型,将三个弱学习器的输出作为元模型的输入,进行最终的预测
- 当需要拟合由L个弱学习器组成的stacking模型时的步骤:
- 训练数据分为两组
- 用第一组数据拟合L个弱学习器
- 用L个弱学习器对第二组数据进行预测
- 使用弱模型的输出作为元模型的输入拟合元模型
- 缺点:只有一半的数据可以训练基础模型,另一半要用于训练元模型(解决方法:K折交叉训练)

















 170
170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









