




2019年接手优化产品。Sharding-JDBC和MyCat是目前最主流的两款工具,一个轻量嵌入应用,一个独立代理服务,各有擅长。
一、Sharding-JDBC vs MyCat:一张表说清怎么选
| 对比维度 |
Sharding-JDBC(客户端) |
MyCat(服务端) |
| 部署方式 |
嵌入应用(JAR包),无独立服务 |
独立服务器部署(需维护额外进程) |
| 性能 |
高(本地调用,无网络转发) |
中(多一次网络请求,代理层有开销) |
| 应用侵入性 |
低(需引入依赖,配置分片规则) |
无(仅改数据库连接地址) |
| 适用场景 |
新系统开发、微服务架构、对性能敏感 |
老系统改造、多语言应用、需集中管理规则 |
| 学习成本 |
中(理解分片规则配置即可) |
中高(需学MyCat专属配置和运维) |
| 动态调整规则 |
需重启应用(配置改在应用里) |
无需重启(规则在MyCat服务器配置) |
二、背景:手动编码分库分表3个致命坑
手动编码的逻辑很直接:在代码里写死路由规则(比如“按用户ID模8分表”),动态拼接表名执行SQL。但业务一复杂,就会暴露三个致命问题:
1. 代码侵入性极强,维护量爆炸
每个分表的CRUD都要写一套路由逻辑,比如订单表按月份分表,新增、查询、更新都要先算表名后缀。项目里光是分表相关的工具类和重复代码就占了30%,后来新同事接手,光是看懂路由规则就花了一周。
2. 跨表查询复杂到“想死”
查“用户近3个月的订单”,需要手动查3张表,再用代码聚合结果;分页查询时,LIMIT 100,10要从每个分表查110条,汇总后再截取,性能差到离谱。更别说count(*)、group by这些聚合操作,写出来的代码堪比“天书”。
3. 扩容时等于“重做系统”
一开始按user_id%4分4表,后来数据量翻倍想扩到8表,发现所有路由逻辑、SQL拼接、历史数据迁移都要改,相当于重做一遍分表功能,还得停机半天,业务根本受不了。
结论:手动编码只适合“单表分表+规则固定+无跨表查询”的极简单场景(比如内部日志系统),90%的业务系统必须用中间件。
三、Sharding-JDBC:轻量级客户端中间件(推荐新系统用)
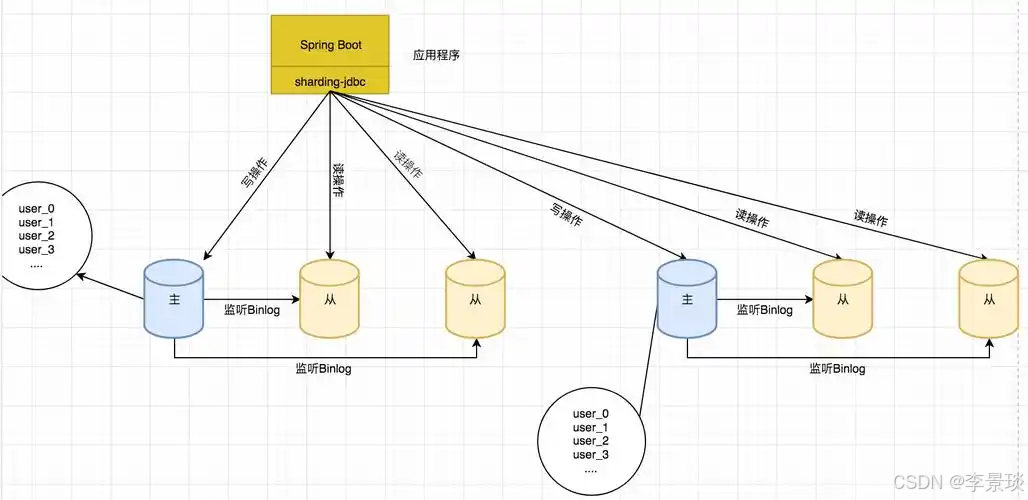
Sharding-JDBC后续发展为Sharding-Sphere,包含sharding-jdbc、Sharding-Proxy、Sharding-Sidecar。
Sharding-JDBC是ShardingSphere生态的核心组件,定位是“增强版JDBC驱动”——不需要独立部署,直接嵌入应用,像用普通数据库一样写SQL,它自动帮你路由到目标库表。
1. 核心优势:轻量、无侵入、性能好
- 嵌入应用:以JAR包形式集成,不用额外部署服务器,运维成本低;
- SQL透明:写SQL时用“逻辑表名”(如order),它自动转成实际表(如order_202310);
- 性能接近原生:本地调用,没有网络转发开销,比服务端中间件快20%+。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 8770
8770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











