






在微服务架构盛行的今天,数据一致性成为了一个关键挑战。当业务数据在MySQL中发生变化时,如何实时同步到其他服务或缓存中,保证数据一致性?
| 方案类型 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|
| 强一致性 | 同步阻塞双写(如2PC/3PC) | 数据绝对一致,适合金融等关键场景 |
性能低,系统复杂度高,可能阻塞 |
| 最终一致性 | 异步补偿(如消息队列+重试) | 高可用,适合高并发场景(如电商) | 短暂不一致,需设计补偿机制 |
| 旁路缓存 | 读操作优先查缓存,未命中查数据库;写操作先更新数据库再删除缓存(Cache-Aside) | 实现简单,减少数据库压力 | 缓存击穿风险,需处理并发写冲突 |
| 读写穿透 | 缓存层自动同步数据库(如Redis Cluster) | 对应用透明,强一致性 | 依赖缓存高可用,写性能受限于数据库 |
| 延迟双删 | 更新数据库后延迟删除缓存(如1秒后二次删除) | 降低并发读旧数据概率 | 延迟时间难确定,可能影响吞吐量 |
| 分布式锁 | 通过锁控制并发(如RedLock) | 彻底避免并发问题 | 性能损耗大,死锁风险 |
阿里巴巴开源的Canal组件为我们提供了完美的解决方案。
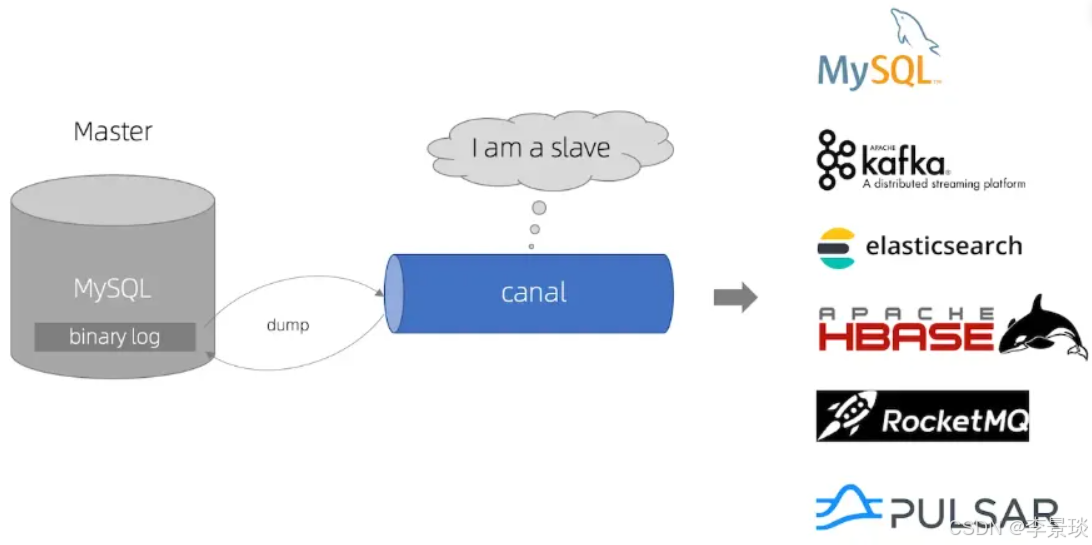
什么是Canal?
Canal是阿里巴巴开源的一个基于MySQL数据库增量日志解析的组件。
它模拟MySQL主从复制的交互协议,伪装成MySQL的从节点,向MySQL主节点发送dump协议,获取到MySQL的二进制日志(binlog)后,再解析为便于理解和使用的数据格式。
Flink CDC 和 Canal 都是基于数据库的 binlog 来捕获数据变更的工具,可以同时使用,但它们通常是作为两个独立的组件来使用的。它们的设计目标和用法有所不同。
- Flink CDC 主要用于在 Flink 中读取数据库的变更数据,并将其用于数据处理和分析。Flink CDC 提供了丰富的 Connector,可以将数据同步到各种目标系统,如 Kafka、Elasticsearch、HBase 等。
- Canal 则是一个轻量级、高可用的 MySQL 数据库镜像组件,它提供了数据库变更数据的订阅和消费功能。Canal 可以用于构建数据同步系统、索引更新系统、流量清洗系统等。
项目架构中的Canal应用
canal是借助于MySQL主从复制原理实现,所以先来了解一下主从复制原理。
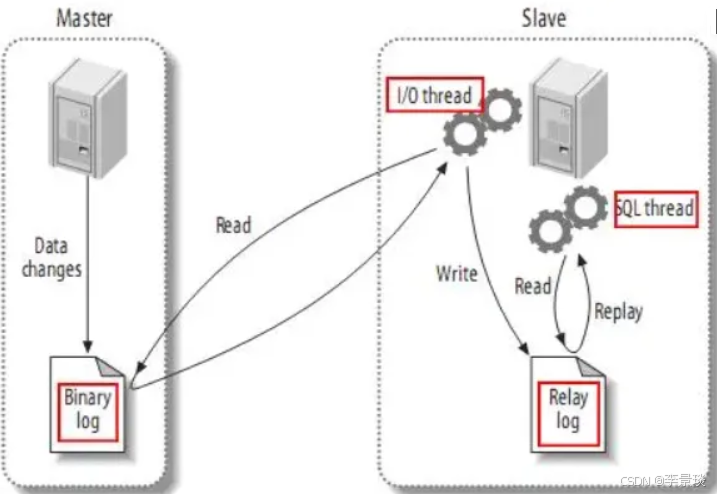
读写分离大概流程可以理解为如下:
- master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);
- slave将master的binary log events拷贝到它的中继日志(relay log);
- slave重做中继日志中的事件,将改变反映它自己的数据。
Canal的工作原理:
- canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流)
Canal组件架构实现
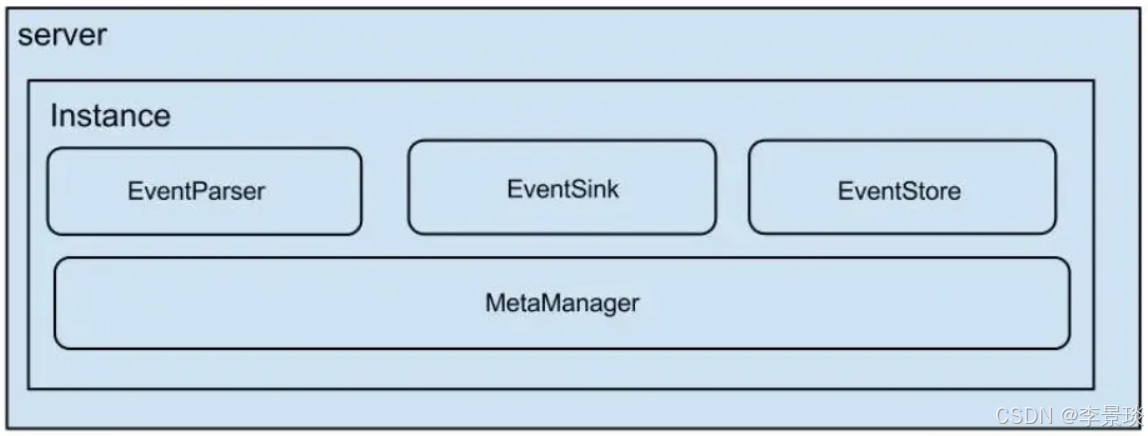
说明:
server代表一个canal运行实例,对应于一个jvm
instance对应于一个数据队列 (1个server对应1..n个instance)
instance模块:
- eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
- eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
- eventStore (数据存储)
- metaManager (增量订阅&消费信息管理器)
在SpringCloud微服务项目中,Canal扮演着数据同步中枢的角色。通过监听MySQL的binlog,实时捕获数据变更事件,并将这些变更推送到需要的服务中,实现数据的最终一致性。
实战:SpringBoot整合Canal(文末附代码链接)
1. 环境准备
首先,确保MySQL已开启binlog功能,并设置为ROW模式
-- 查看binlog配置
SHOW VARIABLES LIKE '%log_bin%';
SHOW VARIABLES LIKE 'binlog_format';
-- 如果未开启,需在my.ini中添加以下配置
server-id=1
log-bin=/path_to_binlog/mysql-bin
binlog_format=ROW
max_binlog_size=100M
同时,创建Canal专用用户
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
2. 服务端部署
下载并安装Canal Server
修改配置文件
conf/example/instance.properties
# 修改为你的MySQL连接信息
canal.instance.master.address=127.0.0.1:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
修改配置文件conf/canal.properties
canal.serverMode = tcp
3. 客户端集成
在SpringBoot项目中添加依赖
<dependency>
<groupId>top.javatool</groupId>
<artifactId>canal-spring-boot-starter</artifactId>
<version>1.2.1-RELEASE</version>
</dependency>
4. 核心实现代码
创建数据变更处理器,监听特定表的数据变化:
@Slf4j
@Component
@CanalTable(value = "bu_user_info") // 对应的数据库表名
public class UserInfoHandler implements EntryHandler<UserInfo> {
@Autowired
private UserInfoCache userInfoCache;
@Override
public void delete(UserInfo t) {
log.info("删除操作: {}", JsonUtil.toJsonString(t));
userInfoCache.del(t.getId());
}
@Override
public void insert(UserInfo t) {
log.info("插入操作: {}", JsonUtil.toJsonString(t));
}
@Override
public void update(UserInfo before, UserInfo after) {
log.info("更新操作,更新前: {},更新后: {}", JsonUtil.toJsonString(before), JsonUtil.toJsonString(after));
userInfoCache.del(after.getId());
userInfoCache.getById(after.getId());
}
}
当用户信息表`bu_user_info`发生变更时,该处理器会自动捕获并处理相应的业务逻辑,如清除缓存、更新索引等。
5. 高级用法:消息队列集成
Mysql binlog -> Canal Server -> MQ(削峰填谷) -> Canal Client
为了提升系统性能和可靠性,我们还可以将Canal与消息队列集成,但
1. top.javatool中canal沒有rabbitMQ、rocketMQ的实现,可阅读源码包
top.javatool.canal.client.spring.boot.autoconfigure,所以需要自己实现
2. 项目中已整合消息驱动,包含rabbitMQ、rocketMQ的实现逻辑,所以只需要自定义实现
top.javatool.canal.client.handler.MessageHandler,即可以将MQ数据给到top.javatool的EntryHandler处理
3. 新增自定义得我消息驱动实现:具体请看
@Configuration
@ConditionalOnProperty(value = CanalProperties.CANAL_MODE, havingValue = "messagedriven")
@Import(ThreadPoolAutoConfiguration.class)
public class MessagedrivenClientAutoConfiguration {
@Bean
public RowDataHandler<List<Map<String, String>>> rowDataHandler() {
return new MapRowDataHandlerImpl(new MapColumnModelFactory());
}
@Bean
public MessageHandler messageHandler(RowDataHandler<List<Map<String, String>>> rowDataHandler, List<EntryHandler> entryHandlers) {
return new SyncFlatMessageHandlerImpl(entryHandlers, rowDataHandler);
}
}
4.接口`EntryHandler<T>` 用法还是清晰简单的,所以将数据转发到EntryHandler处理(具体转发代码看文末代码链接)
如果用rabbitMQ
修改配置文件conf/canal.properties
canal.serverMode = rabbitMQ
rabbitmq.host = localhost:5672
rabbitmq.virtual.host = /
rabbitmq.exchange = fanout-canal
rabbitmq.username = guest
rabbitmq.password = guest
rabbitmq.deliveryMode =
如果用rocketMQ
1.修改配置文件conf/canal.properties
canal.serverMode = rocketMQ
rocketmq.producer.group = producer-group
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = 127.0.0.1:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
2.修改配置文件
conf/example/instance.properties
canal.mq.topic=fanout-canal
这种模式下,Canal Server将变更数据发送到MQ,客户端从MQ消费数据,实现了削峰填谷。
实际应用场景
在常见的项目中,Canal主要用于以下场景
1. 缓存同步:当数据库中的用户信息变更时,自动清除Redis中的缓存,确保数据一致性
2. 搜索引擎同步:将商品信息变更实时同步到Elasticsearch,保证搜索结果的实时性
3. 业务逻辑触发:当订单状态变更时,触发相应的业务流程,如发送通知、更新统计等
性能优化建议
1. 处理器轻量化:确保处理器中的逻辑尽量简单,避免影响数据同步性能
2. 批量处理:对于高并发场景,考虑批量处理数据变更事件
3. 异常处理:完善的异常处理机制,防止因个别数据处理失败影响整体同步流程
结语
通过SpringBoot整合Canal,能够轻松实现MySQL数据的实时同步,大大简化了微服务架构下的数据一致性问题。这一技术方案已经在我们的生产环境中稳定运行,为业务的快速发展提供了强有力的技术支撑。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











