






Mysql使用
-
索引概述:
-
索引是帮助MySQL高效获取数据的数据结构(有序);
-
优势:
-
提高数据检索的效率,降低数据库的IO成本;
-
通过索引列对数据进行排序,降低数据库排序的成本,降低CPU的消耗;
-
-
劣势:
-
实际索引也是一张表,该表保存了主键与索引字段,并指向实体类的记录,所以索引列也是要占用空间的;
-
降低了更新表的速度,INSERT,UPDATE,DELETE操作时,不仅要保存数据,还要更新添加了索引列的字段;更新索引的信息;
-
-
索引结构:
-
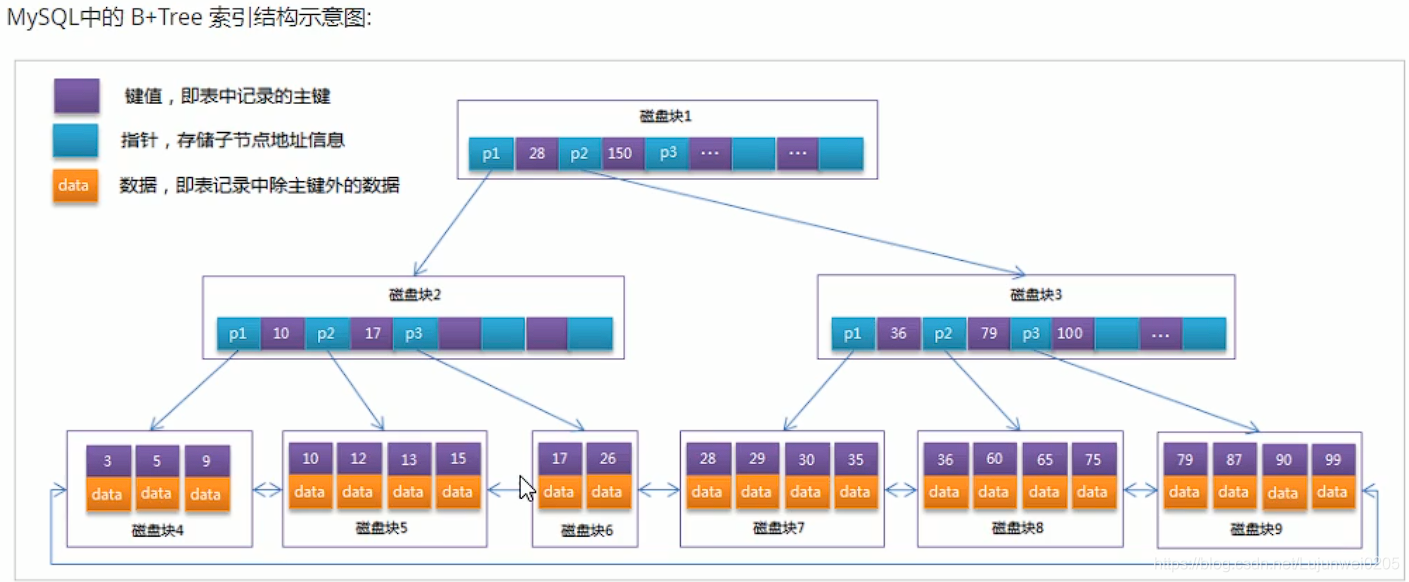
BTREE索引
-
HASH索引
-
R-tree索引
-
Full-text索引
-
-
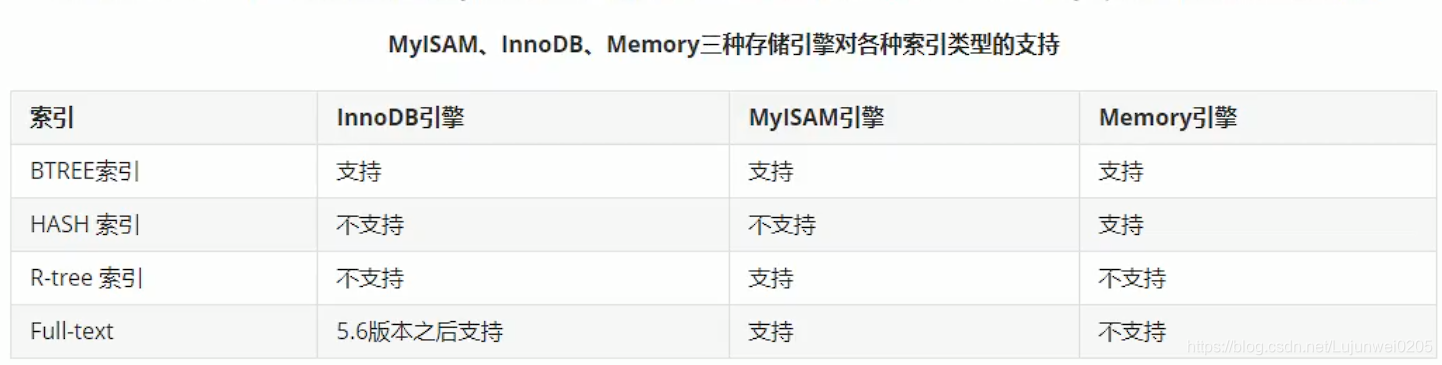


Mysql在原有的B+Tree的基础上,增加了一个指向相邻子节点的链表指针,形成了带有顺序指针的B+Tree,提高区间访问的性能;
索引分类:
-
-
单值索引:一个索引只有一个列;
-
唯一索引:索引列的值必须唯一,但允许有空值;
-
复合索引:一个索引有多个列;
-
主键索引:Mysql创建表时默认创建;不能为空;
-
索引的建立原则:
-
-
查询频次较高,且数据量比较大的表;
-
索引字段的选择:最佳候选列应当从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑选最常用,过滤效果最好的列的组合;
-
使用唯一索引,区分度越高,使用索引的效率越高;
-
索引不是越多越好;
-
使用短字段的索引;
-
利用最左前缀,N个列组合而成的组合索引,那么相当于创建了N个索引,如果查询where子句中使用了组成该索引的前几个字段,那么这条语句可以利用组合索引提升查询效率;
-
视图:
-
-
视图就是一条SELECT语句执行后返回的结果集;
-
视图的结果集可以更新,但是不建议;
-
存储过程:
-
SQL语句的集合;
-
call ---调用存储过程;
-
游标:用来存储查询结果集的数据类型;在存储过程和函数中可以使用光标对结果集进行循环的处理;
-
存储函数:语法:create function ...
-
调用函数:select 函数名称;
触发器:
-
-
触发器是与表相关的数据库对象,指在insert/update/delete之前或者之后触发;执行触发器里面定义的SQL语句集合;
-
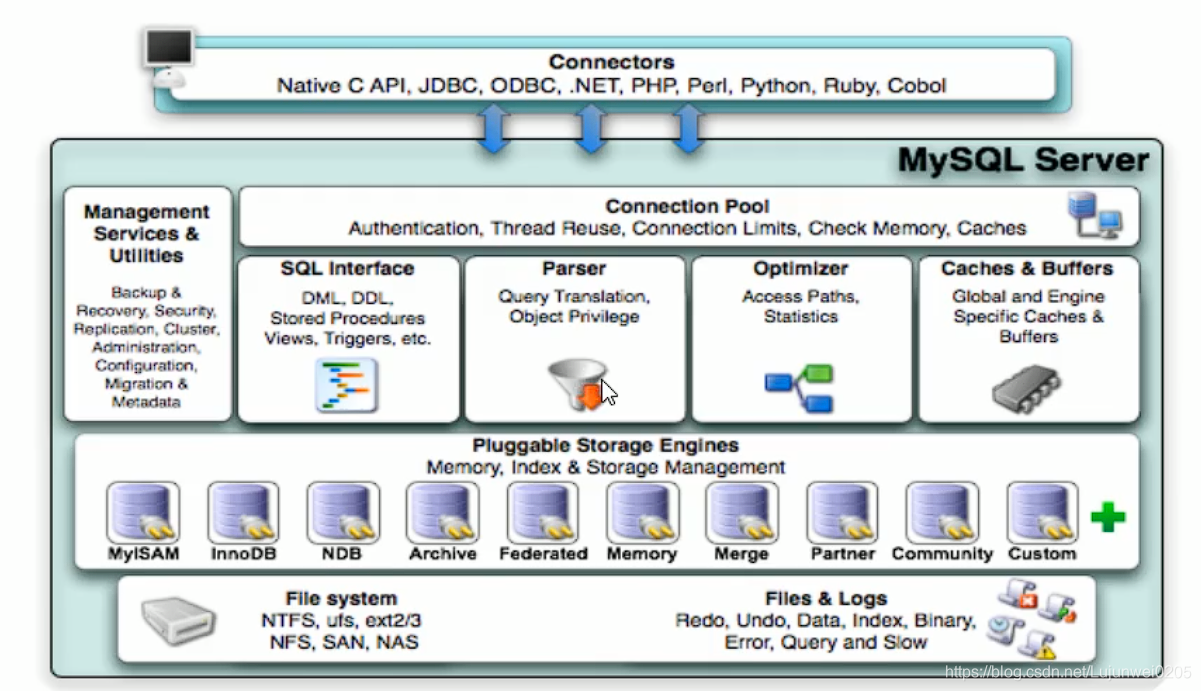
MySQL的体系结构
-
-
连接层:主要完成连接处理,授权认证和相关的方案;
-
服务层:完成大多数的核心服务功能,如SQL接口,SQL的分析和优化;
-
引擎层:负责MySQL中的数据的存储和提取;
-
存储层:主要是将数据存储在文件系统之上,并完成与存储引擎的交互;
-

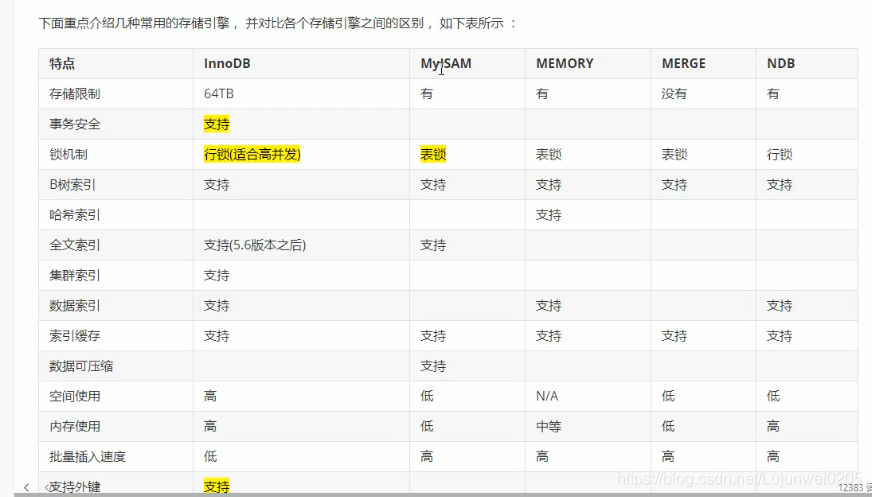
存储引擎:
-
-
存储引擎就是存储数据,建立索引,更新查询数据等等技术的实现方式;存储引擎是基于表的,也叫表类型;
-
MySQL5.0支持的存储引擎包含:InnoDB,MyISAM,MEMORY,MERGE等;
-
-
区别:
-
-
InnoDB表结构存储在.frm文件中,表数据和索引单独保存在.ibd中;
-
优化SQL:
-
-
定位低效率执行SQL
-
慢查询
-
show processlist:查看实时的SQL查询情况;
-
explain分析执行计划;
-
-
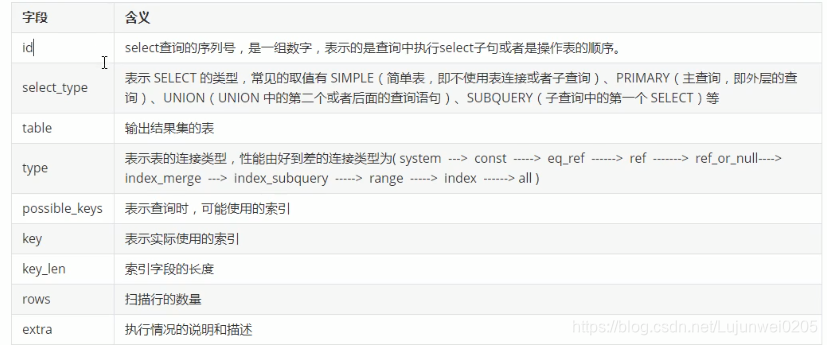
id:
-
-
-
id相同表示加载表的顺序是从上到下;
-
id不同id值越大,优先级越高,越先被执行;
-
-
select_type: 从上到下,效率越来越低;
-
-
-
-
-
访问类型;
-
-
-

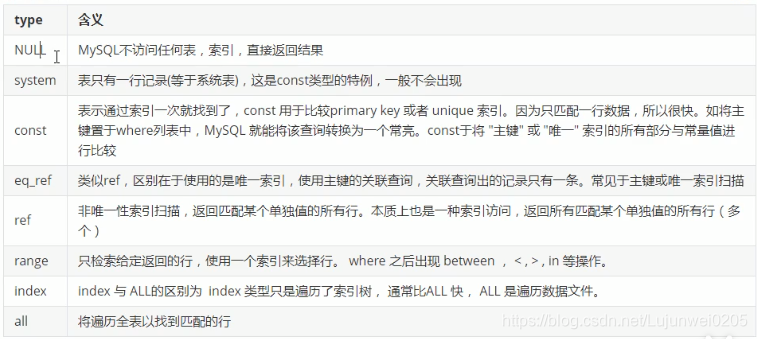
type:
-
-
-
-
访问类型;
-
-
-
-
-
-
-
一般来说,我们需要保证查询至少到range级别,最好达到ref;
-
-
-
-
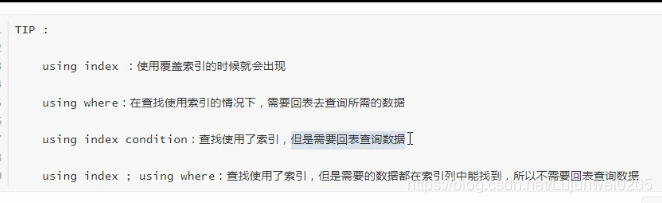
extra:
-
-
-
-
其他的额外执行信息:
-
-
-

-
-
-
SQL分析:
-
-
通过 have_profiles参数,查看当前MySQL是否支持;select @@have_profiling
-
默认profiling是关闭的,可以通过set语句在Session级别开启profiling set profiling =1;
-
show profiles; 查看分析
-
show profile for query queryid; 每个阶段查询的耗时;
-
也可以使用trace分析优化器:
-
-
索引使用:
-
-
全值匹配:对索引中全部的列指定了值,索引生效;
-
最左前缀法则:
-
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始,并且不跳过索引中的列;
-
匹配最左前缀法则,走索引;
-
-
避免索引失效:
-
范围查询右边的列,不使用索引;
-
不用再索引列进行计算;
-
字符串不加单引号,造成索引失效;
-
尽量使用覆盖索引,(只访问索引的查询(索引列完全包含查询列)),减少select * ;
-
-
-
-
-
-
-
-
用or分割的索引,前者有索引,后者没有,则索引失效;
-
like模糊匹配,百分号加在前面会失效;可以使用覆盖索引使索引生效;
-
如果MySQL认为全表扫描比索引快,则会使用全表扫描;某条数据占据的比例特别大,这个时候可能会全表扫描;
-
is null 和 is not null 有时索引失效;
-
in 走索引,not in 不走索引;
-
尽量使用复合索引,少使用单列索引;
-
-
-
-
-
排序方式:
-
第一种:通过返回数据排序,也就是filesort,效率比较低;
-
第二种:通过有序索引顺序扫描直接返回有序数据,为using index,效率较高;
-
可以使用覆盖索引生效;
-
要么全部升序,要么全部降序;
-
需要和索引的字段保持一致;
-
-
filesort 优化:
-
可以适当提高sort_buffer_size 和 max_length_for_sort_data 系统变量
-
-
-
Order By 语句优化:
-
排序方式:
-
第一种:通过返回数据排序,也就是filesort,效率比较低;
-
第二种:通过有序索引顺序扫描直接返回有序数据,为using index,效率较高;
-
可以使用覆盖索引生效;
-
要么全部升序,要么全部降序;
-
需要和索引的字段保持一致;
-
-
filesort 优化:
-
可以适当提高sort_buffer_size 和 max_length_for_sort_data 系统变量;
-

















 192
192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









