




ABSTRACT
四十多年来,数据库研究社区一直在构建存储、访问和更新数据的方法。在用于访问数据的结构和技术的演变过程中,访问方法适应不断变化的硬件和工作负载要求。 今天,即使是工作负载或硬件的微小变化也会导致访问方法的重新设计。 随着数据生成和工作负载多样化呈指数级增长,以及硬件进步带来了更高的复杂性,对新设计的需求一直在增加。 新应用程序的出现引入了新的工作负载需求,数据由越来越复杂和异构的硬件组成的大型系统管理。 因此,开发应用感知和硬件感知访问方法变得越来越重要。
每个研究人员、系统架构师或设计人员在设计新的访问方法时面临的基本挑战是如何最小化,(1) 读取时间 ®,(2) 更新成本 (U),以及(3) 内存(或存储)开销。在本文中,我们推测在优化读取-更新-内存开销时,任何两个区域的优化都会对第三个区域产生负面影响。 我们提出了 RUM 开销的简单模型,并阐明了 RUM 猜想。 我们展示了 RUM 猜想如何体现在最先进的访问方法中,并且我们设想了未来数据系统访问方法的趋势。
INTRODUCTION
-
追踪访问路径。几十年来,选择合适的物理设计(通过静态自动调整、在线调整或自适应)和访问方法一直是数据管理系统的主要研究挑战。我们在存储设备(磁盘、闪存、内存、缓存)上物理组织数据的方式定义并限制了我们读取和更新数据的可能方式。例如,当数据存储在没有索引的堆文件中时,我们必须执行昂贵的扫描来定位我们感兴趣的任何数据。相反,堆文件顶部的树索引使用额外的空间来替换使用更轻量级的索引探针进行扫描。多年来,我们看到了大量令人兴奋和创新的数据结构和算法提案,每一个都针对一组重要的工作负载模式或匹配关键硬件特性而量身定制。应用发展迅速的同时,随着新技术和架构的开发,底层硬件不断变化,并且变化迅速。在设计数据管理软件时,这两种趋势都会带来新的挑战。
-
RUM三者之间的平衡。仔细研究现有的访问方法建议会发现,每个建议都一次又一次地面临相同的基本挑战和设计决策。特别是,研究人员总是试图最小化三个数量和设计参数:(1)读取开销(R),(2)更新开销(U),以及(3)内存(或存储)开销(M ),以下称为 RUM 开销。决定优化哪些开销以及优化到什么程度仍然是设计新访问方法过程中的一个重要部分,尤其是在硬件和工作负载随时间变化的情况下。例如,在 1970 年代,每个数据库算法的关键方面之一是尽量减少磁盘上的随机访问次数;快进 40 年,仍然使用类似的策略,只是现在我们尽量减少对主存的随机访问次数。今天,不同的硬件运行不同的应用程序,但概念和设计选择保持不变。然而,新的挑战来自生成和处理的数据量的指数级增长,以及大量新兴的数据驱动应用程序,这两者都对现有的数据访问方法造成了压力。
-
RUM 猜想:读取、更新、记忆——以牺牲第三个为代价优化两个。理想的解决方案是始终提供最低读取成本、最低更新成本并且在基础数据上不需要额外内存或存储空间的访问方法。 在实践中,数据结构被设计为在三个 RUM 开销之间进行折衷,而最佳设计取决于多种因素,如硬件、工作负载和用户期望。
我们分析了三个开销的下界(读取-更新-内存)给出了一种非常适合最小化每个开销的访问方法,我们表明这种访问方法将对其余的开销产生负面影响。我们将这一观察更进一步,并提出 RUM 猜想:设计访问方法,为其中两个 RUM 开销设置上限,导致第三个开销的硬下限无法进一步降低。例如,为了最小化更新数据的成本,人们会使用基于差异结构的设计,允许许多查询合并更新并避免重新组织数据的成本。然而,这种方法增加了空间开销并阻碍了读取成本,因为现在查询需要在处理期间合并任何相关的未决更新。另一个例子是,可以通过将数据存储在多个不同的物理布局中来最小化读取成本,每个布局都适合于最小化特定工作负载的读取成本。然而,更新和空间成本增加了,因为现在有多个数据副本。最后,可以通过存储最少的元数据来最小化空间成本,因此,在读取和更新数据时要付出增加搜索时间的代价。
三个 RUM 开销形成一个竞争三角形。然而,在数据系统的现代实现中,可以对所有三个进行优化。这种优化可以通过使用固有定义的结构而不是存储详细信息来实现。一个典型的例子是基于块的聚集索引,它通过只存储几个指向页面的指针来减少读取和内存开销(仅当索引元组是存储到与前一个不同的页面),因此构建了一个非常短的树。这种方法能给我们带来良好读取性能的原因是数据聚集在索引属性上。然而,即使在这种理想情况下,我们也必须执行额外的计算才能计算出我们正在搜索的元组的确切位置。本质上,我们使用有关数据的计算和知识来减少 RUM 开销。另一个例子是在位图索引中使用压缩;我们仍然使用额外的计算(压缩/解压缩)来成功减少索引的读取和内存开销。虽然 RUM 开销可以通过计算或工程来减少,但它们的竞争性质体现在许多方法中,并指导我们的 RUM 感知访问方法的路线图。
-
RUM-Aware Access Method Design。接受不存在完美的访问方法并不意味着研究界应该停止努力改进; 恰恰相反。 RUM 猜想为激动人心的研究挑战开辟了道路,以实现创建 RUM 感知和 RUM 自适应访问方法的目标。
未来的数据系统应该包括通用工具,以按照工作负载、应用程序和硬件需要的方式与数据交互,反之亦然。 换句话说,应用程序、工作负载和硬件应该决定我们如何访问我们的数据,而不是我们系统的限制。 这种多功能数据系统将允许未来的数据科学家在正常系统操作期间动态调整数据访问方法。 如果在大数据和硬件之上,我们考虑开发专门的系统和工具来满足数据的需求,调整访问方法变得越来越重要,旨在为每个应用程序提供服务。 随着更多系统的构建,寻找正确访问方法的复杂性也会增加。
-
Contributions。在本文中,我们首次提出 RUM 猜想,作为理解每种访问方法的内在权衡的一种方式。 我们进一步使用该猜想作为设计未来数据系统访问方法的指南。 在本文的其余部分,我们将开辟通往 RUM 感知访问方法的路径:
- 识别和建模 RUM 开销
- 提出 RUM 猜想
- 用最先进的访问方法记录 RUM 猜想的表现
- 使用 RUM 猜想构建未来数据系统的访问方法
上述每一点都为进一步研究数据管理提供了灵感。 找到一种简洁而富有表现力的方法来识别和建模访问方法的基本开销需要从理论角度研究数据管理。 同样,证明 RUM 猜想将扩展这一研究方向。 记录 RUM 猜想的表现需要对访问方法进行新的研究,并在对访问方法进行建模和分类时考虑 RUM 开销。 最后,前三个步骤为构建强大的访问方法提供了必要的研究基础设施。
虽然我们设想这一研究方向将能够构建强大的访问方法,但 RUM 猜想的核心概念实际上是在设计系统时没有灵丹妙药。 构建普遍最佳的访问方法,也不为每个用例构建最佳访问方法是不可行的。 相反,我们设想 RUM 猜想将创造一种趋势,即构建可以有效地变形以支持不断变化的需求和不同的软件和硬件环境的访问方法。 本文的其余部分将一一阐述未来数据系统的 RUM 感知访问方法的四个步骤。
THE RUM OVERHEADS
-
Overheads of Access Methods。在设计访问方法时,了解不同设计选择的含义非常重要。 为此,我们讨论了每个设计决策可能影响的三个基本开销。 访问方法使我们能够读取或更新存储在数据管理系统中的主要数据(以下称为基础数据),可能使用索引等辅助数据(以下称为辅助数据),以提高性能。 访问方法的开销量化了额外的数据访问以支持相对于基础数据的任何操作。
-
Read Overhead (RO)。访问方法的 RO 由在检索必要的基础数据时对辅助数据的数据访问给出。 我们将 RO 称为读取放大:读取的数据总量(包括辅助数据和基础数据)除以检索到的数据量的比率。 例如,在遍历 B±Tree 访问元组时,RO 由访问的总数据(包括遍历树读取的数据和基础数据)与打算读取的基础数据之间的比率给出。
-
Update Overhead (UO)。除了对主数据的更新之外,UO 由应用于辅助数据的更新量给出。 我们将 UO 称为写放大:为一个逻辑更新执行的物理更新的大小除以逻辑更新的大小之间的比率。 在前面的示例中,UO 是通过将更新的数据大小(基础数据和辅助数据)除以更新的基础数据的大小来计算的。
-
Memory Overhead (MO)。MO 是存储辅助数据引起的空间开销。 我们将 MO 称为空间放大,定义为用于辅助数据和基本数据的空间之间的比率,除以用于基本数据的空间。 按照前面的示例,MO 是通过将 B±Tree 的整体大小除以基本数据大小来计算的。
-
Minimizing RUM overheads。理想情况下,在构建访问方法时,所有三个开销都应该是最小的,但是,这取决于应用程序、工作负载和可用技术,它们被优先考虑。 虽然通过最小化读取开销而优化的访问时间通常具有最高优先级,但工作负载或底层技术有时会改变优先级。 例如,耐用性有限的存储(如基于闪存的驱动器)有利于最大限度地减少更新开销,而主内存的缓慢速度和稀缺的缓存容量证明减少空间开销是合理的。 每个开销的理论最小值是使比率等于 1.0,这意味着始终直接读取和更新基本数据,并且不会浪费额外的内存。 然而,同时实现所有三个开销的这些界限是不可能的,因为每次优化总是要付出代价的。
在下面的讨论中,我们使用一个简单但具有代表性的基本数据案例来推断这三个开销及其下限:整数数组。 我们组织这个数据集,由 N (N >> 1) 个固定大小的元素组成,每个元素都有一个值。 每个块都可以通过一个单调递增的 ID blkID 来标识。 工作负载由点查询、更新、插入和删除组成。 我们有目的地提供数据结构的简单示例,以支持以下假设。 这些例子的普遍性在于它们的简单性。
-
Hypothesis。就读取、更新和内存开销之一而言最佳的访问方法无法实现剩余开销的最佳值。
-
Minimizing Only RO。为了最小化 RO,我们将数据组织在一个数组中,并将每个值存储在 blkID=value 的块中。 例如,关系 {1, 17} 存储在一个包含 17 个块的数组中。 第一个块保存值 1,最后一个块保存值 17,中间的每个块都保存一个空值。 RO 现在是最小的,因为我们总是知道在哪里可以找到一个特定的值(如果它存在的话),而且我们只读取有用的数据。 另一方面,数组是稀疏的,具有无界的 MO,因为在一般情况下,我们无法预测曾经插入的最大值是多少。 当我们插入或删除一个值时,我们只更新相应的块。 当我们更改一个值时,我们需要更新两个块:清空旧块并将新值插入新块中,有效地将最坏情况的 UO 增加到两次物理更新以进行一次逻辑更新。
Prop. 1: min(RO) = 1.0 =>UO => 2:0 and MO(无穷)
-
Minimizing Only UO。为了最小化 UO,我们追加每个更新,有效地形成一个不断增加的日志。 这样,我们以不断增加 RO 和 MO 为代价实现了等于1.0 的最小 UO。 请注意,任何减少 RO 的数据重组都会导致 UO 增加。 因此,对于最小 UO,RO 和 MO 都会随着更新的增加而不断增加。
Prop. 2 : min(UO) = 1.0 => RO = 无穷 and MO = 无穷
-
Minimizing Only MO。当最小化 MO 时,不存储辅助数据,基础数据存储为密集数组。 在选择过程中,我们需要扫描所有数据以找到我们感兴趣的值,同时在原地执行更新。 达到了最小 MO=1.0。 然而,RO 现在由关系的大小决定,因为在最坏的情况下需要进行全扫描。 就地更新的 UO 成本也是最优的,因为只有打算更新的基础数据才会被更新。
Prop. 1 :min(MO) = 1.0) => RO = N and UO = 1.0.
3. THE RUM CONJECTURE
实现一项开销的最佳值并不总是与在所有 RUM 开销之间找到一个良好的平衡一样重要。 事实上,在上一节中,我们看到追求最优可能会创建不切实际的访问方法设计。 下一个合乎逻辑的步骤是只为其中一个开销提供固定界限,然而,这提出了如何量化这种优化目标对剩余两个开销的影响的问题。 鉴于我们上面的分析,我们推测不可能同时在所有三个维度上进行优化。
***The RUM Conjecture.*可以为读取、更新和内存开销中的两个设置上限的访问方法还可以为第三个开销设置下限。
换句话说,我们可以选择优先考虑和优化哪两个开销,并通过使第三个开销大于硬性下限来付出代价。 在下一节中,我们通过展示当前解决方案通常针对三种开销之一进行优化来描述 RUM 猜想如何在现有访问方法中体现,而在第 5 节中,我们将讨论 RUM 访问方法的路线图。
RUM IN PRACTICE
RUM 猜想以简洁的方式捕捉了研究人员在构建访问方法时面临的不同优化目标之间的紧张关系。 我们在这里展示了 RUM 权衡的竞争性质,因为它体现在最先进的访问方法中。 不同的访问方法设计可以根据它们的 RUM 余额直观地表示。 RUM 权衡可以看作是一个三维设计空间,或者,如果投影在二维平面上,如图 1 中所示的三角形。每个访问方法都映射到一个点,或者——如果它可以调整为具有不同的 RUM 对某个区域的行为。 表 1 显示了代表性数据结构的时间和大小复杂性,说明了冲突的读取、更新和内存开销。
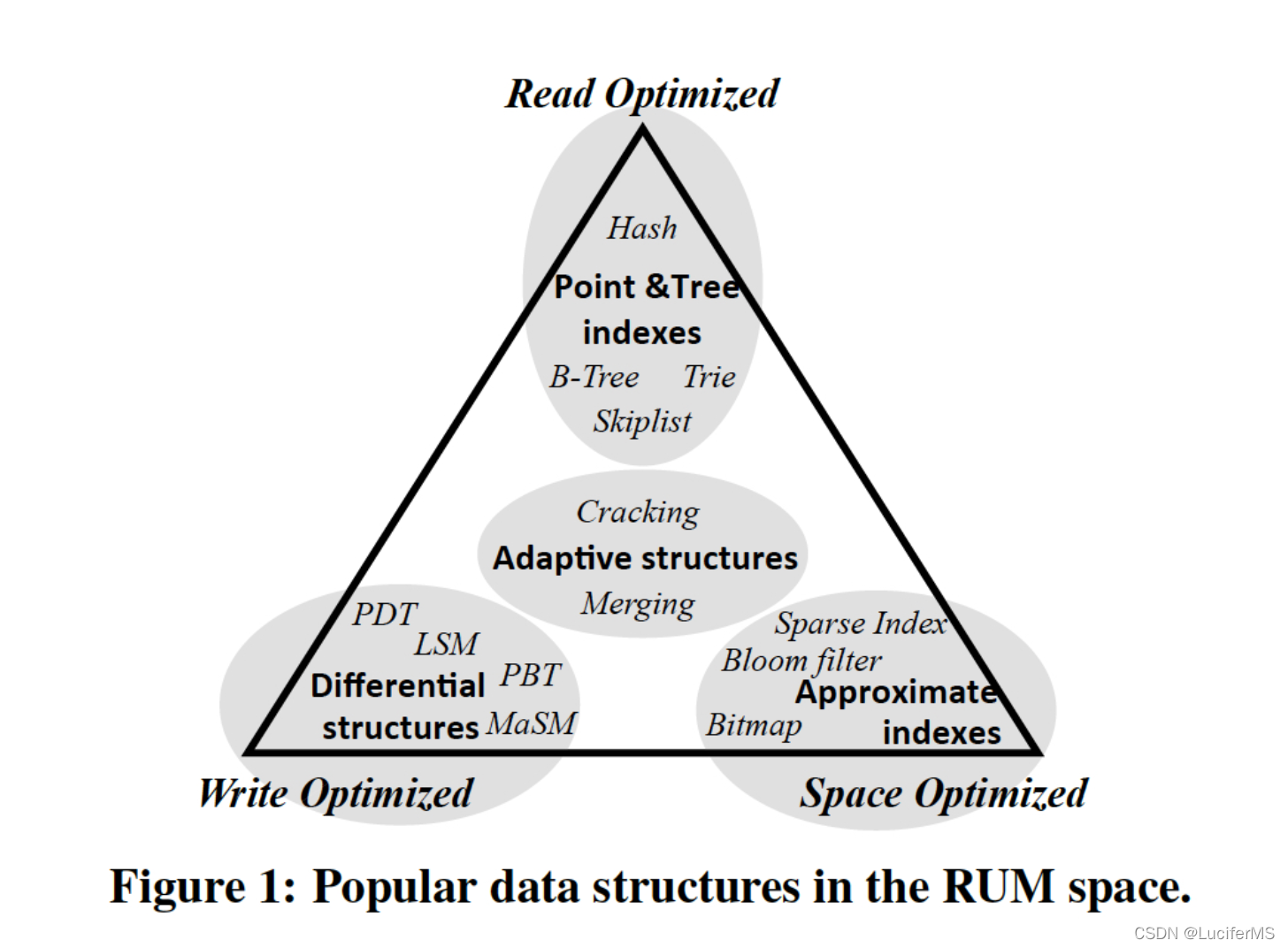
读取优化访问方法(图 1 中的上角) 针对低读取开销进行了优化。 示例包括具有恒定时间访问的索引,例如基于哈希的索引或对数时间结构,例如 B-Trees 、Tries、Prefix B-Trees 和 Skiplists 。 通常,此类访问方法提供快速读取访问,但会增加空间开销并受到频繁更新的影响。
写入优化的差分结构(图 1 中的左角)通过将更新存储在二级差分数据结构中来减少就地更新的写入开销。 基本思想是整合更新并将它们批量应用于基础数据。 示例包括 Log-structured Merge Tree、Partitioned B-tree (PBT)、Materialized Sort-Merge (MaSM) 算法、Stepped Merge 算法和 Positional Differential Tree。 LA-Tree 和 FD-Tree 是写入优化树的两个主要示例,旨在利用闪存,同时尊重其局限性,例如,读写性能之间的不对称性和闪存可以维持的物理更新数量有限。 通常,此类数据结构在更新时提供良好的性能,但会增加读取成本和空间开销。
节省空间的访问方法(图 1 中的右上角)旨在减少存储开销。 示例类别包括压缩技术和有损索引结构(如 Bloom 过滤器)、有损基于哈希的索引(如 count-min sketches)、有损编码位图和近似树索引。 稀疏索引是轻量级二级索引,如 ZoneMaps、Small Materialized Aggregates 和 Column Imprints 属于同一类别。 通常,此类数据结构和方法会显着降低空间开销,但会增加写入成本(例如,使用压缩时),有时还会增加读取成本(例如,稀疏索引)。
自适应访问方法(图 1 中的中间区域)由灵活的数据结构组成,旨在通过使用工作负载访问模式作为指导来逐步平衡 RUM 权衡。大多数现有数据结构都提供了可用于离线平衡 RUM 权衡的可调参数,但是,自适应访问方法可以在更大的设计空间区域内在线平衡权衡。值得注意的建议是数据库破解、自适应合并和自适应索引,它们平衡了读取性能与创建索引的开销。传入的查询指示应该完全填充和调整索引的哪一部分。索引创建开销在一段时间内分摊,它逐渐减少读取开销,同时增加更新开销,慢慢增加内存开销。尽管比传统数据结构灵活得多,但现有的自适应数据结构无法覆盖整个 RUM 频谱,因为它们是为特定类型的硬件和应用程序设计的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HEnzs11q-1642942253606)(/Users/didi/Library/Application Support/typora-user-images/image-20220120205849630.png)]](https://i-blog.csdnimg.cn/blog_migrate/dee7bc045abce2537c2ea9ca125df253.png)
表 1 给出了四种代表性访问方法以及两种数据组织的 RUM 权衡,以说明平衡它们的必要性。内存开销以空间复杂度(索引大小)的形式表示,读取和更新开销以操作的 I/O 复杂度的形式表示。我们区分点查询和范围查询,以便对访问方法进行更详细的分类。我们检查 B+ Trees2、Hash Indexing、ZoneMaps3 和 leveled LSM [36],假设每个 LSM 级别都是具有分支因子 B 的 B±Tree。通常,像 ZoneMaps 这样的稀疏索引提供了最小的访问方法大小,但是,它既不提供最佳点查询性能,也不是最佳范围查询性能。 Hash Indexing 提供最低点查询复杂度,B±Trees 提供最低范围查询复杂度。此外,即使没有任何额外的二级索引,维护排序列也允许使用对数成本进行搜索,但缺点是具有线性更新成本。因此,即使没有辅助数据结构,向数据添加结构也会影响读写行为。我们设想 RUMaccess 方法更进一步,并在数据结构和不同数据组织之间变形,以构建具有可调性能并可以自适应和按需改变行为的访问方法。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rycy8Sxl-1642942253607)(/Users/didi/Library/Application Support/typora-user-images/image-20220121235506680.png)]](https://i-blog.csdnimg.cn/blog_migrate/64c1f3a1c6e3a97875bff74796e15256.png)
内存层次结构。 为了便于展示,前面的讨论假设所有数据对象都存储在同一个存储介质上。 然而,实际系统具有更复杂的内存/存储层次结构,这使得设计和调整访问方法变得更加困难。 数据仅持久存储在层次结构的较低级别,并以各种形式复制到层次结构的所有级别; 每个内存级别经历不同的访问模式,导致不同的读写开销,而每个级别的空间开销取决于缓存了多少数据。
几种方法利用有关内存层次结构的知识来提供更好的读取性能。 Fractal Prefetching B+Trees 使用不同的节点大小进行基于磁盘和内存中的处理,以便在两种情况下都达到最佳状态。 Cachesensitive B+Trees 在物理上将兄弟节点聚集在一起,以减少缓存未命中的数量,并使用偏移量而不是指针来减小节点大小。 当索引基于磁盘时,SB-Trees 以类似的方式运行,而 BW-Tree 和 Masstree 提供了许多与高速缓存、主内存和基于闪存的二级存储相关的优化。 SILT 结合了写优化日志记录、读优化不可变哈希和排序存储,围绕内存层次结构精心设计,以平衡其各个级别的权衡。
然而,RUM 权衡仍然适用于每个级别,如图 2 所示。数据具有最小访问粒度的基本假设适用于当今所有存储介质,包括主存储器、闪存和磁盘; 唯一的区别是访问时间和访问粒度都不同。 RUM 权衡也可以垂直而不是水平查看。 例如,可以通过在前一个级别 n+1 存储更多数据、更新或元数据来减少内存级别 n 的 ROn 读取和 UOn 更新开销,这至少会导致更高的 MOn+1 . 总体而言,我们预计,随着层次结构变得更深,硬件和软件的这种交互会变得越来越复杂,并且硬件趋势会改变一个级别相对于其他级别的相对性能,从而需要对访问方法进行更精细的调整。
从下到上查看层次结构,我们首先有冷存储,今天可能是叠瓦磁盘,或传统的旋转磁盘。 它们之后通常是用于缓冲和读取性能的闪存存储。 下一级是主内存和不同级别的高速缓存。 将来会增加一层额外的非易失性主存储器,或者它将完全取代主存储器。 这种新的存储和内存层次结构的不同层有不同的要求。 更具体地说,叠瓦式磁盘类似于闪存设备,需要最小化更新成本以尊重其内部特性。 另一方面,在设计传统旋转磁盘的访问方法时——位于叠瓦磁盘和层次结构中的闪存之间——我们需要最小化读取开销。 当我们在层次结构中移动更高时,读取性能和索引大小通常比更新成本更重要。
缓存无视访问方法。 构建访问方法的另一种方法是使用缓存忽略算法从设计空间中完全移除内存层次结构。 然而,Cacheoblivious 访问方法通过在读取性能中具有更大的常数因子来实现这一点。 此外,缓存忽略访问方法具有更大的内存开销,因为它们需要更多的指针来保证搜索性能将与内存层次结构正交。 最后,无缓存设计的可调性较差。 为了调整数据结构并能够在读取性能、更新性能和内存消耗之间取得平衡,我们需要具备缓存感知能力。 因此,为了构建 RUM 可调的访问方法,我们必须使用缓存感知设计并考虑内存层次结构的确切形状。
5. BUILDING RUM ACCESS METHODS
几十年来,数据库研究社区一直在重新设计访问方法,试图在 RUM 权衡与硬件、工作负载模式和应用程序的每一次变化之间取得平衡。 因此,每隔几年就会提出新的数据管理技术变体,适应新挑战变得越来越困难。 例如,大多数数据管理软件仍然不适合原生利用固态驱动器、多核和深度非均匀内存层次结构,尽管用于适应过去技术和结构的概念依赖于几十年前提出的想法(如分区,并避免随机访问。换句话说,改变的是人们如何为新环境调整结构和技术。
硬件和应用程序都在快速且持续地变化。 因此,我们需要经常调整数据管理软件以应对不断变化的挑战。 在前面的部分中,我们通过提供对 RUM 开销和 RUM 猜想的直观分析,为 RUM 访问方法奠定了基础。 更进一步,在这里我们提出了必要的研究步骤来设计在 RUM 开销之间具有可变平衡的通用访问方法。 在图 3 中,我们可视化了理想的 RUM 访问方法,它将能够在三个极端之间无缝过渡:读取优化、写入优化和空间优化。 在实践中,以构建能够覆盖整个频谱的单一接入方法为目标可能是不可行的。 相反,另一种方法是构建能够在 RUM 空间中部分导航的多种访问方法,但总体上覆盖整个空间。
研究RUM的权衡。 构建 RUM 访问方法的第一步是扩展第 4 节中的讨论。对实践中 RUM 权衡性质的详细研究将导致基于其 RUM 平衡的访问方法的详细分类。 大多数现有的访问方法可以描述为 RUM 空间中的一个静态点(图 3)。 点的确切位置可能会因某些参数而异(例如,B+Trees 的扇出、PBT 中的分区数、MaSM 中的排序运行数)。 此外,诸如破解之类的自适应索引技术以动态方式运行,但不可调整:当它们接触更多数据时,它们会为数据添加结构,并以更新开销为代价逐渐减少读取开销。

该分析的一个具体结果是收集所有基本构建块和访问方法的策略。 例如,对数访问成本(树、指数增长的日志)、固定访问成本(尝试、哈希表)、辅助数据大小的权衡计算(哈希表的哈希、位图的压缩)和延迟更新(日志结构 方法)。
可调RUM平衡。 使用上述分类和分析,我们可以根据应用需求和硬件特性,做出有根据的决定应该使用哪种访问方法,有效地创建一个强大的访问方法向导。 除此之外,我们还研究了如何构建具有可调行为的访问方法。 这种访问方法不是 RUM 空间中的单点; 相反,它们可以在设计空间的一个区域内移动。
我们设想未来的数据系统具有一套可以轻松适应不同优化目标的访问方法。 例如:
- B+Trees 具有动态调整的参数,包括树高、节点大小和拆分条件,以便在运行时调整树大小、读取成本和更新成本
- 近似(树)索引,通过将更新吸收到可更新的概率数据结构(如商过滤器)中,支持具有低读取性能开销的更新。
- 变形访问方法,一次组合多个形状。 随着传入的查询逐渐向数据添加结构,并在进一步的数据重组变得不可行时构建支持的索引结构。
- 更新友好的位图索引,其中使用逐渐合并的附加、高度可压缩的位向量吸收更新。
- 通过概率数据结构增强的具有迭代日志的访问方法,通过避免以额外空间为代价访问不必要的数据,从而实现更有效的读取和更新。
动态RUM平衡。 我们设想的访问方法可以自动和动态地适应新的工作负载需求动态 RUM 平衡。 我们设想的访问方法可以自动和动态地适应新的工作负载要求
压缩和计算。 与这三个开销之间的紧张关系正交的是,如今在访问数据时,通常使用压缩来减少要移动的数据量。 这种计算(压缩/解压缩)和数据大小之间的权衡不会影响 RUM 猜想的基本性质。 压缩很少仅用于通过内存层次结构传输数据。 相反,现代数据系统主要在压缩数据上运行并尽可能晚地解压缩,通常是在向用户呈现查询的最终答案时。
6. SUMMARY
硬件、应用程序和工作负载的变化一直是重新设计访问方法的主要驱动力,以便正确地进行读取更新内存权衡。 在本文中,我们通过 RUMConjecture 表明,创建最终访问方法是不可行的,因为某些优化和设计选择是相互排斥的。 相反,我们提出了一个数据结构路线图,可以在给定硬件和应用程序参数的情况下进行调整,从而产生新的 RUM 感知访问方法系列。
尽管构建 RUM 访问方法代表着一项巨大的新挑战,但我们认为这是受我们过去的集体努力启发而自然而然的下一步。 过去在数据结构、调优工具、自适应处理和索引以及硬件意识数据库架构等领域的研究是推广概念和原则的初始池。
致谢。 我们感谢 Margo Seltzer、Niv Dayan、Kenneth Bøgh、EPFL 的 DIAS 小组和哈佛的 DASlab 小组提供的宝贵反馈。 这项工作得到了瑞士国家科学基金会和国家科学基金会的部分支持,资助号为 IIS-1452595.
参考资料
- 论文地址:https://stratos.seas.harvard.edu/files/stratos/files/rum.pdf
个人推广
笔者之前在lsm-tree和leveldb上面有一定的开源贡献,后续会持续更新相关的东西给大家。下面是笔者新开的公众号。希望大家多多关注,也希望笔者能持续给大家带来高质量的分享。谢谢大家!
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rL7js2kB-1642942253607)(/Users/didi/Library/Application Support/typora-user-images/image-20220116132659877.png)]](https://i-blog.csdnimg.cn/blog_migrate/ad7e15a562447d77fed08c6cc0840812.png)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









