



 本文深入探讨Python装饰器的原理与应用,涵盖内存管理、作用域、闭包等前置概念,解析装饰器的执行机制,展示如何利用装饰器增强代码功能。
本文深入探讨Python装饰器的原理与应用,涵盖内存管理、作用域、闭包等前置概念,解析装饰器的执行机制,展示如何利用装饰器增强代码功能。
前言
学习装饰器之前必须先理解的四个概念:内存、垃圾回收、作用域、闭包,以上理解后,在编写或者使用装饰器代码可以更得心应手,下面是个人理解装饰器的心得及体会
python内存
对于内存的理解
对象的内存使用,对python而言,万物皆可对象:
- 赋值语句 ,引用和对象,在python中可以使用python内置函数id(),用于返回对象的身份
a = 1 #a引用指向对象1;
print(id(a)) #这里是十进制,返回4536868624
print(hex(id(a))) #这里是十六进制,0x10e6b1f10
- 引用和指针,当a和b同时指向一个int或str类型时,python会缓存这些对象,以便重复使用。当我们创建多个等于1的引用时,实际上是让这些引用指向同一个对象,举个栗子:
a = 1
b = 1
print(id(a))
print(id(b))#打印出的内存地址可见a,b指向同一个内存地址
- 校验是否指向同一个对象,为了检验两个引用是否指向同一个对象,我们可以用is关键字。is用于判断两个引用所指的对象是否相同
a = 2
b = 2
#True
print(a is b)
#True
a = "objgigmsfs"
b = "objgigmsfs"
print(a is b)
#True
a = "very good morning,asf"
b = "very good morning,asf"
print(a is b)
#False
a = [1,2,3,4]
b = [1,2,3,4]
print(a is b)
#False
a = float(9)
b = float(9)
print(a is b)
上述总结:python中,整数和短小的字符指向内存地址相同,以便重复使用,而其他类型的内存地址均存到独立内存地址中,调用时也会调用不同的内存地址
引用计数
在Python中,每个对象都有存有指向该对象的引用总数,即引用计数(reference count)。
我们可以使用sys包中的getrefcount(),来查看某个对象的引用计数。需要注意的是,当使用某个引用作为参数,传递给getrefcount()时,参数实际上创建了一个临时的引用。因此,getrefcount()所得到的结果,会比期望的多1。
因为调用函数的时候传入a,这会让a的引用计数+1
举个栗子:
from sys import getrefcount
ff = [1,2,3]
print(getrefcount(ff)) #返回引用计数为2
mm = ff #这里赋值后,均指向同一个对象(内存地址),下面会讲到
print(getrefcount(mm))#返回引用计数为3
上面对应返回的为2和3,而不是1和2,是因为在调用getrefcount(),是调用的它的镜像,所以它会把它自己的引用也会算进去
此时引用的对象[1,2,3]已经在python内存中了,可以使用python内置函数globals()方法查看
举个栗子:
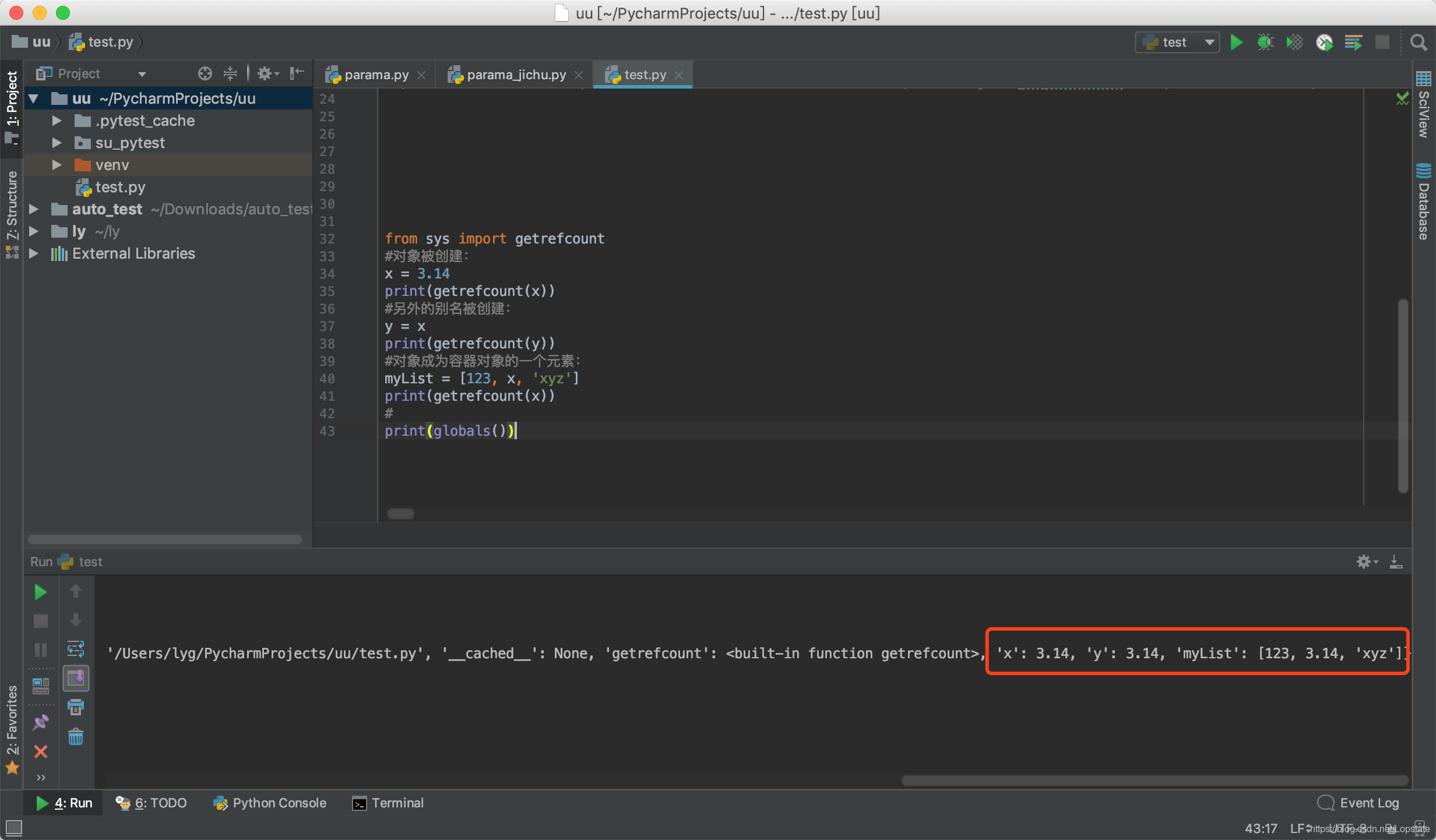
增加引用计数
当对象创建并赋值(将它引用)给变量时,该对象当引用计数被设置为1。
举个栗子:
from sys import getrefcount
#对象被创建:
x = 3.14
print(getrefcount(x)) #返回引用计数为4
#另外的别名被创建:
y = x
print(getrefcount(y))#返回引用计数为5
#对象成为容器对象的一个元素:
myList = [123, x, 'xyz']#返回引用计数为6
print(getrefcount(x))
引用计数减少
对象的引用计数减少的情况:
一个本地引用离开了其作用范围。如fooc()函数结束时,func函数中的局部变量(全局变量不会)
对象的别名被显式销毁:del y
对象的一个别名被赋值给其他对象:x = 123
对象被从一个窗口对象中移除:myList.remove(x)
窗口对象本身被销毁:del myList
del语句,Del语句会删除对象的一个引用,它的语法如下:del obj[, obj2[, …objN]]
例如,在上例中执行del y会产生两个结果:
从现在的名称空间中删除y
x的引用计数减1
举个栗子:
from sys import getrefcount
#对象被创建:
x = 3.14
print(getrefcount(x)) #返回引用计数为4
#另外的别名被创建:
y = x
print(getrefcount(y)) #返回引用计数为5
del y
print(getrefcount(x)) #返回引用计数为4
垃圾回收
垃圾回收时,Python不能进行其它的任务。频繁的垃圾回收将大大降低Python的工作效率。如果内存中的对象不多,就没有必要总启动垃圾回收。所以,Python只会在特定条件下,自动启动垃圾回收。
当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数,当两者当差值高于某个阀值时,垃圾回收才会启动
可以通过gc模块的get_threshold()方法,查看该阈值
举个栗子:
import gc
print(gc.get_threshold())#返回(700, 10, 10),后面的两个10是与分代回收相关的阈值,后面会讲到。700即是垃圾回收启动的阈值。
可以通过gc中的set_threshold()方法重新设置,也可以手动进行垃圾回收
import gc
a=1
gc.collect()
分代回收
Python同时采用了分代(generation)回收的策略
这一策略的基本假设是,存活时间越久的对象,越不可能在后面的程序中变成垃圾。我们的程序往往会产生大量的对象,许多对象很快产生和消失,但也有一些对象长期被使用。出于信任和效率,对于这样一些“长寿”对象,我们相信它们的用处,所以减少在垃圾回收中扫描它们的频率
python将所有对象分为0,1,2三代。所有新建对象都是0代对象。当某一代对象经历垃圾回收,依然存活,那么它就被归入下一代对象。
垃圾回收启动时,一定会扫描所有0代对象。如果0代对象经历过一定次数垃圾回收,那么就启动对0代和1代的扫描清理。当1代也经历过一定次数的垃圾回收后,那么会启动对0,1,2,即对所有对象进行扫描,即上面get_threshold()返回的(700, 10, 10)返回的两个10。也就是说,每10次0代垃圾回收,会配合1次1代的垃圾回收;而每10次1代的垃圾回收,才会有1次的2代垃圾回收
举个栗子:
'''可使用set_threshold()来调整,比如对二代对象扫描更频繁'''
print(gc.get_threshold())#查看当前垃圾回收阀值
gc.set_threshold(700,10,5)#重新设定阀值
print(gc.get_threshold())#再查看
孤独的引用环
引用环的存在会对垃圾回收带来更大的困难,因为引用环可能构成无法使用,但引用计数不为0的对象
举个栗子:
a = []
b = [a]
a.append(b)
上面b引用a对象,a又通过python内置方法引用a,会造成a,b互相引用,这就会造成垃圾回收时,引用计数不会为0
析构函数
什么是析构函数?
“del”就是一个析构函数了,当使用del 删除对象时,会调用他本身的析构函数,另外当对象在某个作用域中调用完毕,在跳出其作用域的同时析构函数也会被调用一次,这样可以用来释放内存空间。
举个栗子:
class Test(object):
def __init__(self, name):
self.name = name
print('这是构造函数')
def say_hi(self):
print('hell, %s' % self.name)
def __del__(self):
print('这是析构函数')
obj = Test("beijing")
obj.say_hi()
上面的__del__()也是可选的,如果不提供,则Python 会在后台提供默认析构函数
如果要显式的调用析构函数,可以使用del关键字
举个栗子:
#删除上面调用对象
del obj
print(getrefcount(obj)) #同del,删除对象,释放内存空间
Python内存管理规则:del的时候,把list的元素释放掉,把管理元素的大对象回收到py对象缓冲池里
作用域
这里讲到作用域是为了更好的理解python的调用过程,敲重点,这一块必须要理解,对于编写代码非常有帮助
变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。比如冒泡排序,选择性排序,哈希排序均需要对这一块又很深刻的理解
举个栗子:
#选择性排序
def xuanze(lis):
ll = len(lis)
for i in range(ll):
min_index = i
for j in range(i+1,ll):
'''判断列表中的第min_index个元素是否大于第j个元素,如果大于,下面就互换位置,
一直拿min_index直到对比完列表第所有值,再拿第min_index元素对比'''
if lis[min_index]>lis[j]:
min_index = j #找到最小的数,放到索引min_index中
#这里才真正将列表的值互换位置,第一次循环完,找到最小的放到最左边,再循环第二次,第二小的放在第二个,以此类推
lis[i],lis[min_index] = lis[min_index],lis[i]
return lis
ff = xuanze(lis=[12,43,543,6,-312])
print(ff)
上面的例子中,ll=len(lis)为当前域
作用域有四种,分别是:
L(Local):最内层,包含局部变量,比如一个函数/方法内部。
E(Enclosing):包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。
G(Global):当前脚本的最外层,比如当前模块的全局变量。
B(Built-in): 包含了内建的变量/关键字等。,最后被搜索
规则顺序: L –> E –> G –>gt; B。
个人理解:当前域 -> 外部域(如果有) -> 全局域 -> 内置域。
举个栗子:
g_count = 0 # 全局作用域global
def outer():
o_count = 1 # 闭包函数外的函数中enclosing
def inner():
i_count = 2 # 局部作用域 local
'''Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、
for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问,如下代码'''
if True:
msg = 'yes'
print(msg)
'''当内部作用域想修改外部作用域的变量时,就要用到global和nonlocal关键字了'''
num = 1
def fun1():
global num # 需要使用 global 关键字声明
print(num)
num = 123
print(num)
fun1()
print(num)
'''如果要修改嵌套作用域(enclosing 作用域,外层非全局作用域)中的变量则需要 nonlocal 关键字了'''
def outer():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print(num)
inner()
print(num)
outer()
#有一种特殊情况
a = 10
def test(a):
a = a + 1#这里未定义,需在def中定义
print(a)
test(1)
闭包
如果在一个函数的内部定义了另一个函数,外部的函数叫它外函数,内部的函数叫它内函数。
闭包产生的必要条件
1 在一个外函数中定义了一个内函数。
2 内函数里运用了外函数的临时变量。
3 并且外函数的返回值是内函数的引用。
举个栗子:
def dog(name):
name = name
def conduce():
print("the dog's name is {0}".format(name))
return conduce
a = dog('虎子')#这里给dog方法传入实参且调用了dog()方法
#这里打印dog方法,我们发现返回的是conduce这个对象(内存地址)
print(a)#返回<function dog.<locals>.conduce at 0x104c94cb0>
#这里调用引用a方法
a()#返回the dog's name is 虎子
上面可以看到当执行外函数dog方法时,返回的是内函数conduce()对象,而执行a()时才时调用内函数方法,其实a=a = dog(‘虎子’),a()等同于dog(‘虎子’)(),因为最终我们是想去调用内函数方法
这就是闭包
那么我们拿到一段代码怎么判断它是闭包呢,其实python给了一个方法__closure__,下面看看怎么去使用它
拿上面的闭包举个栗子:
def dog(name):
name = name
def conduce():
print("the dog's name is {0}".format(name))
print(conduce.__closure__)
return conduce
dog('虎子')()#这里返回的是(<cell at 0x103d18d10: str object at 0x103d795d0>,),即为闭包
回顾总结
内存,我们有了引用指针的概念;垃圾回收,我们了解到了python的内存管理机制,可以查看阀值,设置垃圾回收阀值,也可手动进行回收;作用域,我们理解后可以更得心应手的给参数赋值;闭包,理解了闭包的产生条件后,就可以开始装饰器的学习了
装饰器
装饰器可以比喻成:装饰物件,比如上面闭包例子中的dog,给他穿衣服,衣服就是装饰器,装饰器是不破坏原有的对象,在外面给他加装饰,可以这么理解,装饰器的形成必须满足它是闭包的条件
举个栗子:
def a_new_decorator(a_func):
def wrapTheFunction():
print("--装饰衣服,我是装饰方法,调用a_func方法前")
a_func()
print("--装饰衣服,我是装饰方法,调用a_func方法后")
return wrapTheFunction
def decoration():
print("dog对象--我是需要穿衣服的方法")
decoration() #我是需执行的方法
#给他装饰一件衣服
ff = a_new_decorator(decoration)
#装饰后执行
ff()
上述就是装饰器的执行顺序及原理,此时我们用@语法糖就不需要这么麻烦赋值
举个栗子:
def a_new_decorator(a_func):
def wrapTheFunction():
print("--装饰衣服,我是装饰方法,调用a_func方法前")
a_func()
print("--装饰衣服,我是装饰方法,调用a_func方法后")
return wrapTheFunction
@a_new_decorator
def decoration_new():
print("=====dog对象--我是需要穿衣服的方法===")
'''--装饰衣服,我是装饰方法,调用a_func方法前
=====dog对象--我是需要穿衣服的方法===
--装饰衣服,我是装饰方法,调用a_func方法后'''
decoration_new()
下面是带参数的类装饰器
def now(days= 0, minutes = 0, seconds = 0, format = "%Y-%m-%d %H:%M:%S"):
"""
根据传参以当前时间为基准计算前后时间
例如 今天是2019-11-2 00:00:00
delay_time = now(days=1, format="%Y-%m-%d") 此时得到2019-11-3
:return:
"""
time_result = (datetime.datetime.now()+datetime.timedelta(days=days,minutes=minutes,seconds=seconds)).strftime(format)
return time_result
#高阶:带参数的类装饰器
class logger(object):
def __init__(self, func):
self.func = func
def __call__(self, *args, **kwargs):
print("[INFO]{now}: the function {func}() is running..."
.format(now=now(),func=self.func.__name__))
return self.func(*args, **kwargs)
@logger
def request():
print("这里请求接口")
request()#[INFO]2019-12-26 15:35:20: the function request() is running...
#这里请求接口
一个函数还能定义多个装饰器
举个栗子:
def a(func):
def pr():
print("装饰器a====执行前")
func()
print("装饰器a=====执行后")
return pr
def b(func):
def pr():
print("装饰器b====执行前")
func()
print("装饰器b=====执行后")
return pr
def c(func):
def pr():
print("装饰器c====执行前")
func()
print("装饰器c=====执行后")
return pr
@a
@b
@c
def dd():
print("这里是要调用的对象")
dd()
#return
装饰器a====执行前
装饰器b====执行前
装饰器c====执行前
这里是要调用的对象
装饰器c=====执行后
装饰器b=====执行后
装饰器a=====执行后
上面可以看到当有多个装饰器时,调用方法可以从返回中更直观的理解,执行顺序是从里到外,最先调用最里层的装饰器,最后调用最外层的装饰器,它等效于
ff = a(b(c(dd())))
关于装饰器详细用法的可参照装饰器用法.
以上就是我学习装饰器的心路历程,目前可以写自己想要的装饰器,如上面描述有问题,望大家指正,谢谢


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









