





阅读大约需 12 分钟
上回说到
小禾用适配器模式统一了多个 LLM 的接口,用工厂模式管理它们的创建。
老板满意了,客户满意了,小禾终于可以写点业务代码了。
然后,新的噩梦开始了。

那一天,JSON.parse 疯狂报错
小禾在做一个功能:让 AI 生成故事结构,返回 JSON 格式。
Prompt 写得很清楚:
prompt = """
请生成一个故事概念,以 JSON 格式返回:
{
"title": "故事标题",
"theme": "主题",
"characters": ["角色1", "角色2"]
}
只返回 JSON,不要有其他内容。
"""
response = adapter.generate(messages)
data = json.loads(response) # JSONDecodeError!
小禾盯着报错信息,陷入了沉思。
他打印了 AI 的返回内容:
好的,我来帮你生成一个故事概念:
{
"title": "月光下的秘密",
"theme": "友情与成长"
"characters": ["小明", "小红",]
}
希望这个故事概念对你有帮助!如果需要修改,请告诉我。
小禾数了数,这段"JSON"有多少个问题:
- 前面有废话:“好的,我来帮你生成……”
- 后面有废话:“希望这个故事概念……”
- 漏了逗号:
theme后面没有逗号 - 多了逗号:
characters数组最后多了个逗号
四个错误。一段 JSON。
小禾深吸一口气,心想:我都说了"只返回 JSON",你这 AI 是不是不识字?

AI 的"创意"远不止于此
接下来几天,小禾见识了 AI 返回的各种"创意 JSON":
经典款:中文引号
{"title":"月光下的秘密"}
那个冒号是中文的":"。肉眼几乎看不出来。
文艺款:带注释
{
"title": "月光下的秘密", // 这是标题
"theme": "友情" /* 主题 */
}
JSON 标准不支持注释。AI 不知道。
怀旧款:单引号
{'title': 'Hello World'}
这是 Python 字典的写法,不是 JSON。
程序员款:Windows 路径
{"path": "C:\new\test"}
\n 被解析成换行符,\t 被解析成 Tab。
意识流款:括号不匹配
{"scenes": [{"id": 1}, {"id": 2}
少了 ] 和 }。AI 可能在思考人生。
热情款:Markdown 代码块
当然!这是您要的 JSON:
\`\`\`json
{"title": "Hello"}
\`\`\`
还需要什么帮助吗?
崩溃之后,冷静分析
小禾统计了一周的数据:
| 错误类型 | 出现频率 |
|---|---|
| 前后有多余文本 | 极高 |
| 缺少逗号 | 高 |
| 多余逗号 | 高 |
| 中文标点 | 中 |
| 单引号 | 中 |
| 注释 | 低 |
| 非法转义 | 低 |
| 括号不匹配 | 低 |
解析失败率:23%。
也就是说,每 4 次调用就有 1 次失败。
小禾面前有两条路:
- 让用户重试:用户体验极差
- 写个修复器:自动修复 AI 的"创意"
作为一个有追求的程序员,小禾选择了后者。
容错解析器:设计思路
小禾画了个流程图:
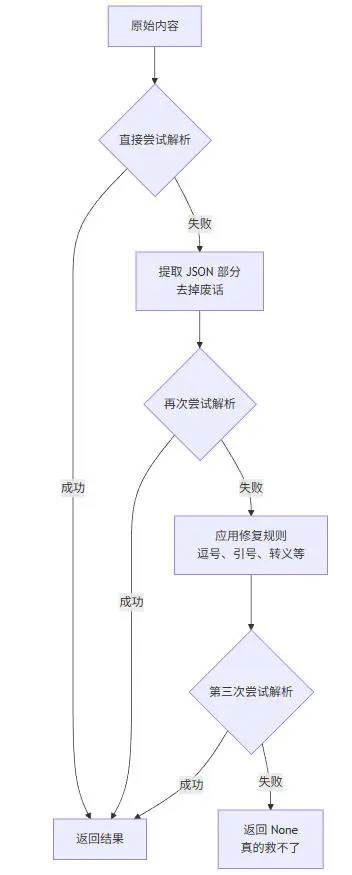
核心思想:先提取,再修复,多尝试。
第一步:提取 JSON 部分
AI 返回的内容通常是:
一堆废话……
{"实际的": "JSON"}
又一堆废话……
小禾的策略是:找到第一个 { 或 [,然后找到匹配的 } 或 ]。
def _extract_json(self, content: str) -> str | None:
"""从文本中提取 JSON 部分"""
# 先试试 Markdown 代码块
code_block = re.search(r'```json?\s*([\s\S]*?)\s*```', content)
if code_block:
return code_block.group(1)
# 找第一个 { 或 [
start_obj = content.find('{')
start_arr = content.find('[')
if start_obj == -1 and start_arr == -1:
return None # 压根没有 JSON
# 确定起始位置和对应的结束字符
if start_arr == -1 or (start_obj != -1 and start_obj < start_arr):
start, end_char = start_obj, '}'
else:
start, end_char = start_arr, ']'
# 找匹配的结束位置(要处理嵌套)
depth = 0
for i, char in enumerate(content[start:], start):
if char in '{[':
depth += 1
elif char in '}]':
depth -= 1
if depth == 0:
return content[start:i+1]
# 没找到匹配的结束括号,返回从 start 到结尾
return content[start:]
这样,"好的,{"title": "test"} 希望有帮助" 就变成了 {"title": "test"}。
第二步:修复常见错误
修复 1:中文标点 → 英文标点
这个最简单,直接替换:
def _fix_chinese_punctuation(self, s: str) -> str:
"""中文标点 → 英文标点"""
replacements = {
',': ',', # 中文逗号
':': ':', # 中文冒号
'"': '"', # 中文左引号
'"': '"', # 中文右引号
''': "'", # 中文单引号
''': "'",
'【': '[',
'】': ']',
}
for cn, en in replacements.items():
s = s.replace(cn, en)
return s
修复 2:多余的逗号
[1, 2, 3,] → [1, 2, 3]
{"a": 1,} → {"a": 1}
用正则删掉 , 后面紧跟 ] 或 } 的情况:
def _fix_trailing_comma(self, s: str) -> str:
"""移除多余的逗号"""
s = re.sub(r',(\s*[}\]])', r'\1', s)
return s
修复 3:缺少的逗号
这个稍微复杂。常见情况是:
"key1": "value1"
"key2": "value2"
两行之间漏了逗号。
def _fix_missing_comma(self, s: str) -> str:
"""在该有逗号的地方补上逗号"""
# "value"\n"key" 之间加逗号
s = re.sub(r'(")\s*\n(\s*")', r'\1,\n\2', s)
# }\n{ 之间加逗号
s = re.sub(r'(})\s*\n(\s*{)', r'\1,\n\2', s)
# ]\n[ 之间加逗号
s = re.sub(r'(])\s*\n(\s*\[)', r'\1,\n\2', s)
# 数字或布尔后面跟 " 也要加逗号
s = re.sub(r'(\d|true|false|null)\s*\n(\s*")', r'\1,\n\2', s)
return s
修复 4:单引号 → 双引号
def _fix_single_quotes(self, s: str) -> str:
"""单引号 → 双引号"""
# 这个比较危险,只处理明显是键值对的情况
# 'key': 'value' → "key": "value"
s = re.sub(r"'([^']*)'(\s*:)", r'"\1"\2', s) # 键
s = re.sub(r":\s*'([^']*)'", r': "\1"', s) # 值
return s
修复 5:非法转义
Windows 路径 C:\new 会被解析成 C: + 换行符 + ew。
def _fix_escape(self, s: str) -> str:
"""修复非法转义"""
# 把 \ 后面不是合法转义字符的情况,改成 \\
legal_escapes = set('"\\/bfnrtu')
result = []
i = 0
while i < len(s):
if s[i] == '\\' and i + 1 < len(s):
next_char = s[i + 1]
if next_char not in legal_escapes:
result.append('\\\\') # 转义这个反斜杠
else:
result.append('\\')
i += 1
else:
result.append(s[i])
i += 1
return ''.join(result)
修复 6:移除注释
def _remove_comments(self, s: str) -> str:
"""移除 // 和 /* */ 注释"""
# 单行注释(注意不要误删 URL 里的 //)
s = re.sub(r'(?<!:)//.*$', '', s, flags=re.MULTILINE)
# 多行注释
s = re.sub(r'/\*[\s\S]*?\*/', '', s)
return s
第三步:组装成完整的解析器
class JSONFixer:
"""LLM 输出的 JSON 容错解析器"""
def parse(self, content: str) -> dict | list | None:
"""尝试解析 JSON,失败则自动修复后重试"""
# 第一次尝试:直接解析
try:
return json.loads(content)
except json.JSONDecodeError:
pass
# 提取 JSON 部分
json_str = self._extract_json(content)
if not json_str:
return None
# 第二次尝试:解析提取的部分
try:
return json.loads(json_str)
except json.JSONDecodeError:
pass
# 应用所有修复规则
fixed = self._apply_all_fixes(json_str)
# 第三次尝试:解析修复后的内容
try:
return json.loads(fixed)
except json.JSONDecodeError:
return None
def _apply_all_fixes(self, s: str) -> str:
"""按顺序应用所有修复规则"""
s = self._remove_comments(s)
s = self._fix_chinese_punctuation(s)
s = self._fix_single_quotes(s)
s = self._fix_missing_comma(s)
s = self._fix_trailing_comma(s)
s = self._fix_escape(s)
s = self._fix_unbalanced_brackets(s)
return s
第四步:处理括号不匹配
有时候 AI 会漏掉结尾的括号:
{"scenes": [{"id": 1}, {"id": 2}
小禾用栈来检测和修复:
def _fix_unbalanced_brackets(self, s: str) -> str:
"""补全缺失的闭合括号"""
stack = []
pairs = {'{': '}', '[': ']'}
for char in s:
if char in '{[':
stack.append(char)
elif char in '}]':
if stack and pairs.get(stack[-1]) == char:
stack.pop()
# 补充缺失的闭合括号
while stack:
opening = stack.pop()
s += pairs[opening]
return s
生产环境版本
实际使用中,小禾又加了日志和重试机制:
class RobustJSONParser:
"""生产环境用的 JSON 解析器"""
def __init__(self):
self.fixer = JSONFixer()
self._stats = {"total": 0, "direct": 0, "fixed": 0, "failed": 0}
def parse(self, content: str, default=None):
self._stats["total"] += 1
# 直接成功
try:
result = json.loads(content)
self._stats["direct"] += 1
return result
except json.JSONDecodeError:
pass
# 修复后成功
result = self.fixer.parse(content)
if result is not None:
self._stats["fixed"] += 1
logger.info(f"JSON 自动修复成功")
return result
# 彻底失败
self._stats["failed"] += 1
logger.warning(f"JSON 解析失败,返回默认值")
return default
def get_stats(self):
"""获取统计信息"""
total = self._stats["total"]
if total == 0:
return "暂无数据"
return {
"总调用": total,
"直接成功": f"{self._stats['direct']} ({self._stats['direct']/total:.1%})",
"修复成功": f"{self._stats['fixed']} ({self._stats['fixed']/total:.1%})",
"失败": f"{self._stats['failed']} ({self._stats['failed']/total:.1%})",
}
使用效果
上线一周后,小禾看了下统计:
parser.get_stats()
# {
# "总调用": 10000,
# "直接成功": "7823 (78.2%)",
# "修复成功": "2089 (20.9%)",
# "失败": "88 (0.9%)"
# }
失败率从 23% 降到了 0.9%。

小禾满意地点了点头。
一些经验教训
1. Prompt 还是要写好
虽然有了修复器,但减少源头错误更重要:
# ❌ 不够明确
prompt = "请返回 JSON 格式"
# ✅ 更明确
prompt = """
返回一个 JSON 对象。
要求:
- 只返回 JSON,不要有任何解释
- 不要用 Markdown 代码块包裹
- 使用英文标点符号
"""
2. 能用 JSON Mode 就用
OpenAI 等 API 支持 response_format={"type": "json_object"},可以强制返回 JSON。
但即使开了 JSON Mode,也建议保留修复器——因为:
- 不是所有模型都支持
- 偶尔还是会出问题
3. 记录失败案例
每次修复失败,都记录下原始内容:
if result is None:
logger.error(f"JSON 解析彻底失败,原始内容: {content[:500]}")
这些案例是优化修复规则的宝贵素材。
小禾的感悟
原来以为:AI 返回 JSON,json.loads 一下就行
实际情况:AI 返回的是"薛定谔的 JSON"——你不解析,就不知道它是不是合法的
小禾端起咖啡,看着控制台的成功日志,心情不错。
适配器模式解决了"接口不统一"。
工厂模式解决了"创建对象"。
容错解析器解决了"AI 不靠谱"。
三板斧齐了,小禾觉得自己可以应对大部分情况了。
直到产品经理走过来说:“小禾,用户说生成一张图要等 2 分钟,Nginx 报 504 了……”
小禾的咖啡又不香了。
下一篇,我们聊聊超时处理和异步任务。小禾的头发又要少几根了。
敬请期待。
#Python #JSON #LLM #容错处理 #正则表达式



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











