




 博客聚焦Python字符串相关知识,包含判断整数是否为回文数,还详细介绍了字符串各类方法,如大小写转换、对齐、查找、替换、判断、截取、拆分拼接及格式化等,为Python学习提供了实用的字符串操作指南。
博客聚焦Python字符串相关知识,包含判断整数是否为回文数,还详细介绍了字符串各类方法,如大小写转换、对齐、查找、替换、判断、截取、拆分拼接及格式化等,为Python学习提供了实用的字符串操作指南。
十五、字符串
一、判断一个整数是不是回文数。
(回文数是指正序(从左往右)和倒序(从右往左)读都是一样的整数。)
x = input("请输入需要判断的数值:")
if x == x[::-1]:
print(x,"是回文数")
else:
print(x,"不是回文数")
二、字符串各类方法
(1)大小写字母换来换去
1)capitalize()
返回一个首字母大写版本的新字符串(新字符串的首字母变为大写,其他字母变为小写)
2)casefold()
返回一个小写版本的新字符串(新字符串的所有字母变为小写)
3)title()
返回标题化(所有的单词都是以大写开始,其余字母均小写)的字符串。
4)swapcase()
返回一个大小写字母翻转的新字符串。
5)upper()
返回一个所有英文字母都转换成大写后的新字符串。
6)lower()
返回一个所有英文字母都转换成小写后的新字符串。
举例:
x = "I Love You!"
#首字母变成大写,其他字母变成小写
x.capitalize()
'I love you!'
#capitalize返回的并不是源字符串,因为字符串是不可变的对象,它只是按照这个规则来生成一个新的字符串
x
'I Love You!'
#所有字母都是小写
x.casefold()
'i love you!'
#将字符串中的每个单词的首字母都变成大写,该单词的所有其他字母都变成小写
x.title()
'I Love You!'
#将字符中的所有字母大小写翻转
x.swapcase()
'i lOVE yOU!'
#将所有的字母都变成大写
x.upper()
'I LOVE YOU!'
#将所有的字母都变成小写
x.lower()
'i love you!'
注意:变成小写中,lower()只能处理英文字母,casefold()除了可以处理英语之外,还可以处理更多其他语言的字符。
(2)左中右对齐
1)center(width,fillchar=‘’)
返回一个字符居中的新字符串(width<=字符串长度,新字符串=原字符串;width>字符串宽度,所有字符居中,左右使用fillchar参数指定的字符填充)
2)ljust(width,fillchar=‘’)
返回一个字符左对齐的新字符串(width<=字符串长度,新字符串=原字符串;width>字符串宽度,所有字符左对齐,右侧使用fillchar参数指定的字符填充)。
3)rjust(width,fillchar=‘’)
返回一个字符右对齐的新字符串(width<=字符串长度,新字符串=原字符串;width>字符串宽度,所有字符右对齐,左侧使用fillchar参数指定的字符填充)。
4)zfill(width)
返回一个左侧用0填充的新字符串(width<=字符串长度,新字符串=原字符串;width>字符串宽度,所有字符右对齐,左侧使用0进行填充)。
举例:
x = "有内鬼,停止交易!"
#居中对齐
x.center(15)
' 有内鬼,停止交易! '
x.center(15,"淦")
'淦淦淦有内鬼,停止交易!淦淦淦'
#左对齐
x.ljust(15)
'有内鬼,停止交易! '
x.ljust(15,"淦")
'有内鬼,停止交易!淦淦淦淦淦淦'
#右对齐
x.rjust(15)
' 有内鬼,停止交易!'
x.rjust(15,"淦")
'淦淦淦淦淦淦有内鬼,停止交易!'
#用0填充左侧
x.zfill(15)
'000000有内鬼,停止交易!'
(3)查找
1)count(sub[,start[,end]]
返回sub在字符串中不重叠的出现次数,可选参数start和end用于指定起始和结束位置
2)find(sub[,start[,end]])
在字符串中查找sub子字符串,返回匹配的最低索引值;可选参数start和end用于指定起始和结束位置;如果未能匹配子字符串,返回-1。
3)rfind(sub[,start[,end]])
在字符串中自右向左查找sub子字符串,返回匹配的最高索引值;可选参数start和end用于指定起始和结束位置;如果未能匹配子字符串,返回-1。
4)index(sub[,start[,end]])
在字符串中国呢查找sub子字符串,返回匹配的最低索引值;可选参数start和end用于指定起始和结束位置;如果未能匹配子字符串,抛出ValueError异常。
5)rindex(sub[,start[,end]])
在字符串中自右向左查找sub子字符串,返回匹配的最高索引值;可选参数start和end用于指定起始和结束位置;如果未能匹配子字符串,抛出ValueError异常。
举例:
#查找sub参数指定的子字符串,在字符串中出现的次数
x = "上海自来水来自海上"
x.count("海")
2
x.count("海",0,5)
1
#定位sub参数指定的子字符串在字符串中的索引下标值
(从左往右找)
x.find("海")
1
(从右往左找)
x.rfind("海")
7
(如果找不到,返回-1)
x.find("你")
-1
#index与find查找作用一样,区别在于找不到时候index返回的抛出异常
x.index("你")
Traceback (most recent call last):
File "<pyshell#25>", line 1, in <module>
x.index("你")
ValueError: substring not found
(4)替换
1)expandtabs([tabsize=8])
返回一个使用空格替换制表符的新字符串,如果没有指定tabsize参数,那么默认1个制表符=8个空格。
2)replace(old,new,count=-1)
返回一个将所有old参数指定的子字符串替换为new的新字符串;count参数指定替换的次数,默认是-1,表示替换全部。
3)translate(table)
返回一个根据table参数转换后的新字符串;table参数应该提供一个转换规则(可以由str.maketrans(‘a’,‘b’)进行定制,例如"FishC".translate(str.maketrans(“FC”,“15”)) -> ‘1ish5’)。
举例:
#使用空格来替换制表符,并且返回一个新的字符串
code ='''
print("I love FishC")
print("I love my wife")'''
new_code = code.expandtabs(4)
print(new_code)
print("I love FishC")
print("I love my wife")
#返回一个将所有old的参数指定的子字符串替换为new参数指定的新字符串,count参数指定的是替换的次数,默认是-1,相当于替换全部。
"在吗!我在你家楼下,快点下来!!".replace("在吗","想你")
'想你!我在你家楼下,快点下来!!'
#返回一个根据table参数转换后的新字符串,table是表格的意思,用于指定一个转换规则的表格
table = str.maketrans("ABCDEFG","1234567")
"I love FishC".translate(table)
'I love 6ish3'
"I love FishC".translate(str.maketrans("ABCDEFG","1234567"))
'I love 6ish3'
#str.maketrans方法,还支持第三个参数,将指定的字符串给忽略
"I love FishC".translate(str.maketrans("ABCDEFG","1234567","love"))
'I 6ish3'
(5)判断
1)startswith(prefix[,start[,end]])
如果存在prefix参数指定的前缀子字符串,则返回Ture,否则返回False;可选参数start和end用于指定起始和结束位置;prefix参数允许以元祖的形式提供多个子字符串。
2)endswith(suffix[,start[,end]])
如果字符串是以suffix指定的字符串为结尾,那么返回Ture,否则返回False;可选参数start和end用于指定起始和结束位置;suffix参数允许以元祖的形式提供多个子字符串。
3)isupper()
如果字符串中至少包含一个区分大小写的英文字母,并且这些字母都是大写,则返回Ture,否则返回False。
4)islower()
如果字符串中至少包含一个区分大小写的英文字母,并且这些字母都是小写,则返回Ture,否则返回False。
5)istitle()
如果字符串是标题化字符串(所有的单词都是以大写开始,其余字母均小写)则返回Ture,否则返回False。
6)isalpha()
如果字符串中至少有一个字符串并且所有字符串都是字母则返回Ture,否则返回False。
7)isascii()
如果字符串中所有字符串都是ASCII则返回Ture,否则返回False;ASCII字符编码范围是U+0000~U+007F,空字符串也是ASCII。
8)isspace()
如果字符串中至少有一个字符并且所有字符都是空格,则返回Ture,否则返回False。
9)isprintable()
如果字符串是可以打印的内容则返回Ture,否则返回False。
10)isdecimal()
如果字符串中至少有一个字符并且所有字符串都是十进制数字则返回Ture,否则返回False。
11)isdigit()
如果字符串中至少有一个字符并且所有字符串都是数字则返回Ture,否则返回False。
12)isnumeric()
如果字符串中至少有一个字符并且所有字符都是数字则返回Ture,否则返回False。
13)isalnum()
如果字符串中至少有一个字符并且所有字符都是字母或数字则返回Ture,否则返回False。
14)isidentifier()
如果字符串是一个合法的python标识符则返回Ture,否则返回False;调用keyword.iskeywords(s)可以检测字符串是否一个保留标识符(比如"if"或"for")。
举例:
#判断参数指定的子字符串,是否出现在字符串的起始位置
x = "我爱Pyhon"
x.startswith("我")
True
x.startswith("我",1)
False
#判断参数指定的子字符串,是否出现在字符串的结束位置
x.endswith("Pyhon")
True
x.endswith("Py",0,4)
True
注意:它们的参数支持以元祖的形式传入多个待匹配的字符串
x = "她爱Pyhon"
if x.startswith(("你","我","她")):
print("总有人喜欢Pyhon")
总有人喜欢Pyhon
#判断一个字符串中所有单词都是以大写开头,其他字母都是小写
x = "I love Python"
x.istitle()
False
#判断一个字符串中所有的字母都是大写
x.isupper()
False
注意:在一个语句中连续调用多个方法,Python是从左往右依次进行调用
x.upper().isupper()
True
#判断一个字符串中所有的字母都是小写
x.islower()
False
#判断字符串中是否只是由字母构成(注意空格不是字母)
x.isalpha()
False
"IlovePyhton".isalpha()
True
#判断是否为一个空白字符串(注意不止是空格才是空白字符串,Tab也是空白字符串,转义字符也是空白字符串)
" \n".isspace()
True
#判断字符串中是否所有字符都是可打印的(注意\n这个转义字符是不可打印的字符)
x.isprintable()
True
"I love FishC\n".isprintable()
False
#判断数字(isdecimal()、isdigit()、isnumeric()区别在不同类型的数字上)
(十进制数字)
x = "12345"
x.isdecimal()
True
x.isdigit()
True
x.isnumeric()
True
(平方)
x = "2²"
x.isdecimal()
False
x.isdigit()
True
x.isnumeric()
True
(罗马数字)
x = "ⅠⅡⅢⅣⅤ"
x.isdecimal()
False
x.isdigit()
False
x.isnumeric()
True
(中文字符)
x = "一二三四五"
x.isdecimal()
False
x.isdigit()
False
x.isnumeric()
True
#集大成者isalnum()方法是只要isalpha()、isdecimal()、isdigit()、isnumeric()中任意一个方法返回Ture,那么结果都是Ture。
#判断字符串是否一个合法的Python标识符(注意有空格不行,且标识符不能以数字开头)
"I am a good gay".isidentifier()
False
"I_am_a_good_gay".isidentifier()
True
"FishC520".isidentifier()
True
"520FishC".isidentifier()
False
#判断一个字符串是否为Python的保留标识符,比如if、for、while这些关键字,可以使用keyword模块的iskeyword函数
import keyword
keyword.iskeyword("if")
True
keyword.iskeyword("py")
False
(6)截取
1)strip(chars=None)
返回一个去除左右两侧空白字符的新字符串;通过chars参数可以指定将要去除的字符串。
2)lstrip(chars=None)
返回一个去除左侧空白字符的新字符串;通过chars参数可以指定将要去除的字符串。
3)rstrip(chars=None)
返回一个去除右侧空白字符的新字符串;通过chars参数可以指定将要去除的字符串。
4)removeprefix(prefix)
如果存在prefix参数指定的前缀子字符串,则返回一个将该前缀去除后的新字符串;如果不存在,则返回一个原字符串的拷贝。
5)removesuffix(suffix)
如果存在suffix参数指定的前缀子字符串,则返回一个将该前缀去除后的新字符串;如果不存在,则返回一个原字符串的拷贝。
举例:
#去除左侧的字符(从左侧开始剔除所有含指定字符串的每个字符,直到左侧开头不是以指定字符串开始为止)
" 左侧不要留白".lstrip()
'左侧不要留白'
"www.ilovefishc.com".lstrip("wcom.")
'ilovefishc.com'
#去除右侧的字符
"右侧不要留白 ".rstrip()
'右侧不要留白'
"www.ilovefishc.com".rstrip("wcom.")
'www.ilovefish'
#去除左右的字符
" 左右不要留白 ".strip()
'左右不要留白'
"www.ilovefishc.com".strip("wcom.")
'ilovefish'
#剔除一个具体的子字符串,允许指定将要删除的前缀或者后缀
"www.ilovefishc.com".removeprefix("www.")
'ilovefishc.com'
"www.ilovefishc.com".removesuffix(".com")
'www.ilovefishc'
(7)拆分&拼接
1)partition(sep)
在字符串中搜索sep参数指定的分隔符,如果找到,返回一个3元祖(‘在sep前面的部分’,‘sep’,‘在sep后面的部分’);如果未找到,则返回(‘原字符串’,“,”)
2)rpartition(sep)
在字符串中自左向右搜索sep参数指定的分隔符,如果找到,返回一个3元祖(‘在sep前面的部分’,‘sep’,‘在sep后面的部分’);如果未找到,则返回(“,”,‘原字符串’)
3)split(sep=None,max split=-1)
将字符串进行分割,并将结果以列表的形式返回;sep参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit参数用于指定分割的次数(注意:分割2次的结果是3份),默认是不限制。
4)rsplit(sep=None,max split=-1)
将字符串自右向左进行分割,并将结果以列表的形式返回;sep参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit参数用于指定分割的次数(注意:分割2次的结果是3份),默认是不限制。
5)splitlines(keepends=False)
将字符串进行分割,并将结果以列表的形式返回;keepends参数指定是否包含换行符,Ture是包含,False是不包含。
6)join(iterable)
连接多个字符串并返回一个新字符串;以调用该方法的字符串作为分隔符,插入到iterable参数指定的每个字符串的中间;例如:‘~’.join([“F”,“i”,“sh”,“C”]) -> ‘FIsh~C’
举例:
#将字符串以参数指定的分割符为依据进行切割,并且将切割后的结果返回一个三元祖(三个元素的元祖)
#从左往右去找一个分割符
"www.ilovefishc.com".partition(".")
('www', '.', 'ilovefishc.com')
#从右往左去找一个分割符
"www.ilovefishc.com".partition(".")
('www', '.', 'ilovefishc.com')
#根据分割符将字符串切成一小块一小块,并将结果打包成列表返回
#默认切割空格
"苟日新 日日新 又日新".split()
['苟日新', '日日新', '又日新']
#指定分割符
"苟日新,日日新,又日新".split(",")
['苟日新', '日日新', '又日新']
#从右往左分割
"苟日新,日日新,又日新".rsplit(",")
['苟日新', '日日新', '又日新']
#第二个参数指定想要分割的次数,默认是-1,全部切割
"苟日新,日日新,又日新".split(",",1)
['苟日新', '日日新,又日新']
"苟日新,日日新,又日新".rsplit(",",1)
['苟日新,日日新', '又日新']
#包含换行符的字符串,要求按照换行符进行一个分割
"苟日新\n日日新\r又日新".splitlines()
['苟日新', '日日新', '又日新']
"苟日新\n日日新\r又日新".splitlines(True)
['苟日新\n', '日日新\r', '又日新']
#拼接字符串,前面字符做为分割符的形式,而构成字符串的每个子字符串是放在join方法的参数里的,用列表或元祖包裹都可以
".".join(["www","ilovefishc","com"])
'www.ilovefishc.com'
".".join(("www","ilovefishc","com"))
'www.ilovefishc.com'
#字符串的拼接,加号与join的区别,数量级多了以后join快
s = "FishC"
s +=s
s
'FishCFishC'
"".join(("FishC","FishC"))
'FishCFishC'
(8)格式化字符串
**1)format(*args,kwargs)
返回一个格式化的新字符串;使用位置参数(arges)和关键字参数(kwargs)进行替换。
2)encode(encoding=‘utf-8’,errors=‘strict’)
以encoding参数指定的编码格式对字符串进行编码。errors参数指定编码出现错误时的解决方案:默认’strict’表示如果出错,将抛出一个UnicodeEncodeError的异常。其他可用的参数值是’ignore’,‘replace’和’xmlcharrefreplace’。
3)format_map(mapping)
返回一个格式化的新字符串;使用映射参数(mapping)进行替换。
举例:
#传入变量
year = 2010
"鱼c工作室成立于 {} 年".format(year)
'鱼c工作室成立于 2010 年'
"1+2={},2的平方是{},3的立方是{}".format(1+2,2*2,3*3*3)
'1+2=3,2的平方是4,3的立方是27'
#方括号可以写元素的下标索引值
"{}看到{}就很激动!".format("小甲鱼","漂亮的小姐姐")
'小甲鱼看到漂亮的小姐姐就很激动!'
"{1}看到{0}就很激动!".format("小甲鱼","漂亮的小姐姐")
'漂亮的小姐姐看到小甲鱼就很激动!'
#同一个索引值可以被引用多次
"{0},{0},{1},{1}".format("是","非")
'是,是,非,非'
#通过关键字进行索引
"我叫{name},我爱{fav}。".format(name="小甲鱼",fav="Python")
'我叫小甲鱼,我爱Python。'
#对齐字符串[align]
| 值 | 含义 |
| '<' | 强制字符串在可用空间内左对齐(默认) |
| '>' | 强制字符串在可用空间内右对齐 |
| '=' | 强制将填充放置在符号(如果有)之后但在数字之前的位置(这适用于以"+000000120"的形式打印字符串) |
| '^' | 强制字符串在可用空间内居中 |
举例:
"{:^10}".format(250)
' 250 '
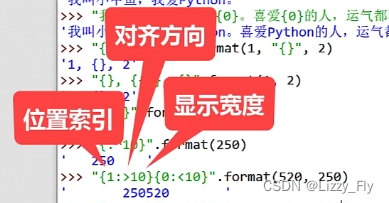
"{1:>10}{0:<10}".format(520,250)
' 250520 '
"{left:>10}{right:<10}".format(right=520,left=250)
' 250520 '
#在指定的宽度前添加0,表示为数字类型启用感知正负号的0填充效果
"{:010}".format(520)
'0000000520'
"{:010}".format(-520)
'-000000520'
#另一种写法
"{:0=10}".format(520)
'0000000520'
"{:0=10}".format(-520)
'-000000520'
#在对齐选项的前面,通过填充选项来指定填充的字符
"{1:%>10}{0:%<10}".format(520,250)
'%%%%%%%250520%%%%%%%'
符号选项,仅对数字类型有效
| 值 | 含义 |
| '+' | 正数在前面添加正号(+),负数在前面添加负号(-) |
| '-' | 只有负数在前面添加符号(-),默认行为 |
| 空格 | 正数在前面添加一个空格,负数在前面添加负号(-) |
"{:+} {:-}".format(520,-250)
'+520 -250'
#设置千分位的分割符
"{:,}".format(1234)
'1,234'
"{:_}".format(1234)
'1_234'
精度选项
1)对于[type]设置为’f’或’F’的浮点数来说,是限定小数点后显示多少个位数
2)对于[type]设置为’g’或’G’的浮点数来说,是限定小数点前后一共显示多少个位数
3)对于非数字类型来说,限定的是最大字段的大小
4)对于整数类型来说,则不允许使用[.precision]选项
"{:.2f}".format(3.1415)
'3.14'
"{:.2g}".format(3.1415)
'3.1'
"{:.6}".format("I love FishC")
'I love'
适用于整数:
| 值 | 含义 |
| 'b' | 将参数以二进制的形式输出 |
| 'c' | 将参数以Unicode字符的形式输出 |
| 'd' | 将参数以十进制的形式输出 |
| 'o' | 将参数以八进制的形式输出 |
| 'x' | 将参数以十六进制的形式输出 |
| 'X' | 将参数以十进制的形式输出 |
| 'n' | 跟'd'类似,不同之处在于它会使用当前语言环境设置的分隔符插入到恰当的位置 |
| None | 跟'd'一样 |
"{:b}".format(80)
'1010000'
"{:c}".format(80)
'P'
"{:d}".format(80)
'80'
"{:o}".format(80)
'120'
"{:x}".format(80)
'50'
"{:c}".format(80)
'P'
加#号的话,会在结果前面加一个类型的前缀
"{:#b}".format(80)
'0b1010000'
"{:#o}".format(80)
'0o120'
"{:#x}".format(80)
'0x50'
适用于复数和浮点数:
| 值 | 含义 |
| 'e' | 将参数以科学计数法的形式输出(以字母'e'来标示指数,默认精度为6) |
| 'E' | 将参数以科学计数法的形式输出(以字母'E'来标示指数,默认精度为6) |
| 'f' | 将参数以定点表示法的形式输出(“不是数”用'nan'标示,无穷用'inf'标示,默认精度为6) |
| 'F' | 将参数以定点表示法的形式输出(“不是数”用'NAN'标示,无穷用'INF'标示,默认精度为6) |
| 'g' | 通用格式,小数以'f'形式输出,大数以'e'的形式输出 |
| 'G' | 通用格式,小数以'F'形式输出,大数以'E'的形式输出 |
| 'n' | 跟'g'类似,不同之处在于它会使用当前语言环境设置的分隔符插入到恰当的位置 |
| '%' | 以百分比的形式输出(将数字乘以100并显示为定点表示法('f')的形式,后面附带一个百分号) |
| None | 类似于'g',不同之处在于当使用定点表示法时,小数点后将至少显示一位;默认精度与给定值所需的精度一致 |
"{:e}".format(3.1415)
'3.141500e+00'
"{:E}".format(3.1415)
'3.141500E+00'
"{:f}".format(3.1415)
'3.141500'
"{:g}".format(123456789)
'1.23457e+08'
"{:g}".format(1234.56789)
'1234.57'
"{:%}".format(0.98)
'98.000000%'
"{:.2%}".format(0.98)
'98.00%'
#Python支持通过关键字参数来设置选项的值
"{:.{prec}f}".format(3.1415,prec=2)
'3.14'
"{:{fill}{align}{width}.{prec}{ty}}".format(3.1415,fill='+',align='^',width=10,prec=3,ty='g')
'+++3.14+++'
f-字符串(f-string),Python3.6的产物
只要在普通的字符串前面加上一个f-/F-作为一个前缀就可以了
year = 2010
F"鱼c工作室成立于 {year} 年"
'鱼c工作室成立于 2010 年'
f"1+2={1+2},2的平方是{2*2},3的立方是{3*3*3}"
'1+2=3,2的平方是4,3的立方是27'
f"{-520:010}"
'-000000520'
"{:,}".format(123456789)
'123,456,789'
f"{123456789:,}"
'123,456,789'


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









