




前言:
接触强化学习最开始是参看的Sutton的本系列是参照Sutton的reinforcement learning an introduction这本书,刚开始读的时候感觉这本书晦涩难懂,非常不好理解。因此就找了几本中文的强化学习相关的书籍,阅读之后发现这些教材里很多东西都没讲清楚。折腾了一圈,最后还是决定仔细研读Sutton的这本教材。为了检验自己对于强化学习知识点的掌握情况,我就写了这个系列的博客。边看书,边记录。我一直认为,只有能把一个知识点讲清楚,才算是掌握了这个知识点。如有不对的地方,还希望有大神能够指正。
正文:
第二章通篇都在讲多臂赌博机问题。我们先来看什么是多臂赌博机问题?赌博机有K个摇臂,代表K个动作(action),每个时间步长(Step-size),我们会选择一个动作,每个动作都对应一个期望的奖励(reward),我们称此奖励为该动作的价值(value)。我们的目标是经过一段时间的选择,使累积的奖励最大。换言之,在每个时间步长里,我们选择一个动作,经过一段时间,是累积的奖励最大化。
在这个问题里,我们需要明确:这里提到的奖励(reward)是符合一个特定的概率分布。我们用$A_{t}$表示在时间t时要选择的动作,$R_{t}$表示在实践t选择该动作对应的奖励,$q_{*}(a)$表示动作a的价值。为了求得这个价值,我们提出如下公式:
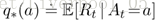
注意,这里$q_{*}(a)$的值是一个期望。那么什么叫期望?期望就是概率的加权值。如果这点没有看懂,我们稍后还会提到。
在这个赌博机问题中,如果我们清楚的知道每个动作的价值(value),我们每次只需要选择具有最大价值的动作,就可以解决这个赌博机问题(这应该很好理解,你都知道选哪个动作好了,只需要每次都选那个最好的就能得到最优解)。但是呢,我们之前提到过,我们并不知道每个动作对应的确切价
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









