 Zookeeper详解:原理、配置、操作与分布式协调
Zookeeper详解:原理、配置、操作与分布式协调





学习目标:
掌握zookeeper集群原理
学习内容:
什么是zookeeper
zookeeper是一种分布式协调服务,用于管理大型主机。给分布式应用提供一致性服务的软件,分布式应用程序可以基于zookeeper实现数据发布/订阅,负载均衡,分布式协调通知,集群管理,master选举,分布式锁等功能
zookeeper提供的一致性有:顺序一致性,原子性,可靠性,最终一致性
搭建zookeeper服务器
- 从官网下载安装包
#gpg --import KEYS #需要先下载gpg包校验的私钥,不然下载的包不完整无法解压
#wget https://dlcdn.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
#tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz
- zoo.cfg配置文件说明
#zookeeper时间配置中的基本单位(毫秒)
tickTime=2000 #即2s
#允许follower初始化连接到leader最大时长,它表示tickTime时间倍数,即: initLimit*tickTime
initLimit=10 #即初始化连接表示最大时长为20s
#允许follower与leader数据同步的最大时长,它表示tickTime时间倍数
syncLimit=5 #即数据同步最大时长为10s
#zookeeper数据存储及日志保存目录,(如果没有指明dataLogDir,则日志也保存在这个文件中)
dataDir=/tmp/zookeeper
dataLogDir=/tmp/zookeeper
#对客户端提供的端口
clientPort=2181
#单个客户端与zookeeper最大并发连接数
maxClientCnxns=60
#保存的数据快照数量,之外的将会被删除
autopurge.snapRetainCount=3
#自动触发清除任务时间间隔,小时为单位,默认是0,表示不自动清除
autopurge.purgeInterval=1
优化配置
preAlloSize=51200(约等于51M)
用于配置zk事务文件预分配的磁盘空间的大小默认是64m
snapCount=85000
用于配置相邻两次数据快照之间的事务操作次数,zk会在snapCount次事务操作之后,会进行一次数据快照(default:100000)
clientPortAddress:
针对多网卡的机器允许为每个IP地址制定不同的监听端口
minSessionTimeout, maxSessionTimeout:
用于服务端对客户端会话的超时时间进行限制。
如果客户端设置的超时时间不在设置时间范围以内,那么会被服务端强制设置为最大或者最小超时时间
- zookeeper服务器操作命令
重命名conf中的文件zoo_sample.cfg-->zoo.cfg
1、启动zk服务器
#./bin/zkServer.sh start ./conf/zoo.cfg
2、查看zk服务器状态
#./bin/zkServer.sh status ./conf/zoo.cfg
3、停止zk服务器
#./bin/zkServer.sh stop ./conf/zoo.cfg
-
zookeeper内部数据结构
1、**zk是如何保存数据的** zk中数据是保存在节点上的,节点就是znode,多个znode之间构成一棵树的目录结构 zk的数据模型很像数据结构中的树,也很像文件系统的目录 树是由节点所构成,zk的数据存储也同样是基于节点,这种节点叫做Znode 但是不同于树的节点,Znode的引用方式是路径引用,类似于文件路径,必须以 / 开头 这样的层次结构,让每一个Znode节点拥有唯一的路径,就像命名空间一样对不同信息做出清晰的隔离 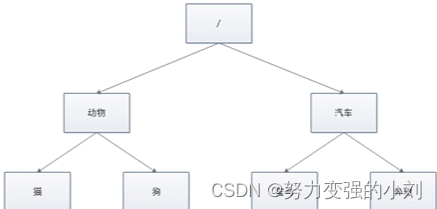 -
zk中的znode是什么样的结构
zk中的znode包含四个部分:
1、data:保存数据
2、acl:权限,定义了什么样的用户能够操作这个节点,且能够进行什么样的操作
create:创建权限,允许在该节点下创建子节点
write:更新权限,允许更新节点的数据
read:读取权限
delete:删除权限
admin:管理者权限,允许对该节点进行acl权限设置
3、stat:描述当前znode的元数据
4、child:当前节点的子节点 -
zk中节点znode的类型
持久化节点:创建出的节点,在会话结束后依然存在,保存数据
持久序号节点:创建出的节点,根据先后顺序,会在节点之后带上一个数值,越后数值越大,适用于分布式锁的应用场景–单调递增
临时节点:临时节点是在会话结束后,自动被删除,这个可以实现服务注册和发现的效果
临时序号节点:跟持久序号节点相同,适用于临时分布式锁
container节点:container容器节点,当容器中没有任何子节点,该容器节点将会被zk定期删除(60s)
TTL节点:可以指定节点的到期时间,到期后定期被zk定时删除。只能通过系统配置zookeeper.extendedTypesEnabled=true开启 -
zk的数据持久化机制
zk的数据是运行在内存中,zk提供两种持久化机制:
1、事务日志:zk把执行的命令以日志的形式保存在dataLogDir指定的路径中的文件中(如果没有指定dataLogDir,则按dataLog指定的路径)
2、数据快照:zk会在一定的时间间隔内做一次数据的快照,把该时刻的内存数据保存在快照文件中
zk通过这两种形式的持久化,先恢复快照文件中的数据到内存中,再用日志文件中的数据做增量恢复,这样的恢复速度更快 -
zk客户端(zkCli)的使用
1、多节点类型创建 创建持久节点 create /test1 abc #在节点后面加内容即数据 创建持久序号节点 create -s /test2 创建临时节点 create -e /test3 创建临时序号节点 create -e -s /test4 创建容器节点 create -c /test5 2、权限设置 ```powershell #注册当前会话的账号密码 #addauth digest xiaoming:123456 #创建节点并设置权限 #create /test3 abcd auth:xiaoming:123456:cdrwa ``` 在另一个会话中必须使用账号密码,才能拥有操作该节点的权限 -
zk实现分布式锁
1、zk中锁的种类 读锁:大家都可以读,要想上读锁的前提:之前的锁没有写锁 写锁:只有得到写锁的才能写,要想上写锁的前提是:之前没有任何锁 2、**zk如何上读锁** 创建一个临时序号节点,节点的数据是read,表示是读锁 获取当前zk中序号比自己小的所有节点 判断最小节点是否是读锁: 1.如果不是读锁的话,则上锁失败,为最小节点设置监听。阻塞等待,zk的watch机制会当最小节点发生变化时通知当前节点,于是再执行第二步流程 2.如果是读锁的话,则上锁成功 3、**zk如何上写锁** 创建一个临时序号节点,节点的数据是write,表示是写锁 获取zk中所有的子节点 判断自己是否是最小的节点: 1.如果是,则上写锁成功 2.如果不是,说明前面还有锁,则上锁失败,监听最小的节点,如果最小节点有变化,则回到第二步 -
zk的watch机制原理
1、watch机制介绍:可以把watch理解成是注册在特定Znode上的触发器,当这个Znode发生改变,也就是create、delete、set方法的时候,将会触发Znode上注册的对应事件,请求watch的客户端会接收到异步通知
客户端使用NIO通信模式监听服务端的调用

-
zookeeper集群
1、zookeeper集群三种角色 leader:处理集群的所有事务请求,集群中只有一个leader follower:只能处理读请求,参与leader选举 observer:只能处理读请求,提升集群读的性能,但不参与leader选举 2、集群搭建 搭建4个节点,其中一个为observer 1.创建4个节点的myid,并设值#echo 1 > /usr/local/zookeeper/apache-zookeeper-3.7.1-bin/zkdata/zk1/myid #echo 2 > /usr/local/zookeeper/apache-zookeeper-3.7.1-bin/zkdata/zk2/myid #echo 3 > /usr/local/zookeeper/apache-zookeeper-3.7.1-bin/zkdata/zk3/myid #echo 4 > /usr/local/zookeeper/apache-zookeeper-3.7.1-bin/zkdata/zk4/myid2.编写4个zoo.cfg配置文件



#启动4台zookeeper #./bin/zkServer.sh start ../conf/zoo1.cfg #./bin/zkServer.sh start ../conf/zoo2.cfg #./bin/zkServer.sh start ../conf/zoo3.cfg #./bin/zkServer.sh start ../conf/zoo4.cfg #查看zookeeper每台的状态和角色信息 #./bin/zkServer.sh status ../conf/zoo1.cfg #后台替换每台zookeeper的配置文件 #连接zookeeper集群 #./bin/zkCli.sh -server 10.234.252.122:2181,10.234.252.122:2182,10.234.252.122:2183,10.234.252.122:2184
ZAB协议
-
什么是ZAB协议
zookeeper作为非常重要的分布式协调组件,需要进行集群部署,集群中会以一主多从的形式进行部署。zookeeper为了保证数据的一致性,使用ZAB(zookeeper atomic broadcast)协议,这个协议解决了zookeeper的崩溃恢复和主从数据同步的问题

-
ZAB协议定义的四种节点状态
1、looking:选举状态
2、following:follower节点(从节点)所处的状态
3、leading:leader节点(主节点)所处的状态
4、observing:观察者节点所处的状态 -
集群上线时leader的选举过程

-
崩溃恢复时的leader选举
leader建立完后,leader周期性的不断向follower发送心跳(ping命令,没有内容的socket)。当leader崩溃后,follower发现socket通道已关闭,于是follower开始进入looking状态,重新回到上一节的leader选举过程,此时集群不能对外提供服务 -
主从服务器之间的数据同步

-
zk中的NIO和BIO应用
NIO: 用于被客户端连接的2181端口,使用的是NIO模式与客户端建立连接 客户端开启watch时,也使用NIO,等待zookeeper服务的回调 BIO: 集群选举时,多个节点之间的投票通信端口,使用BIO通信

















 5434
5434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









