




Abstract
- 解决的问题?
现有的视频标准训练方式每个迭代会从原始视频中采样一个clip(剪辑),然后通过这一个clip来学习video-level级别的标签。本文认为一个clip不具有足够的时间覆盖性来展示需要识别的标签。而且这种学习方式阻碍模型学习长期时间依赖性的能力。
- 怎么解决的?
引入了一种协同记忆机制(collaborative memory mechanism),在每个训练步,可以从同一个视频采样的多个clips中学习特征。
- 结果如何?
该方法可以适用于不同的架构和任务。在action recognition/detection中都取得了SOTA的结果。
1. Introduction
- 现有的研究方法?存在什么问题?
- 在clip-based backbone之上建立一个分离的网络。这种方式:1)要么无法end-to-end训练(即整个模型要在预先提取的clip-level的features上进行训练);2)要么需要临时的backbones,难以应用在现代的网络架构中。
- 本文是怎么解决上述问题?提出了哪些方法
- 提出了一个协同记忆机制,该记忆机制可以从一个video多个clips中聚集videl-level的上下文信息。在每一个训练步中,将全局的上下文信息注入每一个clip中,从而优化单个clip的表征(representation)。
- 本文的主要贡献
- 一种可以让clip-based模型学习videl-level dependencies的end-to-end新型训练框架
- 一种可以让多个clips进行信息交换的信息协同记忆机制。并探索了几种实现方式,同时指出了优化的困难点
- 该方法可以适用于不同的backbones,在action recognition和detection上都取得了SOTA的结果
2. Related Work
3. Methods
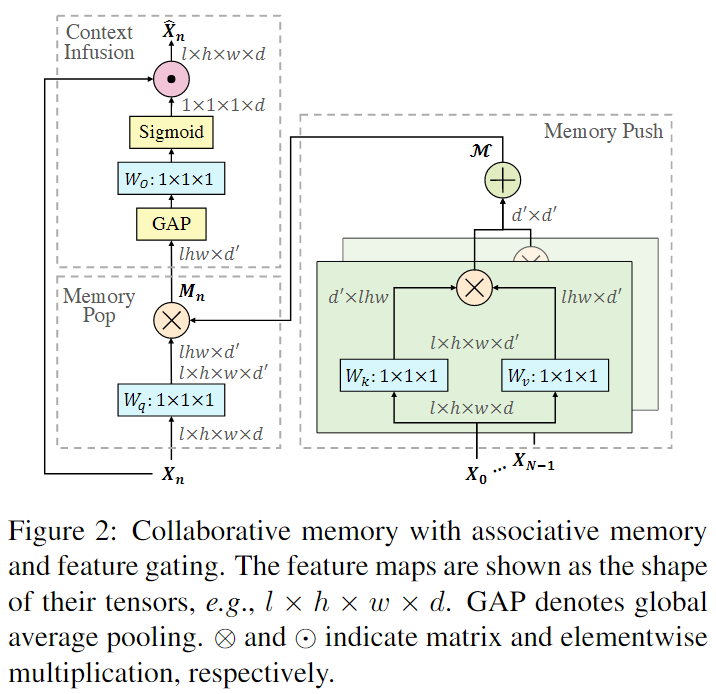
给定一个 T T T帧视频 v = { I 0 , … , I T − 1 } v = \{I_0, \dots,I_{T-1}\} v={ I0,…,IT−1},每个训练步从原视频中采样N个clips { C 0 , … , C N − 1 } \{C_0,\dots,C_{N-1}\} { C0,…,CN−1}, C n = { I t n , … , I t n + L − 1 } C_n=\{I_{t_n},\dots,I_{t_n+L-1}\} Cn={ Itn,…,Itn+L−1}包含L个连续的帧。N是一个由T和L之间的比例决定的超参数,目的是获得足够的时间覆盖。
Collaborative Memory
Memory interactions
Average Pooling: 通过一个平均池化将所有clips的表征聚集起来。其中每个clip-level的表征是一个 k × d k \times d k×d的矩阵, k = h e i g h t × w i d t h × l e n g t h k = height \times width \times length k=height×width×length,d是通道的数量。平均池化可以数学表示为 M = P u s h ( { X n } n = 0 N − 1 ) = P o o l ( { X n W I } n = 0 N − 1 ) , W I ∈ R d × d ′ M=Push(\{X_n\}^{N-1}_{n=0})=Pool(\{X_nW_I\}_{n=0}{N-1}), W_I \in \mathbb{R}^{d \times d^\prime} M=Push({ Xn
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









