



 本文介绍三种SQL查询方法,用于从数据库中找出每个用户的最新借阅记录。包括直接使用聚合函数、子查询及group by结合join的方法,并分析了各自的优缺点。
本文介绍三种SQL查询方法,用于从数据库中找出每个用户的最新借阅记录。包括直接使用聚合函数、子查询及group by结合join的方法,并分析了各自的优缺点。
| 导读 | 日常开发当中,经常会遇到查询分组数据中最新的一条记录,比如统计当前系统每个人的最新登录记录、外卖系统统计所有买家最新的一次订单记录、图书管理系统借阅者最新借阅书籍的记录等等。 |

日常开发当中,经常会遇到查询分组数据中最新的一条记录,比如统计当前系统每个人的最新登录记录、外卖系统统计所有买家最新的一次订单记录、图书管理系统借阅者最新借阅书籍的记录等等。今天给大家介绍一下如何实现以上场景的SQL写法,希望对大家能有所帮助!Linux就该这么学
1、初始化数据表
-- 借阅者表 CREATE TABLE `userinfo` ( `uid` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `uname` varchar(20) NOT NULL COMMENT '姓名', `uage` int(11) NOT NULL COMMENT '年龄', PRIMARY KEY (`uid`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT; INSERT INTO `userinfo` VALUES (1, '小明', 20); INSERT INTO `userinfo` VALUES (2, '小张', 30); INSERT INTO `userinfo` VALUES (3, '小李', 28); -- 书籍表 CREATE TABLE `bookinfo` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `book_no` varchar(20) NOT NULL COMMENT '书籍编号', `book_name` varchar(20) NOT NULL COMMENT '书籍名称', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT; INSERT INTO `bookinfo` VALUES (1, 'ISBN001', '计算机基础'); INSERT INTO `bookinfo` VALUES (2, 'ISBN002', '计算机网络'); INSERT INTO `bookinfo` VALUES (3, 'ISBN003', '高等数学'); INSERT INTO `bookinfo` VALUES (4, 'ISBN004', '明朝那些事'); INSERT INTO `bookinfo` VALUES (5, 'ISBN005', '物理'); INSERT INTO `bookinfo` VALUES (13, 'ISBN006', '读者'); -- 借阅记录表 CREATE TABLE `borrow_record` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `user_id` int(11) NOT NULL COMMENT '用户id', `book_id` int(11) NOT NULL COMMENT '书籍id', `borrowtime` datetime NOT NULL COMMENT '书籍id', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=16 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT; INSERT INTO `borrow_record` VALUES (8, 1, 2, '2021-05-01 10:52:00'); INSERT INTO `borrow_record` VALUES (9, 2, 4, '2021-07-12 23:32:00'); INSERT INTO `borrow_record` VALUES (10, 2, 1, '2021-03-21 09:00:00'); INSERT INTO `borrow_record` VALUES (11, 1, 3, '2021-08-11 17:39:00'); INSERT INTO `borrow_record` VALUES (12, 1, 5, '2021-09-02 18:12:00'); INSERT INTO `borrow_record` VALUES (13, 3, 1, '2021-07-06 12:32:00'); INSERT INTO `borrow_record` VALUES (14, 2, 1, '2021-08-09 10:10:00'); INSERT INTO `borrow_record` VALUES (15, 4, 3, '2021-04-15 19:45:00'
写法1 直接group by 根据userid ,使用聚合函数max取得最近的浏览时间
select a.user_id ,max(c.uname) uname ,max(a.borrowtime) borrowtime,max(b.book_name) book_name from borrow_record a INNER JOIN bookinfo b on b.id=a.book_id INNER JOIN userinfo c on c.uid=a.user_id GROUP BY a.user_id -- 说明: 这样会存在获取书籍名称错乱的情况, -- 因为使用聚合函数获取的书籍名称,不一定是对应用户 -- 最新浏览记录对应的书籍名称
写法2 采用子查询的方式,获取借阅记录表最近的浏览时间作为查询条件
select a.user_id ,c.uname,a.borrowtime ,b.book_name book_namefrom borrow_record a INNER JOIN bookinfo b on b.id=a.book_id INNER JOIN userinfo c on c.uid=a.user_id where a.borrowtime=(select max(borrowtime) from borrow_record t where t.user_id=a.user_id) -- 说明:可以满足查询效果,不过性能不是最优解
写法3 采用group by + join 性能最高,推荐采用
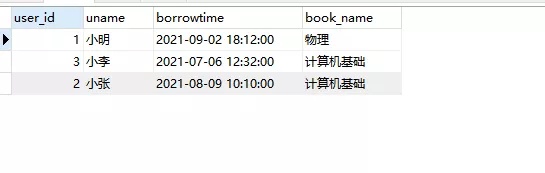
select a.user_id ,c.uname,a.borrowtime ,b.book_name book_namefrom ( select t.user_id,max(borrowtime) borrowtime from borrow_record t GROUP BY t.user_id) as e INNER JOIN borrow_record a on e.user_id=a.user_id and e.borrowtime=a.borrowtimeINNER JOIN bookinfo b on b.id=a.book_id INNER JOIN userinfo c on c.uid=a.user_id
运行效果如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









