 Rust for Linux内核中FFI类型不匹配及辅助函数问题
Rust for Linux内核中FFI类型不匹配及辅助函数问题




关注了就能看到更多这么棒的文章哦~
FFI type mismatches in Rust for Linux
By Daroc Alden
October 11, 2024
Kangrejos 2024
Gemini-1.5-flash translation
https://lwn.net/Articles/993163/
在 Kangrejos 会议上,Gary Guo 讨论了 Rust 和 C 代码在内核中交互时遇到的三个问题:类型不匹配、类型转换过多以及辅助函数的开销。为了解决前两个问题,Guo 提议改变内核将 C 类型映射到 Rust 类型的方式。最后一个问题比较棘手,但他有一个巧妙的解决方法,是在欺骗编译器在语言边界内把辅助函数改成 inline 的基础上实现的。
类型
目前,Rust-for-Linux 项目 使用 bindgen 来生成 C 代码和 Rust 代码之间的绑定。这可以正常工作,但并非所有类型都能完美地转换。Guo 分享了一些 幻灯片 来展示当前整数转换的状态:

简而言之,这个映射很依赖于具体平台,而且不是一对一的。这给试图用一种语言编写调用另一种语言代码的程序员增加了额外的复杂性。此外,一些重要的类型,例如 size_t 和 uintptr_t ,是 C 语言中的 typedef,而不是实际的类型,这使得对应关系更加不清楚。
Carlos Bilbao 询问为什么转换时不能考虑这些 typedef,并将 Rust 的 isize 和 usize 映射到 size_t 和 uintptr_t 解析到的任何类型。Guo 解释说,bindgen 通过读取 C 头文件来工作,由于 C 语言的隐式整数转换,有时不清楚 C 源代码中的 long 应该在 Rust 代码中是 i64 还是 isize 。他继续说,这种混淆最终会导致许多不必要的转换,模糊了代码的含义。不过,bindgen 对 size_t 有一些特殊支持。Greg Kroah-Hartman 指出,在内核 C 代码中使用 long 是有意而为的——没有与 intptr_t 相对应的原生内核类型。事实上,Linux 要求 long 必须能够容纳一个指针。
无论有意还是无意,这些问题意味着 Rust 代码中经常需要类型转换,因为 Rust 没有隐式整数转换。有时,Rust 的代码风格检查工具 clippy 会抱怨多余的转换,但这些转换在不同的架构上并不多余,因为类型之间的映射不同。此外,不同的类型名称会导致控制流完整性 (CFI) 保护的类型标签出现问题,因为类型标签依赖于函数参数的实际类型,而不是它们的大小。最后,内核将 char 定义为无条件无符号的,即使在它通常是有符号的平台上也是如此。Rust 的 c_char 类型遵循架构对符号的约定,因此尝试使用 c_char 来表示 C char 值可能会导致符号问题。
Guo 提议在内核中为 bindgen 采用自定义的固定映射,以尝试缓解其中一些问题:
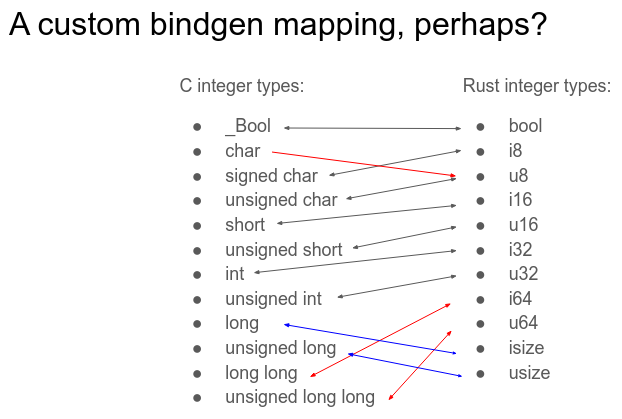
这种改变并不能解决所有问题,仍然有一些极端情况。除了其他问题之外,这种映射对于 CHERI 系统仍然不起作用。但总的来说,拥有一个跨架构一致的映射应该会让思考这些代码变得不那么痛苦。
Kroah-Hartman 质疑将 u8 映射回 unsigned char 而不是 char 的决定,因为内核将 char 定义为始终是无符号的。不幸的是,C 标准对不同的 char 类型有一些奇怪的措辞,即使使用 -funsigned-char,编译器仍然将 char 和 unsigned char 视为不同的类型(具有略微不同的语义)。
辅助函数
Guo 希望解决的另一个问题是,Rust-for-Linux 项目如何包装 C 宏和内联函数所带来的效率问题。Bindgen 无法直接将 C 宏整合到 Rust 代码中,原因很明显。因此,当 Rust 代码需要使用 C 中定义的宏时,程序员会为它编写一个显式的包装函数。相同的解决方法适用于内联函数。这避免了在两种语言中重复宏,但存在严重的性能下降。内联函数通常用在操作对性能非常敏感,以至于一次函数调用都太多了的情况下;因此,从 Rust 代码中调用它们时添加辅助函数是一个问题。
Guo 列举了一些可能的替代方案。一种方案是改变禁止在 Rust 中重新实现宏的策略。虽然这在内核维护人员中不受欢迎,但对于最注重性能的案例来说可能值得一试。另一个可以探索的选项是使用 c2rust 将 C 宏转换为 Rust 代码。不幸的是,c2rust 太大,无法包含在内核存储库中,没有被任何发行版打包,而且很脆弱,需要 nightly Rust。Guo 不认为这是一个合理的选择。他提出的最后一个可能性是跨语言链接时优化 (LTO)。这将使编译器能够在链接时自动跨语言边界内联辅助函数,从而大幅减少性能影响。缺点是 LTO 很慢,有时会导致内核构建失败。
Andreas Hindborg 建议直接对 Rust 模块执行 LTO 速度更快。Guo 同意,并指出该项目实际上并不需要完整的 LTO 来消除辅助函数的开销,只需将辅助函数内联到 Rust 调用站点即可。这类似于 Rust 发布构建的默认行为,它使用 ThinLTO。
为了说明这个想法,Guo 做了一个 ""hack""。他的想法是使用 Clang 将 helpers.c 编译成 LLVM 字节码。然后,对于每个 Rust crate,要求编译器也输出字节码。一旦所有内容都以 LLVM 字节码的形式存在,就可以将其重新输入 Clang,并开启 LTO 以生成一个包含内联辅助函数的组合目标文件。这不是保证,因为 Clang 可能会选择不进行内联,但它应该有助于提高性能。Guo 在现有的 Rust 内核代码中进行了尝试,发现这种方法确实生成了有效目标文件,但 block 层揭示了另一个问题。
这种方法的主要问题是将生成的目标文件链接回内核。如果目标文件按正常方式链接,就会出现来自每个辅助函数独立副本的重复符号。一个可能的解决方案是使用不同的链接方式。LLVM 支持非标准的 weak_odr 链接,以便正确处理 C++ 的单定义规则。但是这种类型的链接目前无法从 C 代码生成。Paul McKenney 问在这种情况下,是否应该尝试用 C++ 编译辅助函数文件。Guo 指出,这需要内核支持 C++。
然而,他确实有另一种解决方法可以尝试:在生成 LLVM 字节码文件后,对它进行文本修改,添加适当的属性。然而,当他尝试这样做时,LLVM 就不再内联辅助函数了。事实证明,LLVM 有两个检查可以阻止它内联函数:一个检查是两个字节码片段的目标属性是否匹配,另一个检查是它们的 -fno-delete-null-pointer-check 设置是否相同。Guo 提议向 LLVM 传递一个标志来忽略前一个检查,并更改编译标志以避免后一个检查。
有了所有这些更改之后"一切正常"——但你确实需要使用相同 LLVM 版本的 Clang 和 Rust。函数被内联,符号不会导致链接错误,并且它适用于内置模块和加载模块。Hindborg 对其进行了测试,并报告了速度提升了百分之几,Guo 说。他还建议,有了这些工具,甚至可以自动生成必要的辅助函数,这将很方便。
Carlos Bilbao 问是否有无法使用这种方法的情况,即无法内联辅助函数。Guo 回复说没有——不应该内联的函数根本不需要包装在辅助函数中。
Miguel Ojeda 询问如何使用这种方法支持 GCC。Guo 说一定有解决方法,因为 GCC 也需要支持 C++ 的单定义规则。但是与 LLVM 不同,GCC 并不方便保存和编辑 GIMPLE(GCC 的中间表示)。Boqun Feng 建议使用 GCC 编译内核,只使用 Clang 编译 helpers.c。Guo 解释说,这样做行不通,因为 GCC 和 Clang 使用不同的标志。Bindgen 实际上有一些支持将它们转换为另一种语言的支持,但要确保链接后的目标文件没有问题会很困难。
几位听众提出了更多关于如何将 Guo 的方法与 GCC 一起使用的建议,但会议在找到任何可操作性强的方案之前就结束了。目前尚不清楚他的方法有多稳定,但百分之几的性能提升肯定会让人们继续研究它。无论如何,Rust 和 C 代码在内核中的接口是一个引起人们极大兴趣的领域,而且很可能在相当长一段时间内都将如此。
全文完
LWN 文章遵循 CC BY-SA 4.0 许可协议。
欢迎分享、转载及基于现有协议再创作~
长按下面二维码关注,关注 LWN 深度文章以及开源社区的各种新近言论~


















 3196
3196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









